 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Augment via Implicit Differentiation for Domain Generalization
Oct 25, 2022Machine learning models are intrinsically vulnerable to domain shift between training and testing data, resulting in poor performance in novel domains. Domain generalization (DG) aims to overcome the problem by leveraging multiple source domains to learn a domain-generalizable model. In this paper, we propose a novel augmentation-based DG approach, dubbed AugLearn. Different from existing data augmentation methods, our AugLearn views a data augmentation module as hyper-parameters of a classification model and optimizes the module together with the model via meta-learning. Specifically, at each training step, AugLearn (i) divides source domains into a pseudo source and a pseudo target set, and (ii) trains the augmentation module in such a way that the augmented (synthetic) images can make the model generalize well on the pseudo target set. Moreover, to overcome the expensive second-order gradient computation during meta-learning, we formulate an efficient joint training algorithm, for both the augmentation module and the classification model, based on the implicit function theorem. With the flexibility of augmenting data in both time and frequency spaces, AugLearn shows effectiveness on three standard DG benchmarks, PACS, Office-Home and Digits-DG.
Prediction Calibration for Generalized Few-shot Semantic Segmentation
Oct 15, 2022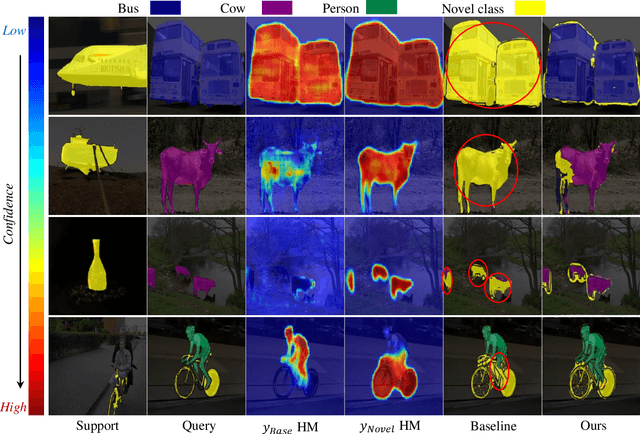
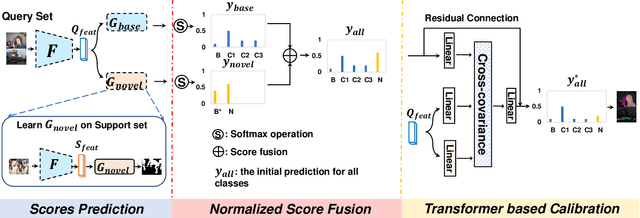

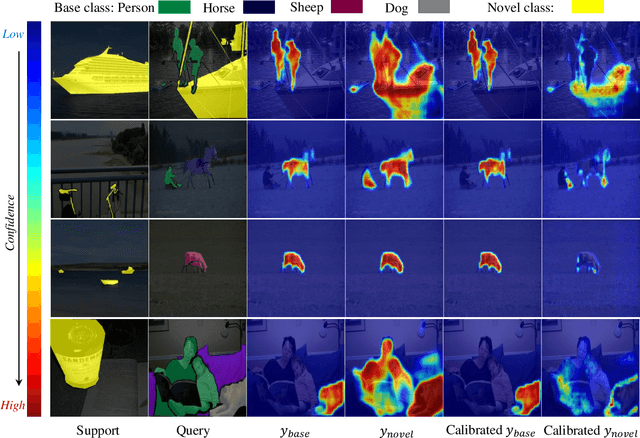
Generalized Few-shot Semantic Segmentation (GFSS) aims to segment each image pixel into either base classes with abundant training examples or novel classes with only a handful of (e.g., 1-5) training images per class. Compared to the widely studied Few-shot Semantic Segmentation FSS, which is limited to segmenting novel classes only, GFSS is much under-studied despite being more practical. Existing approach to GFSS is based on classifier parameter fusion whereby a newly trained novel class classifier and a pre-trained base class classifier are combined to form a new classifier. As the training data is dominated by base classes, this approach is inevitably biased towards the base classes. In this work, we propose a novel Prediction Calibration Network PCN to address this problem. Instead of fusing the classifier parameters, we fuse the scores produced separately by the base and novel classifiers. To ensure that the fused scores are not biased to either the base or novel classes, a new Transformer-based calibration module is introduced. It is known that the lower-level features are useful of detecting edge information in an input image than higher-level features. Thus, we build a cross-attention module that guides the classifier's final prediction using the fused multi-level features. However, transformers are computationally demanding. Crucially, to make the proposed cross-attention module training tractable at the pixel level, this module is designed based on feature-score cross-covariance and episodically trained to be generalizable at inference time. Extensive experiments on PASCAL-$5^{i}$ and COCO-$20^{i}$ show that our PCN outperforms the state-the-the-art alternatives by large margins.
