 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatum-wise Transformer for Synthetic Tabular Data Detection in the Wild
Apr 10, 2025The growing power of generative models raises major concerns about the authenticity of published content. To address this problem, several synthetic content detection methods have been proposed for uniformly structured media such as image or text. However, little work has been done on the detection of synthetic tabular data, despite its importance in industry and government. This form of data is complex to handle due to the diversity of its structures: the number and types of the columns may vary wildly from one table to another. We tackle the tough problem of detecting synthetic tabular data ''in the wild'', i.e. when the model is deployed on table structures it has never seen before. We introduce a novel datum-wise transformer architecture and show that it outperforms existing models. Furthermore, we investigate the application of domain adaptation techniques to enhance the effectiveness of our model, thereby providing a more robust data-forgery detection solution.
Synthetic Tabular Data Detection In the Wild
Mar 03, 2025



Detecting synthetic tabular data is essential to prevent the distribution of false or manipulated datasets that could compromise data-driven decision-making. This study explores whether synthetic tabular data can be reliably identified across different tables. This challenge is unique to tabular data, where structures (such as number of columns, data types, and formats) can vary widely from one table to another. We propose four table-agnostic detectors combined with simple preprocessing schemes that we evaluate on six evaluation protocols, with different levels of ''wildness''. Our results show that cross-table learning on a restricted set of tables is possible even with naive preprocessing schemes. They confirm however that cross-table transfer (i.e. deployment on a table that has not been seen before) is challenging. This suggests that sophisticated encoding schemes are required to handle this problem.
Cross-table Synthetic Tabular Data Detection
Dec 17, 2024



Detecting synthetic tabular data is essential to prevent the distribution of false or manipulated datasets that could compromise data-driven decision-making. This study explores whether synthetic tabular data can be reliably identified ''in the wild''-meaning across different generators, domains, and table formats. This challenge is unique to tabular data, where structures (such as number of columns, data types, and formats) can vary widely from one table to another. We propose three cross-table baseline detectors and four distinct evaluation protocols, each corresponding to a different level of ''wildness''. Our very preliminary results confirm that cross-table adaptation is a challenging task.
Under the Hood of Tabular Data Generation Models: the Strong Impact of Hyperparameter Tuning
Jun 18, 2024



We investigate the impact of dataset-specific hyperparameter, feature encoding, and architecture tuning on five recent model families for tabular data generation through an extensive benchmark on 16 datasets. This study addresses the practical need for a unified evaluation of models that fully considers hyperparameter optimization. Additionally, we propose a reduced search space for each model that allows for quick optimization, achieving nearly equivalent performance at a significantly lower cost.Our benchmark demonstrates that, for most models, large-scale dataset-specific tuning substantially improves performance compared to the original configurations. Furthermore, we confirm that diffusion-based models generally outperform other models on tabular data. However, this advantage is not significant when the entire tuning and training process is restricted to the same GPU budget for all models.
Few-Shot Structured Policy Learning for Multi-Domain and Multi-Task Dialogues
Feb 22, 2023



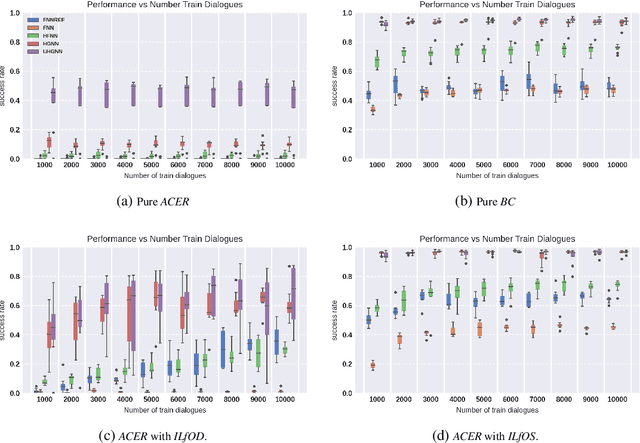
Reinforcement learning has been widely adopted to model dialogue managers in task-oriented dialogues. However, the user simulator provided by state-of-the-art dialogue frameworks are only rough approximations of human behaviour. The ability to learn from a small number of human interactions is hence crucial, especially on multi-domain and multi-task environments where the action space is large. We therefore propose to use structured policies to improve sample efficiency when learning on these kinds of environments. We also evaluate the impact of learning from human vs simulated experts. Among the different levels of structure that we tested, the graph neural networks (GNNs) show a remarkable superiority by reaching a success rate above 80% with only 50 dialogues, when learning from simulated experts. They also show superiority when learning from human experts, although a performance drop was observed, indicating a possible difficulty in capturing the variability of human strategies. We therefore suggest to concentrate future research efforts on bridging the gap between human data, simulators and automatic evaluators in dialogue frameworks.
