 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Long Way to Go: Investigating Length Correlations in RLHF
Oct 05, 2023



Great successes have been reported using Reinforcement Learning from Human Feedback (RLHF) to align large language models. Open-source preference datasets and reward models have enabled wider experimentation beyond generic chat settings, particularly to make systems more "helpful" for tasks like web question answering, summarization, and multi-turn dialogue. When optimizing for helpfulness, RLHF has been consistently observed to drive models to produce longer outputs. This paper demonstrates that optimizing for response length is a significant factor behind RLHF's reported improvements in these settings. First, we study the relationship between reward and length for reward models trained on three open-source preference datasets for helpfulness. Here, length correlates strongly with reward, and improvements in reward score are driven in large part by shifting the distribution over output lengths. We then explore interventions during both RL and reward model learning to see if we can achieve the same downstream improvements as RLHF without increasing length. While our interventions mitigate length increases, they aren't uniformly effective across settings. Furthermore, we find that even running RLHF with a reward based solely on length can reproduce most of the downstream improvements over the initial policy model, showing that reward models in these settings have a long way to go.
WiCE: Real-World Entailment for Claims in Wikipedia
Mar 02, 2023



Models for textual entailment have increasingly been applied to settings like fact-checking, presupposition verification in question answering, and validating that generation models' outputs are faithful to a source. However, such applications are quite far from the settings that existing datasets are constructed in. We propose WiCE, a new textual entailment dataset centered around verifying claims in text, built on real-world claims and evidence in Wikipedia with fine-grained annotations. We collect sentences in Wikipedia that cite one or more webpages and annotate whether the content on those pages entails those sentences. Negative examples arise naturally, from slight misinterpretation of text to minor aspects of the sentence that are not attested in the evidence. Our annotations are over sub-sentence units of the hypothesis, decomposed automatically by GPT-3, each of which is labeled with a subset of evidence sentences from the source document. We show that real claims in our dataset involve challenging verification problems, and we benchmark existing approaches on this dataset. In addition, we show that reducing the complexity of claims by decomposing them by GPT-3 can improve entailment models' performance on various domains.
Shortcomings of Question Answering Based Factuality Frameworks for Error Localization
Oct 13, 2022
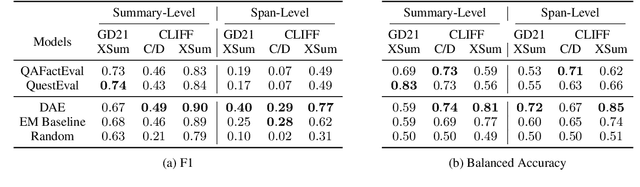

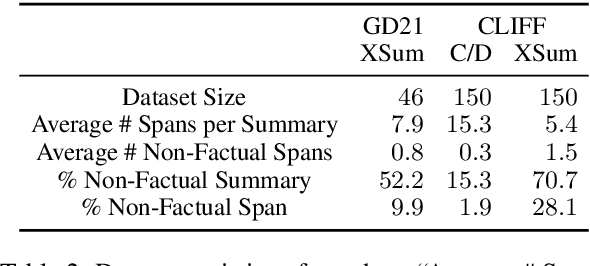
Despite recent progress in abstractive summarization, models often generate summaries with factual errors. Numerous approaches to detect these errors have been proposed, the most popular of which are question answering (QA)-based factuality metrics. These have been shown to work well at predicting summary-level factuality and have potential to localize errors within summaries, but this latter capability has not been systematically evaluated in past research. In this paper, we conduct the first such analysis and find that, contrary to our expectations, QA-based frameworks fail to correctly identify error spans in generated summaries and are outperformed by trivial exact match baselines. Our analysis reveals a major reason for such poor localization: questions generated by the QG module often inherit errors from non-factual summaries which are then propagated further into downstream modules. Moreover, even human-in-the-loop question generation cannot easily offset these problems. Our experiments conclusively show that there exist fundamental issues with localization using the QA framework which cannot be fixed solely by stronger QA and QG models.
