 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Long-Term Spatial-Temporal Graphs for Active Speaker Detection
Jul 19, 2022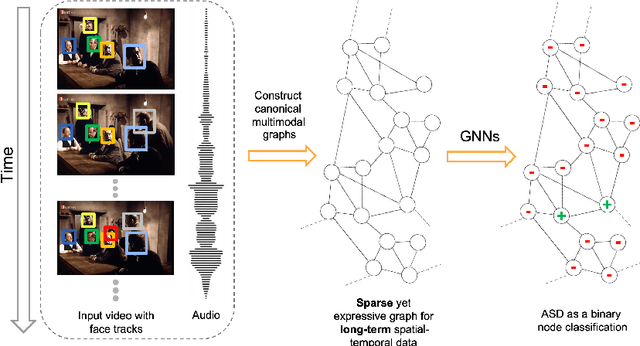

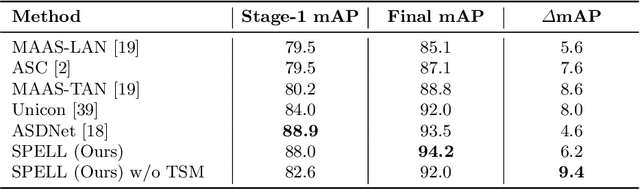
Active speaker detection (ASD) in videos with multiple speakers is a challenging task as it requires learning effective audiovisual features and spatial-temporal correlations over long temporal windows. In this paper, we present SPELL, a novel spatial-temporal graph learning framework that can solve complex tasks such as ASD. To this end, each person in a video frame is first encoded in a unique node for that frame. Nodes corresponding to a single person across frames are connected to encode their temporal dynamics. Nodes within a frame are also connected to encode inter-person relationships. Thus, SPELL reduces ASD to a node classification task. Importantly, SPELL is able to reason over long temporal contexts for all nodes without relying on computationally expensive fully connected graph neural networks. Through extensive experiments on the AVA-ActiveSpeaker dataset, we demonstrate that learning graph-based representations can significantly improve the active speaker detection performance owing to its explicit spatial and temporal structure. SPELL outperforms all previous state-of-the-art approaches while requiring significantly lower memory and computational resources. Our code is publicly available at https://github.com/SRA2/SPELL
Visually-aware Acoustic Event Detection using Heterogeneous Graphs
Jul 16, 2022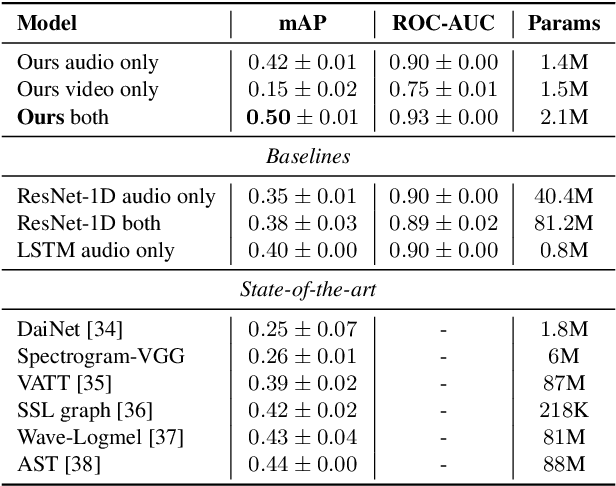

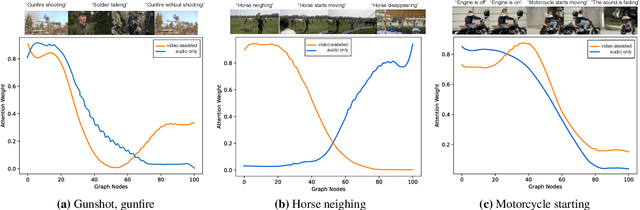
Perception of auditory events is inherently multimodal relying on both audio and visual cues. A large number of existing multimodal approaches process each modality using modality-specific models and then fuse the embeddings to encode the joint information. In contrast, we employ heterogeneous graphs to explicitly capture the spatial and temporal relationships between the modalities and represent detailed information about the underlying signal. Using heterogeneous graph approaches to address the task of visually-aware acoustic event classification, which serves as a compact, efficient and scalable way to represent data in the form of graphs. Through heterogeneous graphs, we show efficiently modelling of intra- and inter-modality relationships both at spatial and temporal scales. Our model can easily be adapted to different scales of events through relevant hyperparameters. Experiments on AudioSet, a large benchmark, shows that our model achieves state-of-the-art performance.