Graph Neural Network Policies and Imitation Learning for Multi-Domain Task-Oriented Dialogues
Oct 11, 2022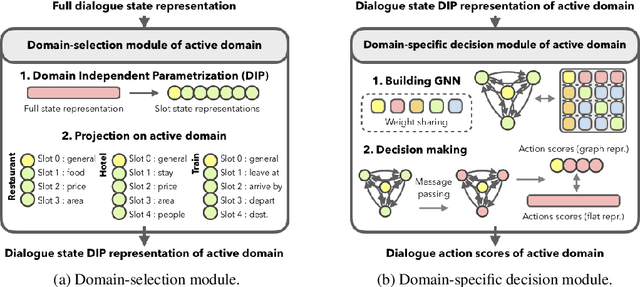
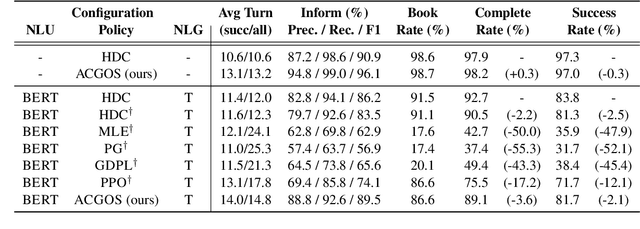
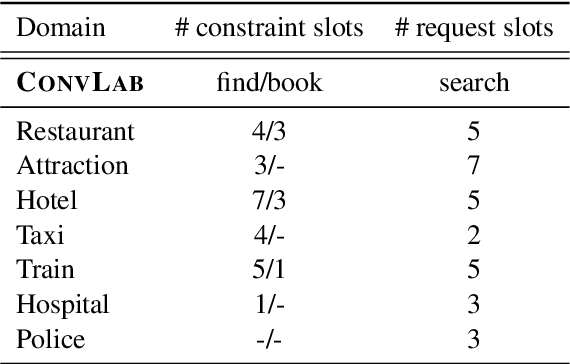
Task-oriented dialogue systems are designed to achieve specific goals while conversing with humans. In practice, they may have to handle simultaneously several domains and tasks. The dialogue manager must therefore be able to take into account domain changes and plan over different domains/tasks in order to deal with multidomain dialogues. However, learning with reinforcement in such context becomes difficult because the state-action dimension is larger while the reward signal remains scarce. Our experimental results suggest that structured policies based on graph neural networks combined with different degrees of imitation learning can effectively handle multi-domain dialogues. The reported experiments underline the benefit of structured policies over standard policies.