News Summarization and Evaluation in the Era of GPT-3
Sep 26, 2022
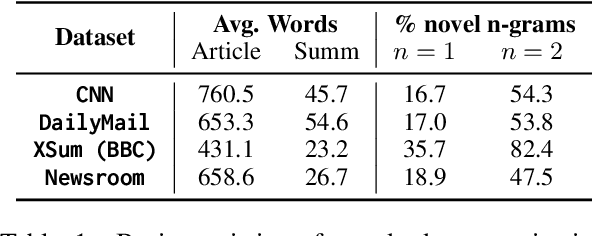
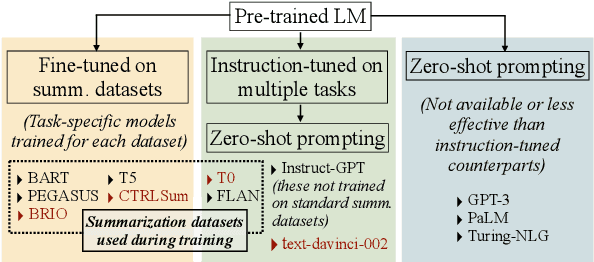
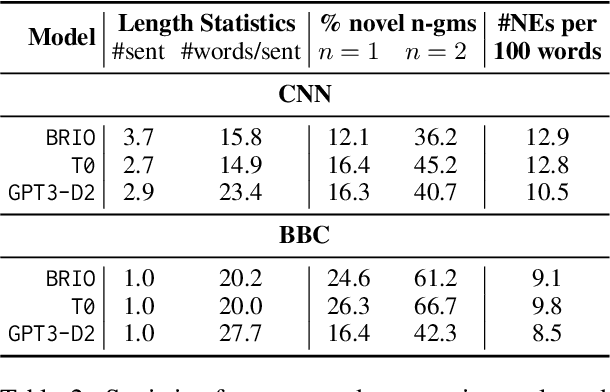
The recent success of zero- and few-shot prompting with models like GPT-3 has led to a paradigm shift in NLP research. In this paper, we study its impact on text summarization, focusing on the classic benchmark domain of news summarization. First, we investigate how zero-shot GPT-3 compares against fine-tuned models trained on large summarization datasets. We show that not only do humans overwhelmingly prefer GPT-3 summaries, but these also do not suffer from common dataset-specific issues such as poor factuality. Next, we study what this means for evaluation, particularly the role of gold standard test sets. Our experiments show that both reference-based and reference-free automatic metrics, e.g. recently proposed QA- or entailment-based factuality approaches, cannot reliably evaluate zero-shot summaries. Finally, we discuss future research challenges beyond generic summarization, specifically, keyword- and aspect-based summarization, showing how dominant fine-tuning approaches compare to zero-shot prompting. To support further research, we release: (a) a corpus of 10K generated summaries from fine-tuned and zero-shot models across 4 standard summarization benchmarks, (b) 1K human preference judgments and rationales comparing different systems for generic- and keyword-based summarization.
Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors
May 25, 2022
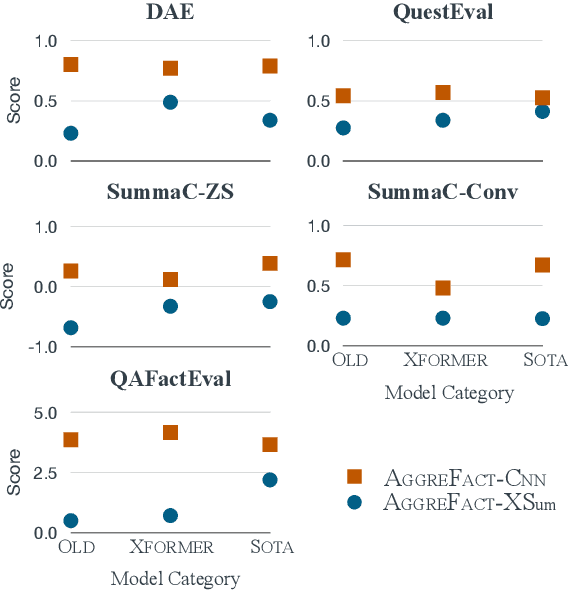
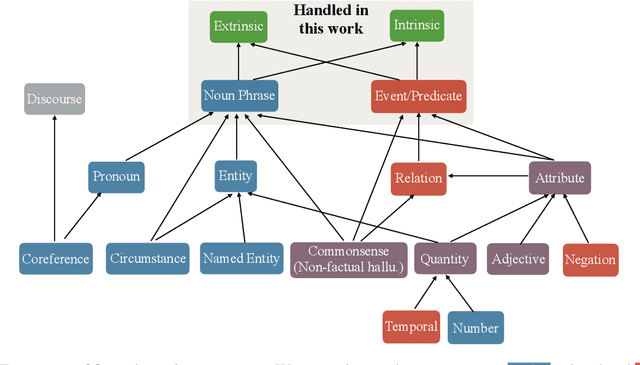
The propensity of abstractive summarization systems to make factual errors has been the subject of significant study, including work on models to detect factual errors and annotation of errors in current systems' outputs. However, the ever-evolving nature of summarization systems, error detectors, and annotated benchmarks make factuality evaluation a moving target; it is hard to get a clear picture of how techniques compare. In this work, we collect labeled factuality errors from across nine datasets of annotated summary outputs and stratify them in a new way, focusing on what kind of base summarization model was used. To support finer-grained analysis, we unify the labeled error types into a single taxonomy and project each of the datasets' errors into this shared labeled space. We then contrast five state-of-the-art error detection methods on this benchmark. Our findings show that benchmarks built on modern summary outputs (those from pre-trained models) show significantly different results than benchmarks using pre-Transformer models. Furthermore, no one factuality technique is superior in all settings or for all error types, suggesting that system developers should take care to choose the right system for their task at hand.