FusionCount: Efficient Crowd Counting via Multiscale Feature Fusion
Feb 28, 2022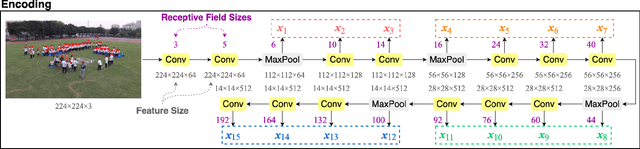
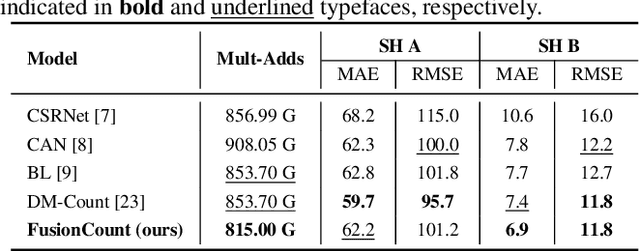
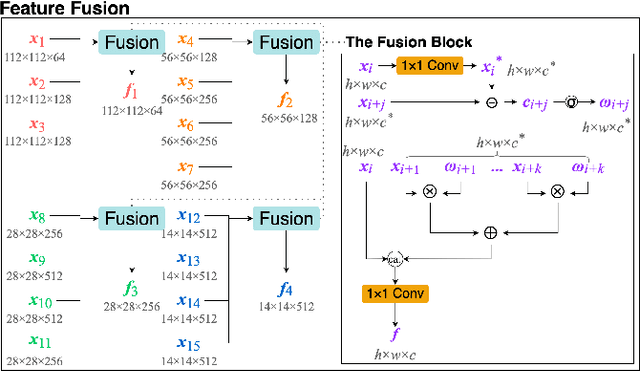

State-of-the-art crowd counting models follow an encoder-decoder approach. Images are first processed by the encoder to extract features. Then, to account for perspective distortion, the highest-level feature map is fed to extra components to extract multiscale features, which are the input to the decoder to generate crowd densities. However, in these methods, features extracted at earlier stages during encoding are underutilised, and the multiscale modules can only capture a limited range of receptive fields, albeit with considerable computational cost. This paper proposes a novel crowd counting architecture (FusionCount), which exploits the adaptive fusion of a large majority of encoded features instead of relying on additional extraction components to obtain multiscale features. Thus, it can cover a more extensive scope of receptive field sizes and lower the computational cost. We also introduce a new channel reduction block, which can extract saliency information during decoding and further enhance the model's performance. Experiments on two benchmark databases demonstrate that our model achieves state-of-the-art results with reduced computational complexity.