Robust Target Training for Multi-Source Domain Adaptation
Oct 04, 2022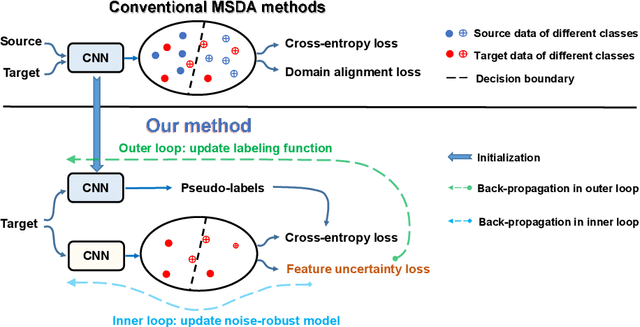

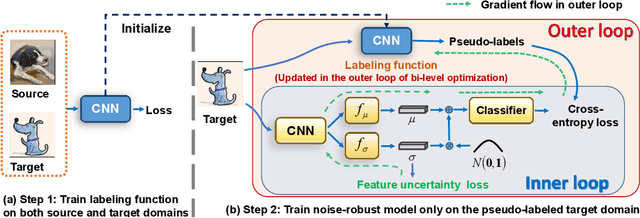

Given multiple labeled source domains and a single target domain, most existing multi-source domain adaptation (MSDA) models are trained on data from all domains jointly in one step. Such an one-step approach limits their ability to adapt to the target domain. This is because the training set is dominated by the more numerous and labeled source domain data. The source-domain-bias can potentially be alleviated by introducing a second training step, where the model is fine-tuned with the unlabeled target domain data only using pseudo labels as supervision. However, the pseudo labels are inevitably noisy and when used unchecked can negatively impact the model performance. To address this problem, we propose a novel Bi-level Optimization based Robust Target Training (BORT$^2$) method for MSDA. Given any existing fully-trained one-step MSDA model, BORT$^2$ turns it to a labeling function to generate pseudo-labels for the target data and trains a target model using pseudo-labeled target data only. Crucially, the target model is a stochastic CNN which is designed to be intrinsically robust against label noise generated by the labeling function. Such a stochastic CNN models each target instance feature as a Gaussian distribution with an entropy maximization regularizer deployed to measure the label uncertainty, which is further exploited to alleviate the negative impact of noisy pseudo labels. Training the labeling function and the target model poses a nested bi-level optimization problem, for which we formulate an elegant solution based on implicit differentiation. Extensive experiments demonstrate that our proposed method achieves the state of the art performance on three MSDA benchmarks, including the large-scale DomainNet dataset. Our code will be available at \url{https://github.com/Zhongying-Deng/BORT2}
Towards 3D VR-Sketch to 3D Shape Retrieval
Sep 20, 2022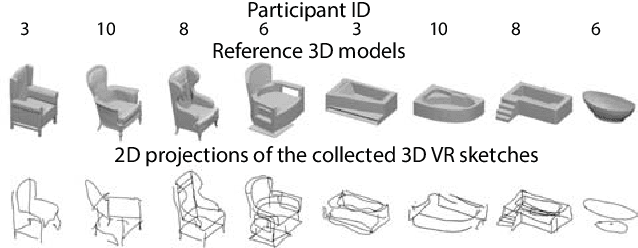
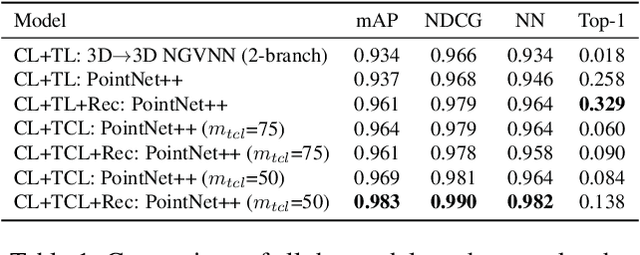

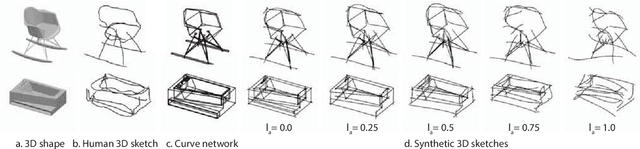