SNaC: Coherence Error Detection for Narrative Summarization
May 19, 2022
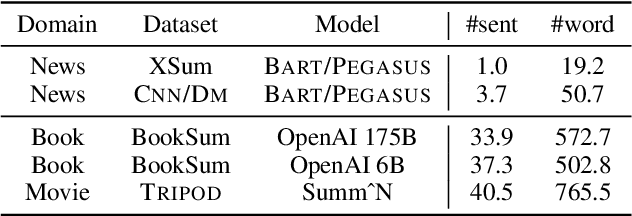

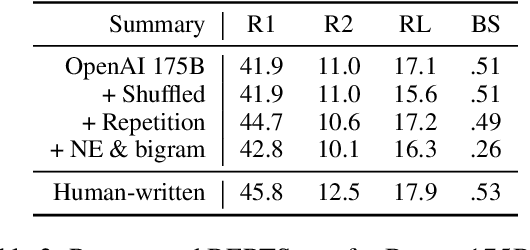
Progress in summarizing long texts is inhibited by the lack of appropriate evaluation frameworks. When a long summary must be produced to appropriately cover the facets of that text, that summary needs to present a coherent narrative to be understandable by a reader, but current automatic and human evaluation methods fail to identify gaps in coherence. In this work, we introduce SNaC, a narrative coherence evaluation framework rooted in fine-grained annotations for long summaries. We develop a taxonomy of coherence errors in generated narrative summaries and collect span-level annotations for 6.6k sentences across 150 book and movie screenplay summaries. Our work provides the first characterization of coherence errors generated by state-of-the-art summarization models and a protocol for eliciting coherence judgments from crowd annotators. Furthermore, we show that the collected annotations allow us to train a strong classifier for automatically localizing coherence errors in generated summaries as well as benchmarking past work in coherence modeling. Finally, our SNaC framework can support future work in long document summarization and coherence evaluation, including improved summarization modeling and post-hoc summary correction.
HydraSum: Disentangling Stylistic Features in Text Summarization using Multi-Decoder Models
Nov 03, 2021
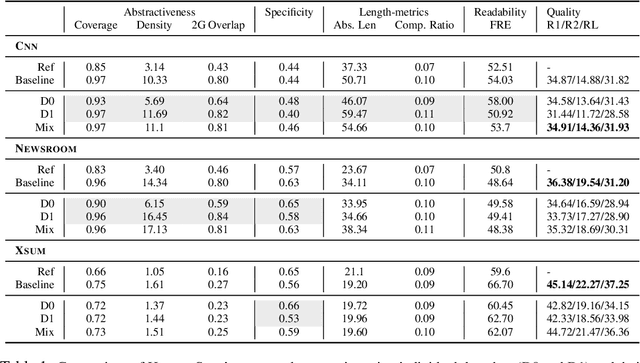
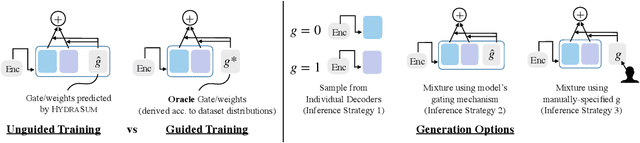

Existing abstractive summarization models lack explicit control mechanisms that would allow users to influence the stylistic features of the model outputs. This results in generating generic summaries that do not cater to the users needs or preferences. To address this issue we introduce HydraSum, a new summarization architecture that extends the single decoder framework of current models, e.g. BART, to a mixture-of-experts version consisting of multiple decoders. Our proposed model encourages each expert, i.e. decoder, to learn and generate stylistically-distinct summaries along dimensions such as abstractiveness, length, specificity, and others. At each time step, HydraSum employs a gating mechanism that decides the contribution of each individual decoder to the next token's output probability distribution. Through experiments on three summarization datasets (CNN, Newsroom, XSum), we demonstrate that this gating mechanism automatically learns to assign contrasting summary styles to different HydraSum decoders under the standard training objective without the need for additional supervision. We further show that a guided version of the training process can explicitly govern which summary style is partitioned between decoders, e.g. high abstractiveness vs. low abstractiveness or high specificity vs. low specificity, and also increase the stylistic-difference between individual decoders. Finally, our experiments demonstrate that our decoder framework is highly flexible: during inference, we can sample from individual decoders or mixtures of different subsets of the decoders to yield a diverse set of summaries and enforce single- and multi-style control over summary generation.