Denoising Pre-Training and Data Augmentation Strategies for Enhanced RDF Verbalization with Transformers
Dec 01, 2020
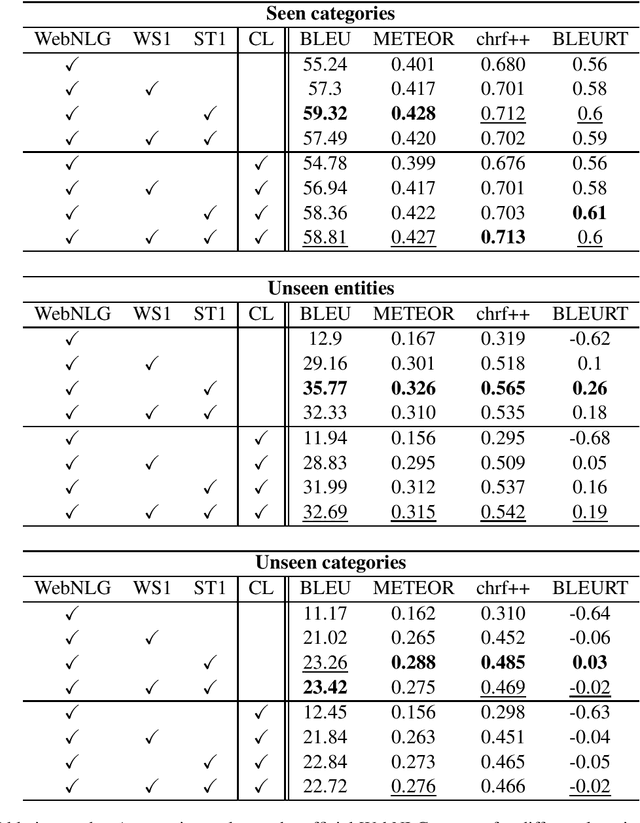
The task of verbalization of RDF triples has known a growth in popularity due to the rising ubiquity of Knowledge Bases (KBs). The formalism of RDF triples is a simple and efficient way to store facts at a large scale. However, its abstract representation makes it difficult for humans to interpret. For this purpose, the WebNLG challenge aims at promoting automated RDF-to-text generation. We propose to leverage pre-trainings from augmented data with the Transformer model using a data augmentation strategy. Our experiment results show a minimum relative increases of 3.73%, 126.05% and 88.16% in BLEU score for seen categories, unseen entities and unseen categories respectively over the standard training.
Diluted Near-Optimal Expert Demonstrations for Guiding Dialogue Stochastic Policy Optimisation
Nov 25, 2020

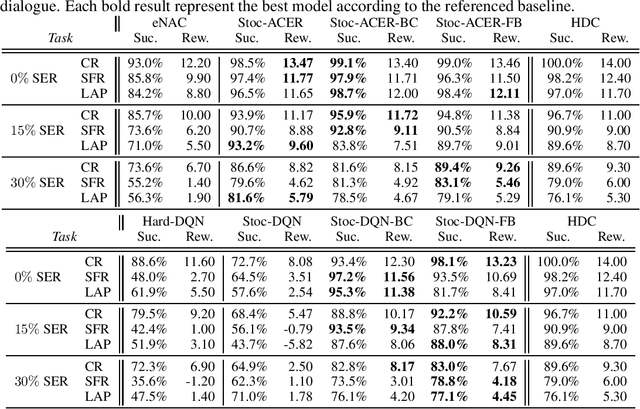
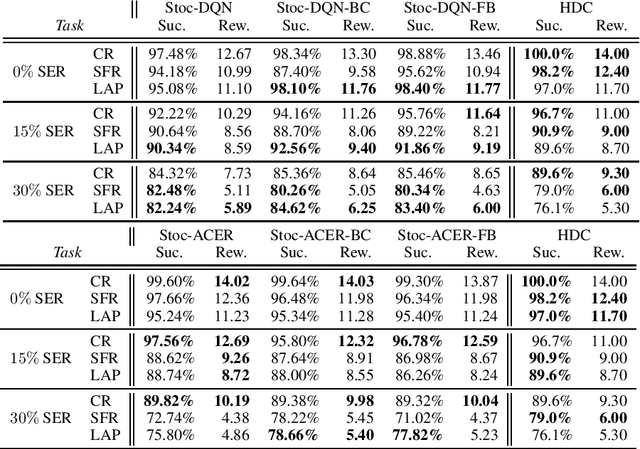
A learning dialogue agent can infer its behaviour from interactions with the users. These interactions can be taken from either human-to-human or human-machine conversations. However, human interactions are scarce and costly, making learning from few interactions essential. One solution to speedup the learning process is to guide the agent's exploration with the help of an expert. We present in this paper several imitation learning strategies for dialogue policy where the guiding expert is a near-optimal handcrafted policy. We incorporate these strategies with state-of-the-art reinforcement learning methods based on Q-learning and actor-critic. We notably propose a randomised exploration policy which allows for a seamless hybridisation of the learned policy and the expert. Our experiments show that our hybridisation strategy outperforms several baselines, and that it can accelerate the learning when facing real humans.