Growing free online 3D shapes collections dictated research on 3D retrieval. Active debate has however been had on (i) what the best input modality is to trigger retrieval, and (ii) the ultimate usage scenario for such retrieval. In this paper, we offer a different perspective towards answering these questions -- we study the use of 3D sketches as an input modality and advocate a VR-scenario where retrieval is conducted. Thus, the ultimate vision is that users can freely retrieve a 3D model by air-doodling in a VR environment. As a first stab at this new 3D VR-sketch to 3D shape retrieval problem, we make four contributions. First, we code a VR utility to collect 3D VR-sketches and conduct retrieval. Second, we collect the first set of $167$ 3D VR-sketches on two shape categories from ModelNet. Third, we propose a novel approach to generate a synthetic dataset of human-like 3D sketches of different abstract levels to train deep networks. At last, we compare the common multi-view and volumetric approaches: We show that, in contrast to 3D shape to 3D shape retrieval, volumetric point-based approaches exhibit superior performance on 3D sketch to 3D shape retrieval due to the sparse and abstract nature of 3D VR-sketches. We believe these contributions will collectively serve as enablers for future attempts at this problem. The VR interface, code and datasets are available at https://tinyurl.com/3DSketch3DV.
Fine-Grained VR Sketching: Dataset and Insights
Sep 20, 2022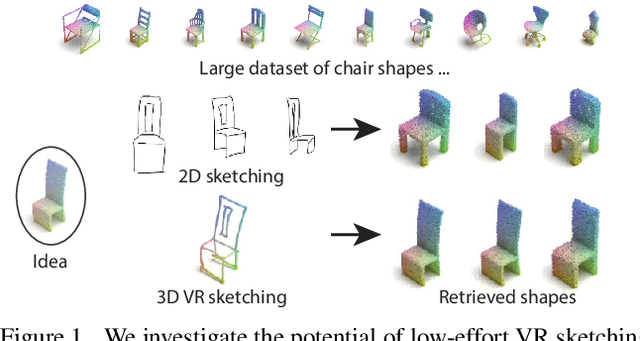
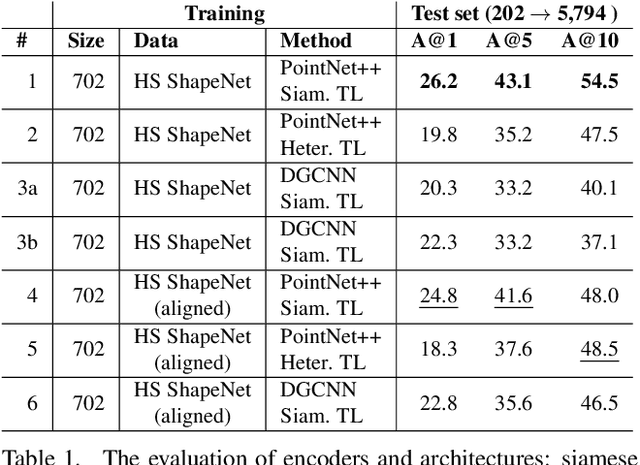
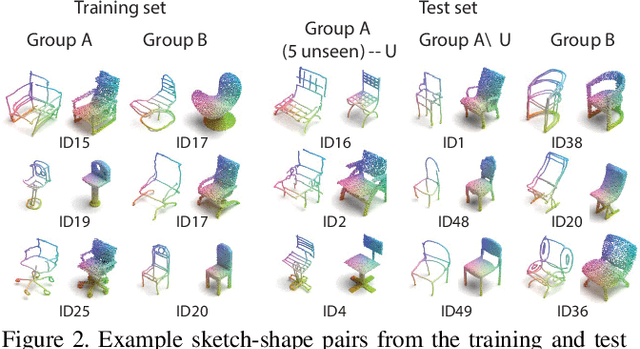
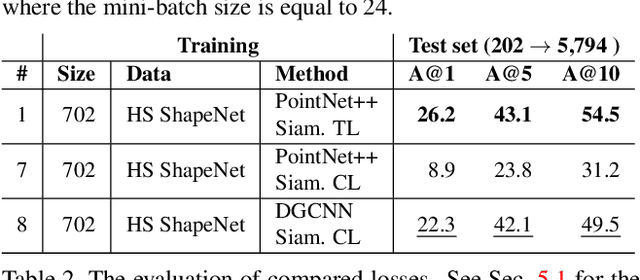
We present the first fine-grained dataset of 1,497 3D VR sketch and 3D shape pairs of a chair category with large shapes diversity. Our dataset supports the recent trend in the sketch community on fine-grained data analysis, and extends it to an actively developing 3D domain. We argue for the most convenient sketching scenario where the sketch consists of sparse lines and does not require any sketching skills, prior training or time-consuming accurate drawing. We then, for the first time, study the scenario of fine-grained 3D VR sketch to 3D shape retrieval, as a novel VR sketching application and a proving ground to drive out generic insights to inform future research. By experimenting with carefully selected combinations of design factors on this new problem, we draw important conclusions to help follow-on work. We hope our dataset will enable other novel applications, especially those that require a fine-grained angle such as fine-grained 3D shape reconstruction. The dataset is available at tinyurl.com/VRSketch3DV21.