Self-supervised Graphs for Audio Representation Learning with Limited Labeled Data
Jan 31, 2022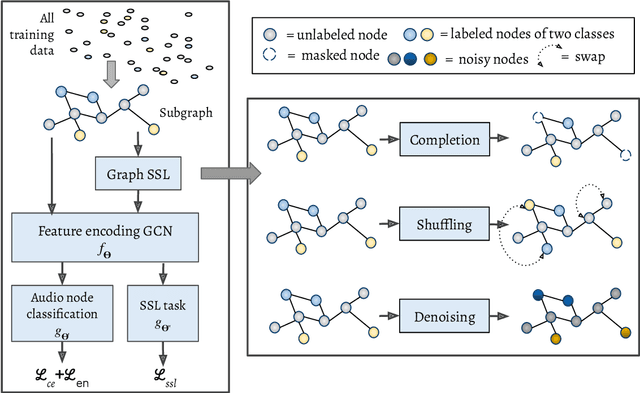
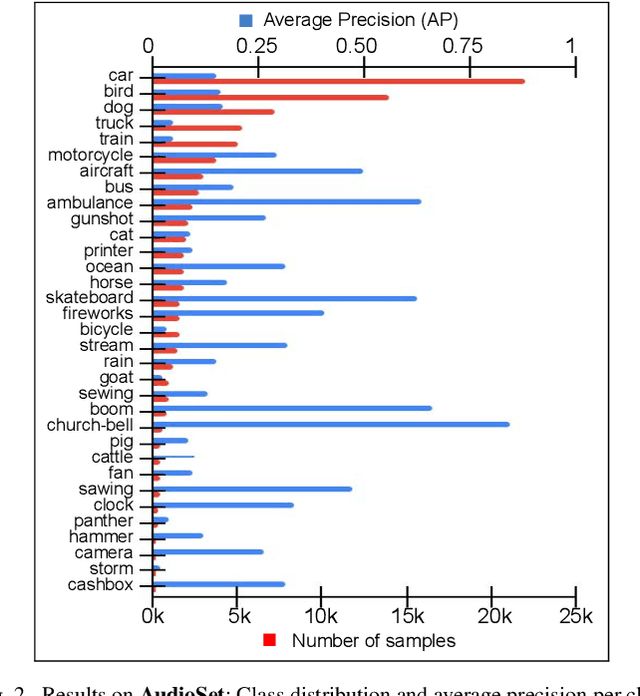
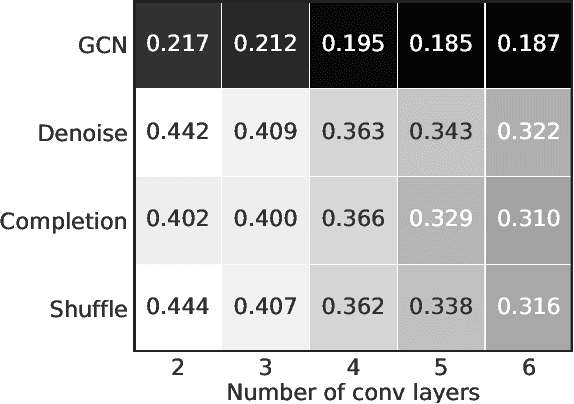
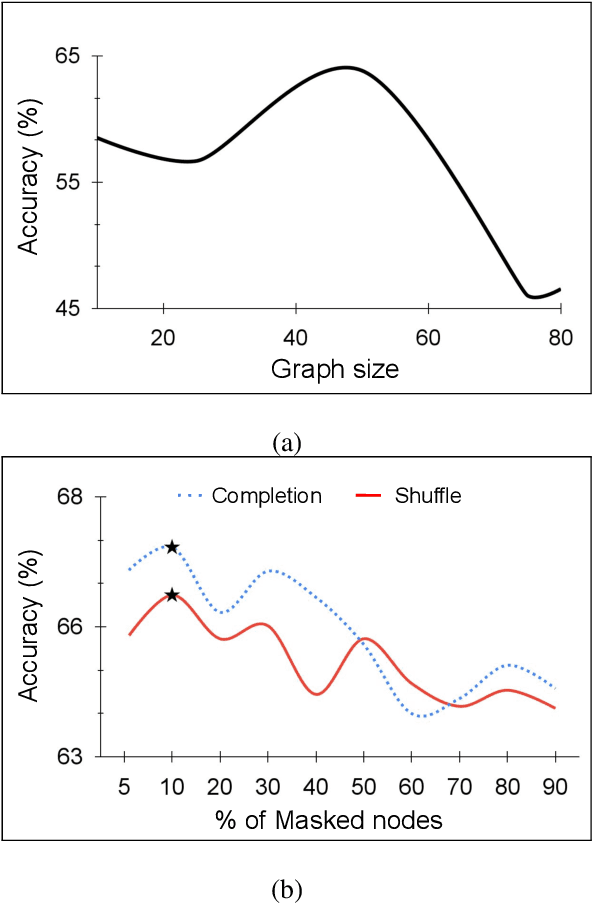
Large scale databases with high-quality manual annotations are scarce in audio domain. We thus explore a self-supervised graph approach to learning audio representations from highly limited labelled data. Considering each audio sample as a graph node, we propose a subgraph-based framework with novel self-supervision tasks that can learn effective audio representations. During training, subgraphs are constructed by sampling the entire pool of available training data to exploit the relationship between the labelled and unlabeled audio samples. During inference, we use random edges to alleviate the overhead of graph construction. We evaluate our model on three benchmark audio databases, and two tasks: acoustic event detection and speech emotion recognition. Our semi-supervised model performs better or on par with fully supervised models and outperforms several competitive existing models. Our model is compact (240k parameters), and can produce generalized audio representations that are robust to different types of signal noise.