Training Dynamics for Text Summarization Models
Oct 15, 2021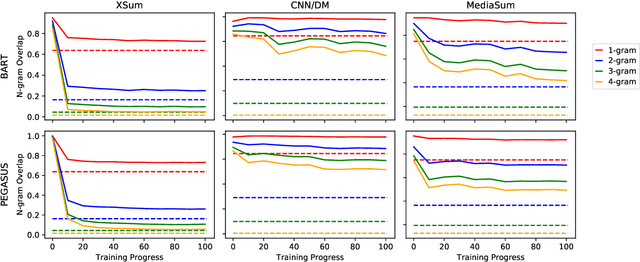
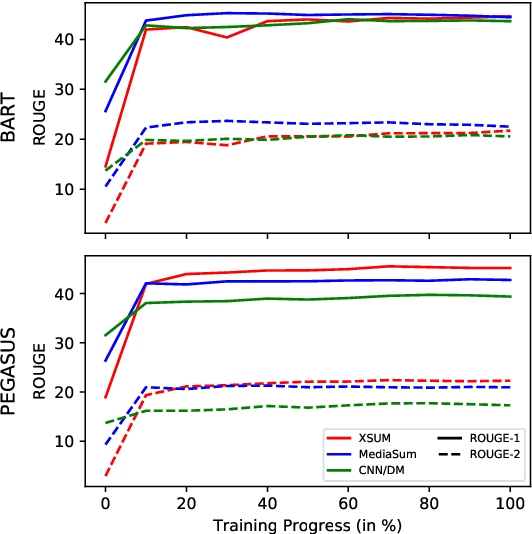
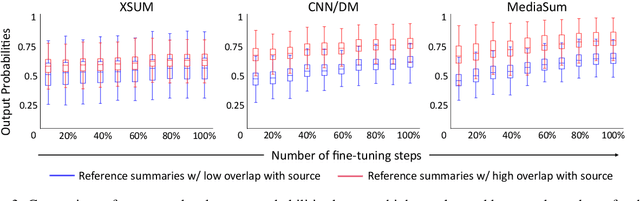
Pre-trained language models (e.g. BART) have shown impressive results when fine-tuned on large summarization datasets. However, little is understood about this fine-tuning process, including what knowledge is retained from pre-training models or how content selection and generation strategies are learnt across iterations. In this work, we analyze the training dynamics for generation models, focusing on news summarization. Across different datasets (CNN/DM, XSum, MediaSum) and summary properties, such as abstractiveness and hallucination, we study what the model learns at different stages of its fine-tuning process. We find that properties such as copy behavior are learnt earlier in the training process and these observations are robust across domains. On the other hand, factual errors, such as hallucination of unsupported facts, are learnt in the later stages, and this behavior is more varied across domains. Based on these observations, we explore complementary approaches for modifying training: first, disregarding high-loss tokens that are challenging to learn and second, disregarding low-loss tokens that are learnt very quickly. This simple training modification allows us to configure our model to achieve different goals, such as improving factuality or improving abstractiveness.