Structure-Aware 3D VR Sketch to 3D Shape Retrieval
Sep 19, 2022

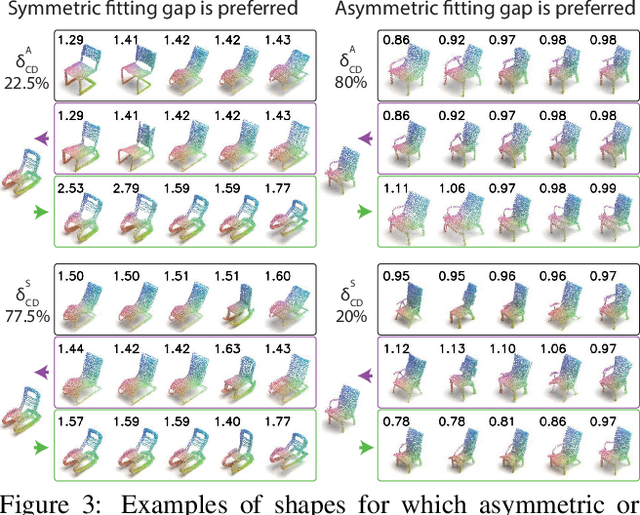
We study the practical task of fine-grained 3D-VR-sketch-based 3D shape retrieval. This task is of particular interest as 2D sketches were shown to be effective queries for 2D images. However, due to the domain gap, it remains hard to achieve strong performance in 3D shape retrieval from 2D sketches. Recent work demonstrated the advantage of 3D VR sketching on this task. In our work, we focus on the challenge caused by inherent inaccuracies in 3D VR sketches. We observe that retrieval results obtained with a triplet loss with a fixed margin value, commonly used for retrieval tasks, contain many irrelevant shapes and often just one or few with a similar structure to the query. To mitigate this problem, we for the first time draw a connection between adaptive margin values and shape similarities. In particular, we propose to use a triplet loss with an adaptive margin value driven by a "fitting gap", which is the similarity of two shapes under structure-preserving deformations. We also conduct a user study which confirms that this fitting gap is indeed a suitable criterion to evaluate the structural similarity of shapes. Furthermore, we introduce a dataset of 202 VR sketches for 202 3D shapes drawn from memory rather than from observation. The code and data are available at https://github.com/Rowl1ng/Structure-Aware-VR-Sketch-Shape-Retrieval.