Head Matters: Explainable Human-centered Trait Prediction from Head Motion Dynamics
Dec 15, 2021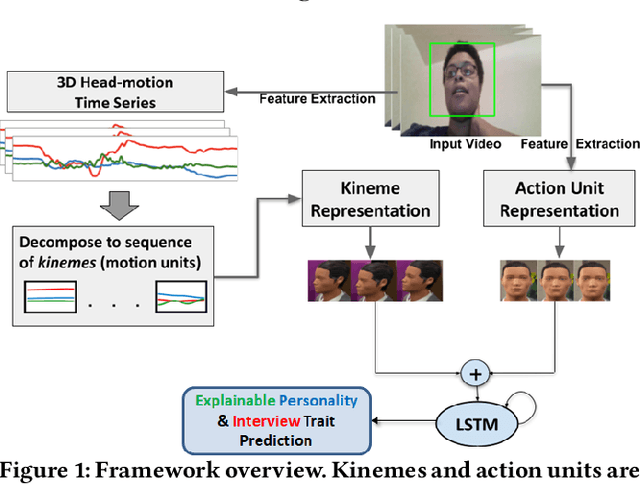
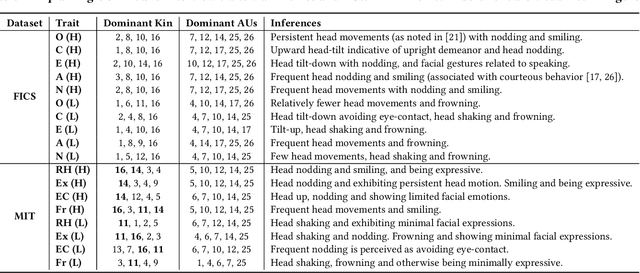

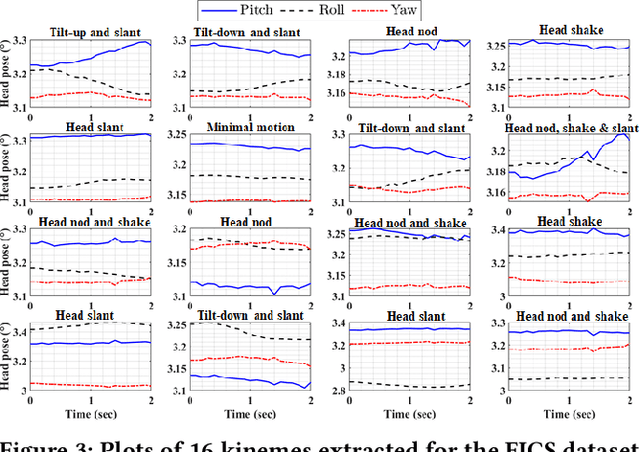
We demonstrate the utility of elementary head-motion units termed kinemes for behavioral analytics to predict personality and interview traits. Transforming head-motion patterns into a sequence of kinemes facilitates discovery of latent temporal signatures characterizing the targeted traits, thereby enabling both efficient and explainable trait prediction. Utilizing Kinemes and Facial Action Coding System (FACS) features to predict (a) OCEAN personality traits on the First Impressions Candidate Screening videos, and (b) Interview traits on the MIT dataset, we note that: (1) A Long-Short Term Memory (LSTM) network trained with kineme sequences performs better than or similar to a Convolutional Neural Network (CNN) trained with facial images; (2) Accurate predictions and explanations are achieved on combining FACS action units (AUs) with kinemes, and (3) Prediction performance is affected by the time-length over which head and facial movements are observed.
Learning Spatial-Temporal Graphs for Active Speaker Detection
Dec 03, 2021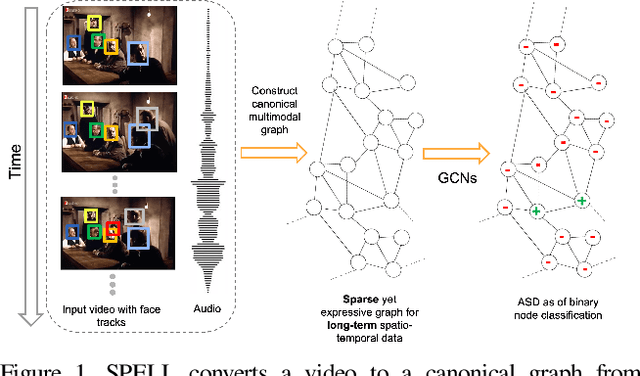
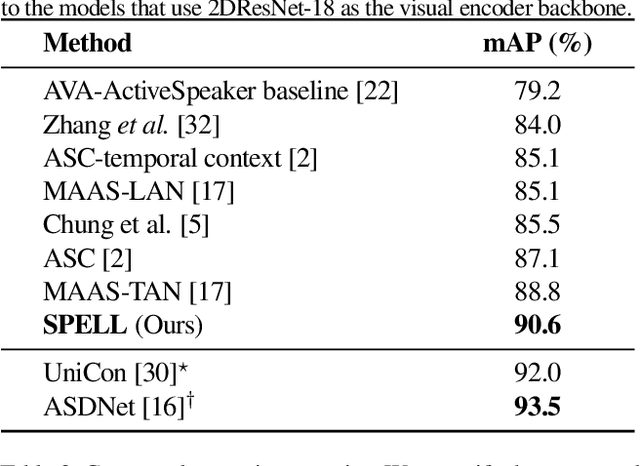
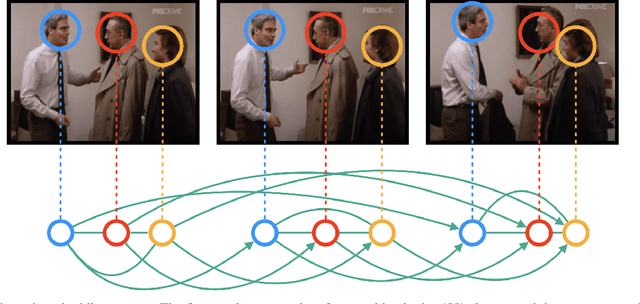
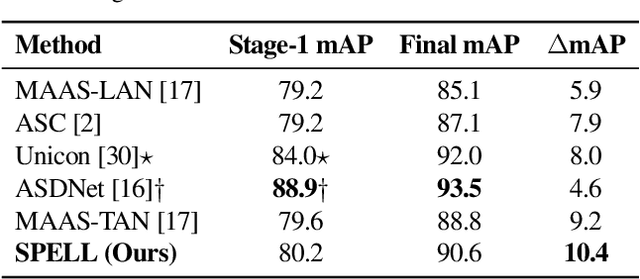