Scaling up budgeted reinforcement learning
Mar 06, 2019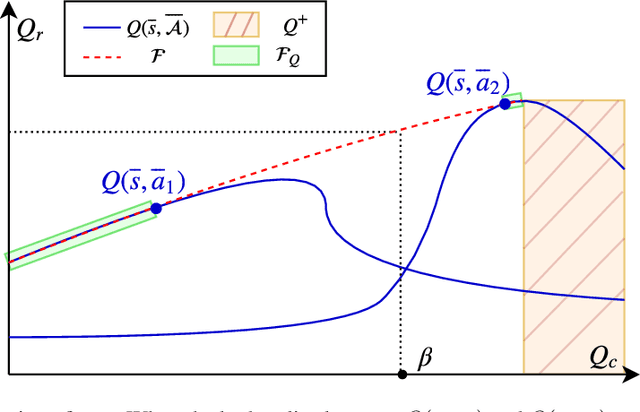
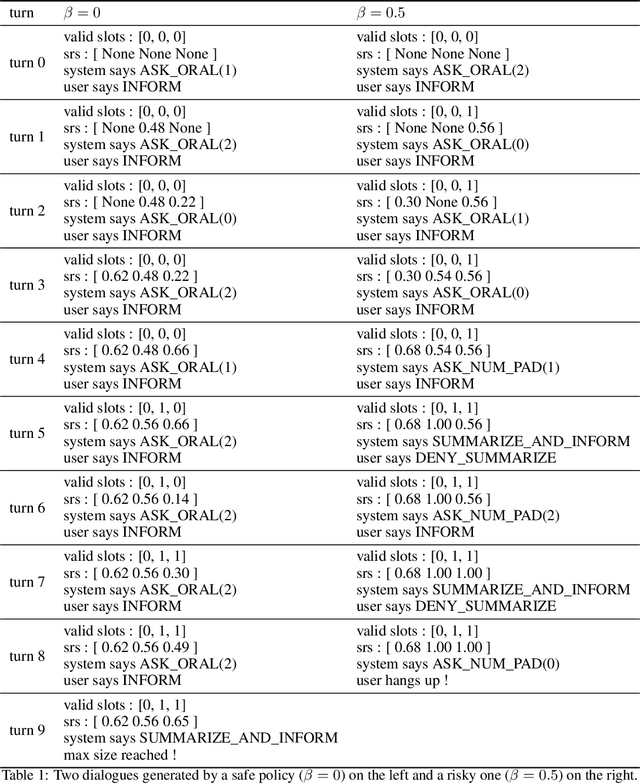
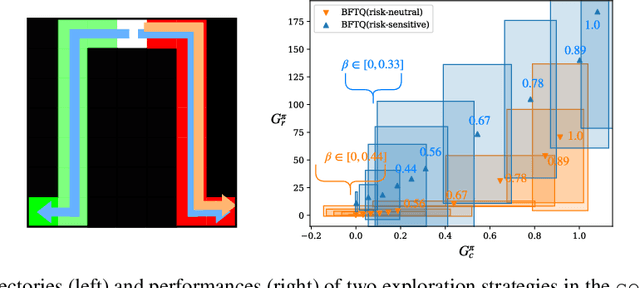
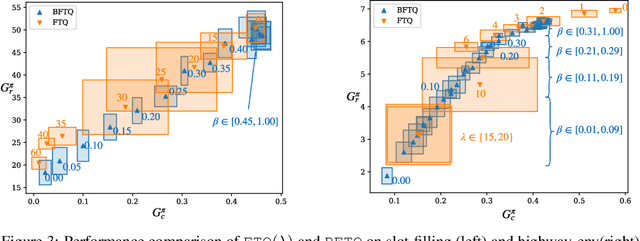
Can we learn a control policy able to adapt its behaviour in real time so as to take any desired amount of risk? The general Reinforcement Learning framework solely aims at optimising a total reward in expectation, which may not be desirable in critical applications. In stark contrast, the Budgeted Markov Decision Process (BMDP) framework is a formalism in which the notion of risk is implemented as a hard constraint on a failure signal. Existing algorithms solving BMDPs rely on strong assumptions and have so far only been applied to toy-examples. In this work, we relax some of these assumptions and demonstrate the scalability of our approach on two practical problems: a spoken dialogue system and an autonomous driving task. On both examples, we reach similar performances as Lagrangian Relaxation methods with a significant improvement in sample and memory efficiency.