Negative Frames Matter in Egocentric Visual Query 2D Localization
Aug 03, 2022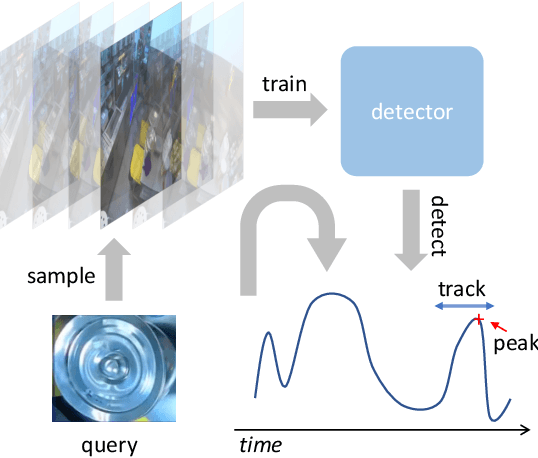

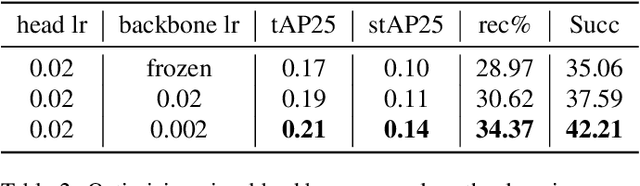
The recently released Ego4D dataset and benchmark significantly scales and diversifies the first-person visual perception data. In Ego4D, the Visual Queries 2D Localization task aims to retrieve objects appeared in the past from the recording in the first-person view. This task requires a system to spatially and temporally localize the most recent appearance of a given object query, where query is registered by a single tight visual crop of the object in a different scene. Our study is based on the three-stage baseline introduced in the Episodic Memory benchmark. The baseline solves the problem by detection and tracking: detect the similar objects in all the frames, then run a tracker from the most confident detection result. In the VQ2D challenge, we identified two limitations of the current baseline. (1) The training configuration has redundant computation. Although the training set has millions of instances, most of them are repetitive and the number of unique object is only around 14.6k. The repeated gradient computation of the same object lead to an inefficient training; (2) The false positive rate is high on background frames. This is due to the distribution gap between training and evaluation. During training, the model is only able to see the clean, stable, and labeled frames, but the egocentric videos also have noisy, blurry, or unlabeled background frames. To this end, we developed a more efficient and effective solution. Concretely, we bring the training loop from ~15 days to less than 24 hours, and we achieve 0.17% spatial-temporal AP, which is 31% higher than the baseline. Our solution got the first ranking on the public leaderboard. Our code is publicly available at https://github.com/facebookresearch/vq2d_cvpr.
Visual Representation Learning with Transformer: A Sequence-to-Sequence Perspective
Jul 19, 2022Visual representation learning is the key of solving various vision problems. Relying on the seminal grid structure priors, convolutional neural networks (CNNs) have been the de facto standard architectures of most deep vision models. For instance, classical semantic segmentation methods often adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated (i.e., atrous) convolutions or inserting attention modules. However, the FCN-based architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating visual representation learning generally as a sequence-to-sequence prediction task. Specifically, we deploy a pure Transformer to encode an image as a sequence of patches, without local convolution and resolution reduction. With the global context modeled in every layer of the Transformer, stronger visual representation can be learned for better tackling vision tasks. In particular, our segmentation model, termed as SEgmentation TRansformer (SETR), excels on ADE20K (50.28% mIoU, the first position in the test leaderboard on the day of submission), Pascal Context (55.83% mIoU) and reaches competitive results on Cityscapes. Further, we formulate a family of Hierarchical Local-Global (HLG) Transformers characterized by local attention within windows and global-attention across windows in a hierarchical and pyramidal architecture. Extensive experiments show that our method achieves appealing performance on a variety of visual recognition tasks (e.g., image classification, object detection and instance segmentation and semantic segmentation).
Zero-Shot Temporal Action Detection via Vision-Language Prompting