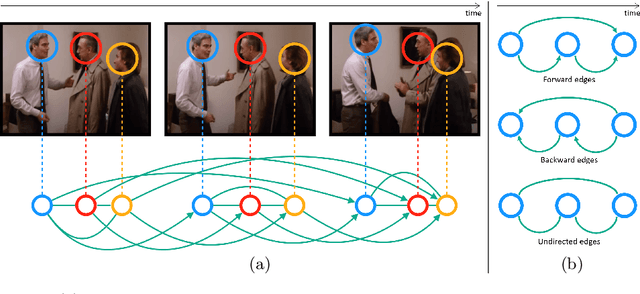
We address the problem of active speaker detection through a new framework, called SPELL, that learns long-range multimodal graphs to encode the inter-modal relationship between audio and visual data. We cast active speaker detection as a node classification task that is aware of longer-term dependencies. We first construct a graph from a video so that each node corresponds to one person. Nodes representing the same identity share edges between them within a defined temporal window. Nodes within the same video frame are also connected to encode inter-person interactions. Through extensive experiments on the Ava-ActiveSpeaker dataset, we demonstrate that learning graph-based representation, owing to its explicit spatial and temporal structure, significantly improves the overall performance. SPELL outperforms several relevant baselines and performs at par with state of the art models while requiring an order of magnitude lower computation cost.
Multi-Camera Trajectory Forecasting with Trajectory Tensors
Aug 24, 2021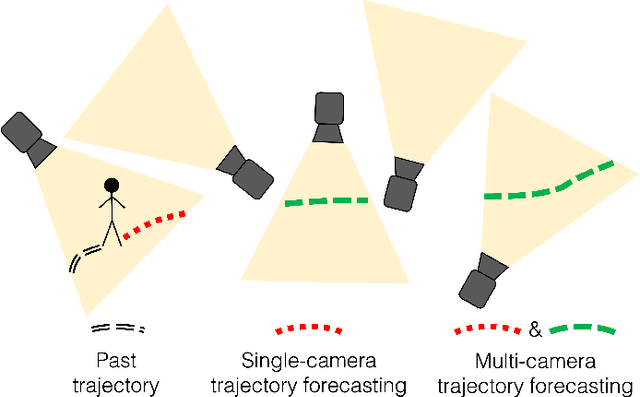
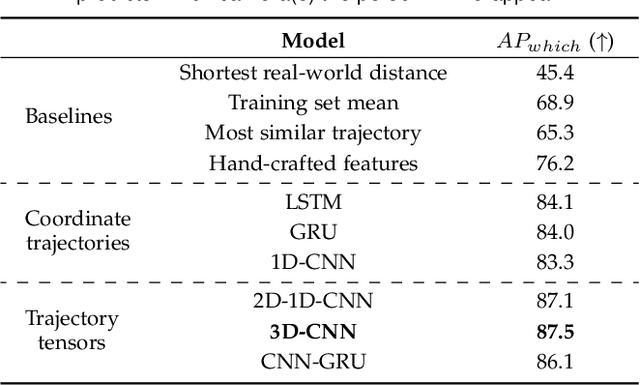
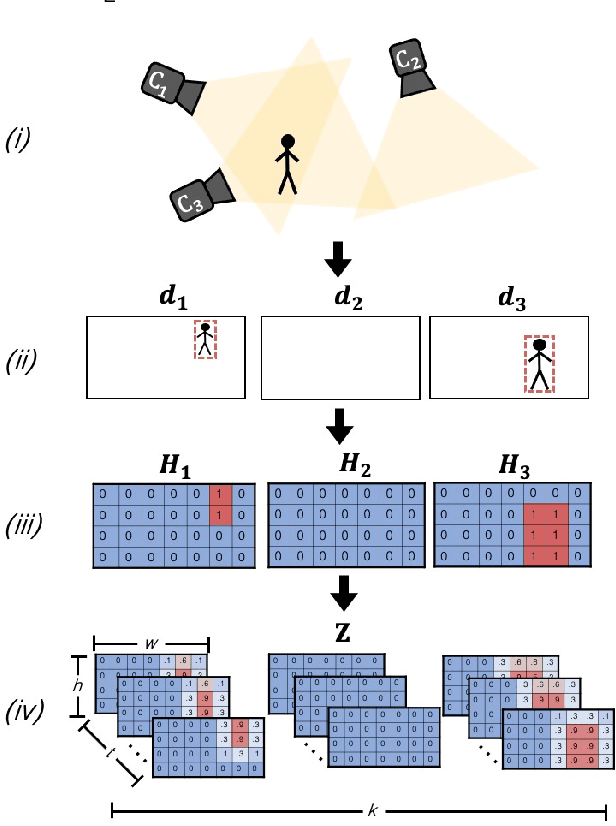
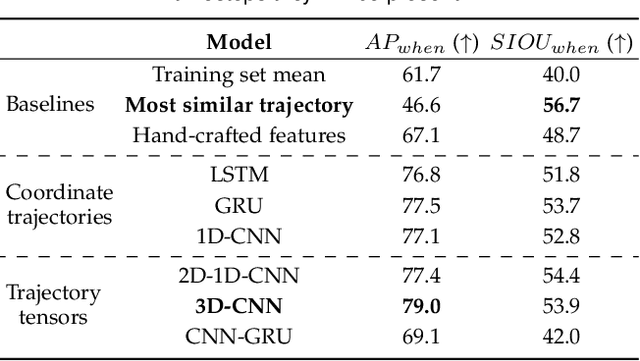