Corrupt Bandits for Preserving Local Privacy
Nov 02, 2017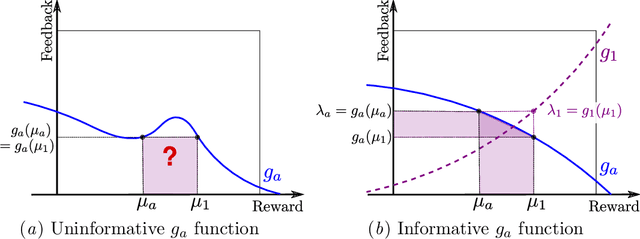
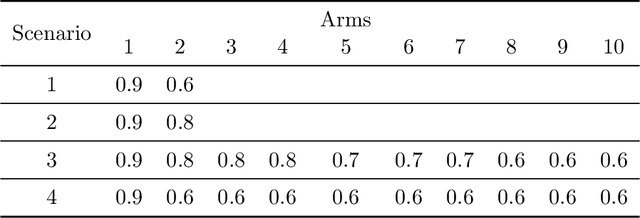
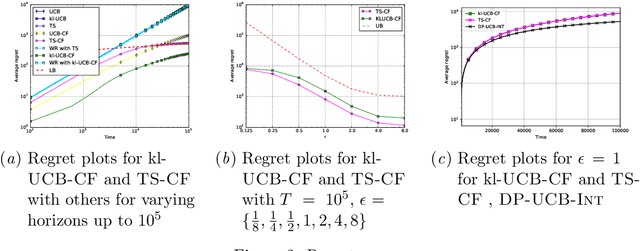
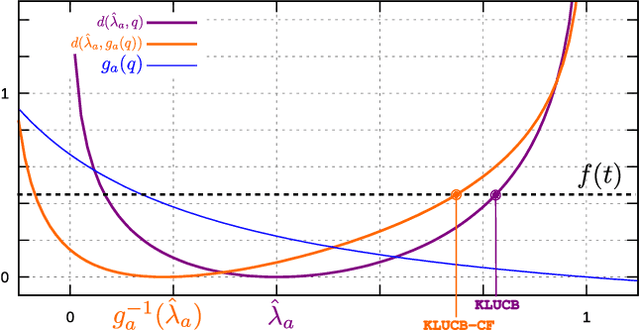
We study a variant of the stochastic multi-armed bandit (MAB) problem in which the rewards are corrupted. In this framework, motivated by privacy preservation in online recommender systems, the goal is to maximize the sum of the (unobserved) rewards, based on the observation of transformation of these rewards through a stochastic corruption process with known parameters. We provide a lower bound on the expected regret of any bandit algorithm in this corrupted setting. We devise a frequentist algorithm, KLUCB-CF, and a Bayesian algorithm, TS-CF and give upper bounds on their regret. We also provide the appropriate corruption parameters to guarantee a desired level of local privacy and analyze how this impacts the regret. Finally, we present some experimental results that confirm our analysis.