Jul 17, 2022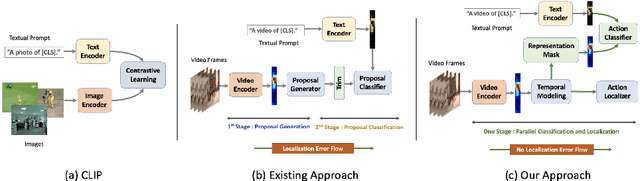
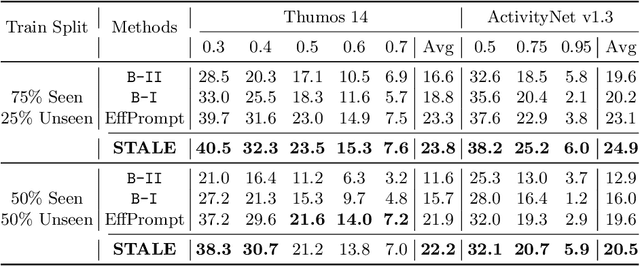
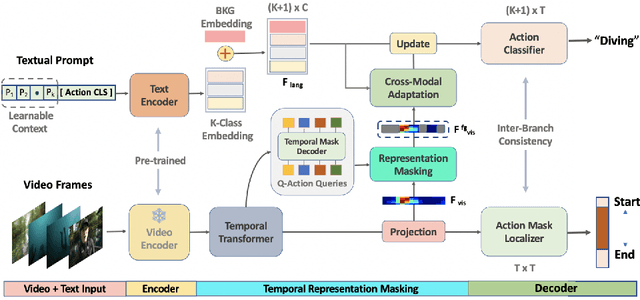
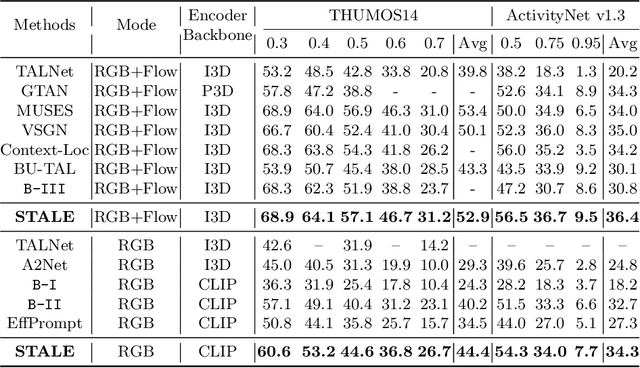
Existing temporal action detection (TAD) methods rely on large training data including segment-level annotations, limited to recognizing previously seen classes alone during inference. Collecting and annotating a large training set for each class of interest is costly and hence unscalable. Zero-shot TAD (ZS-TAD) resolves this obstacle by enabling a pre-trained model to recognize any unseen action classes. Meanwhile, ZS-TAD is also much more challenging with significantly less investigation. Inspired by the success of zero-shot image classification aided by vision-language (ViL) models such as CLIP, we aim to tackle the more complex TAD task. An intuitive method is to integrate an off-the-shelf proposal detector with CLIP style classification. However, due to the sequential localization (e.g, proposal generation) and classification design, it is prone to localization error propagation. To overcome this problem, in this paper we propose a novel zero-Shot Temporal Action detection model via Vision-LanguagE prompting (STALE). Such a novel design effectively eliminates the dependence between localization and classification by breaking the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for improved optimization. Extensive experiments on standard ZS-TAD video benchmarks show that our STALE significantly outperforms state-of-the-art alternatives. Besides, our model also yields superior results on supervised TAD over recent strong competitors. The PyTorch implementation of STALE is available at https://github.com/sauradip/STALE.
FashionViL: Fashion-Focused Vision-and-Language Representation Learning
Jul 17, 2022

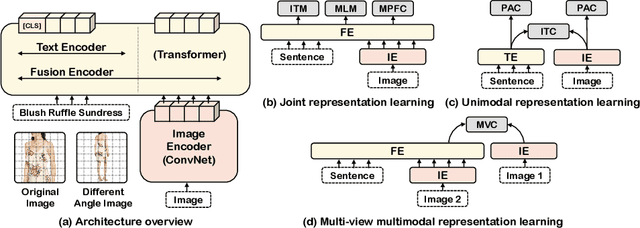
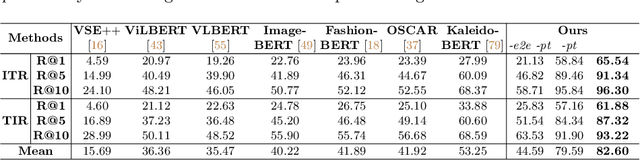
Large-scale Vision-and-Language (V+L) pre-training for representation learning has proven to be effective in boosting various downstream V+L tasks. However, when it comes to the fashion domain, existing V+L methods are inadequate as they overlook the unique characteristics of both the fashion V+L data and downstream tasks. In this work, we propose a novel fashion-focused V+L representation learning framework, dubbed as FashionViL. It contains two novel fashion-specific pre-training tasks designed particularly to exploit two intrinsic attributes with fashion V+L data. First, in contrast to other domains where a V+L data point contains only a single image-text pair, there could be multiple images in the fashion domain. We thus propose a Multi-View Contrastive Learning task for pulling closer the visual representation of one image to the compositional multimodal representation of another image+text. Second, fashion text (e.g., product description) often contains rich fine-grained concepts (attributes/noun phrases). To exploit this, a Pseudo-Attributes Classification task is introduced to encourage the learned unimodal (visual/textual) representations of the same concept to be adjacent. Further, fashion V+L tasks uniquely include ones that do not conform to the common one-stream or two-stream architectures (e.g., text-guided image retrieval). We thus propose a flexible, versatile V+L model architecture consisting of a modality-agnostic Transformer so that it can be flexibly adapted to any downstream tasks. Extensive experiments show that our FashionViL achieves a new state of the art across five downstream tasks. Code is available at https://github.com/BrandonHanx/mmf.