Annotating and Modeling Fine-grained Factuality in Summarization
Apr 09, 2021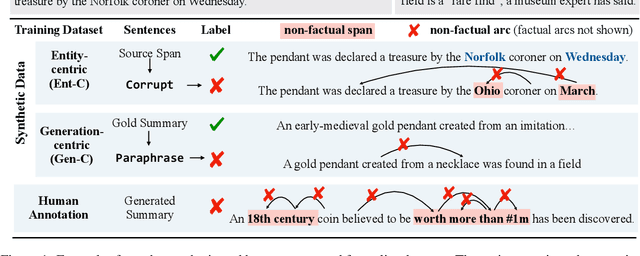
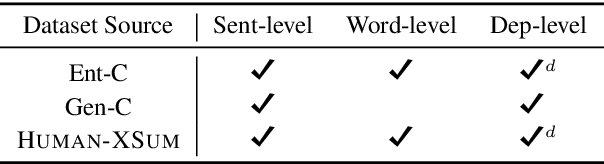
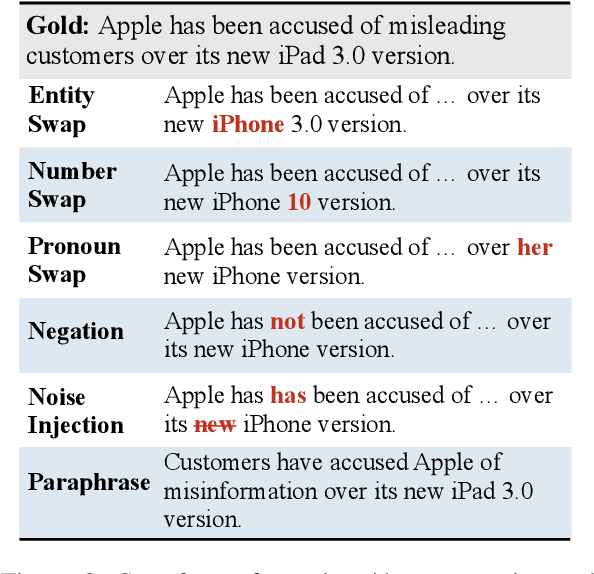
Recent pre-trained abstractive summarization systems have started to achieve credible performance, but a major barrier to their use in practice is their propensity to output summaries that are not faithful to the input and that contain factual errors. While a number of annotated datasets and statistical models for assessing factuality have been explored, there is no clear picture of what errors are most important to target or where current techniques are succeeding and failing. We explore both synthetic and human-labeled data sources for training models to identify factual errors in summarization, and study factuality at the word-, dependency-, and sentence-level. Our observations are threefold. First, exhibited factual errors differ significantly across datasets, and commonly-used training sets of simple synthetic errors do not reflect errors made on abstractive datasets like XSum. Second, human-labeled data with fine-grained annotations provides a more effective training signal than sentence-level annotations or synthetic data. Finally, we show that our best factuality detection model enables training of more factual XSum summarization models by allowing us to identify non-factual tokens in the training data.
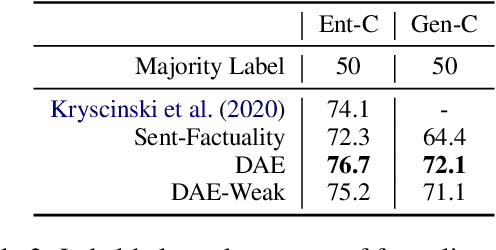
Evaluating Factuality in Generation with Dependency-level Entailment
Oct 22, 2020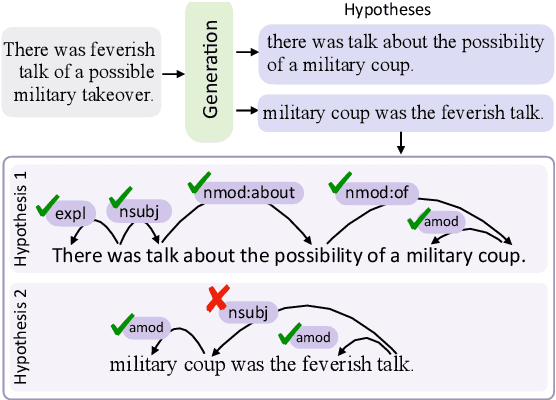

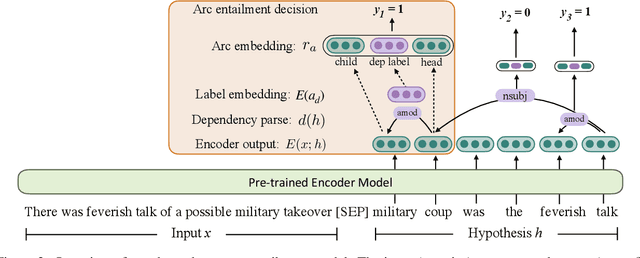

Despite significant progress in text generation models, a serious limitation is their tendency to produce text that is factually inconsistent with information in the input. Recent work has studied whether textual entailment systems can be used to identify factual errors; however, these sentence-level entailment models are trained to solve a different problem than generation filtering and they do not localize which part of a generation is non-factual. In this paper, we propose a new formulation of entailment that decomposes it at the level of dependency arcs. Rather than focusing on aggregate decisions, we instead ask whether the semantic relationship manifested by individual dependency arcs in the generated output is supported by the input. Human judgments on this task are difficult to obtain; we therefore propose a method to automatically create data based on existing entailment or paraphrase corpora. Experiments show that our dependency arc entailment model trained on this data can identify factual inconsistencies in paraphrasing and summarization better than sentence-level methods or those based on question generation, while additionally localizing the erroneous parts of the generation.