We introduce the problem of multi-camera trajectory forecasting (MCTF), which involves predicting the trajectory of a moving object across a network of cameras. While multi-camera setups are widespread for applications such as surveillance and traffic monitoring, existing trajectory forecasting methods typically focus on single-camera trajectory forecasting (SCTF), limiting their use for such applications. Furthermore, using a single camera limits the field-of-view available, making long-term trajectory forecasting impossible. We address these shortcomings of SCTF by developing an MCTF framework that simultaneously uses all estimated relative object locations from several viewpoints and predicts the object's future location in all possible viewpoints. Our framework follows a Which-When-Where approach that predicts in which camera(s) the objects appear and when and where within the camera views they appear. To this end, we propose the concept of trajectory tensors: a new technique to encode trajectories across multiple camera views and the associated uncertainties. We develop several encoder-decoder MCTF models for trajectory tensors and present extensive experiments on our own database (comprising 600 hours of video data from 15 camera views) created particularly for the MCTF task. Results show that our trajectory tensor models outperform coordinate trajectory-based MCTF models and existing SCTF methods adapted for MCTF. Code is available from: https://github.com/olly-styles/Trajectory-Tensors
SG2Caps: Revisiting Scene Graphs for Image Captioning
Feb 09, 2021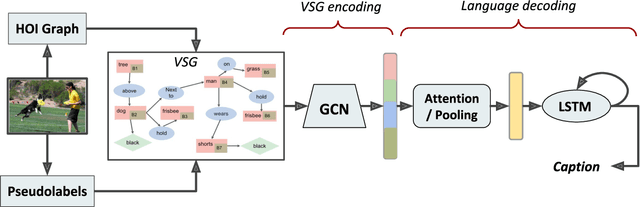
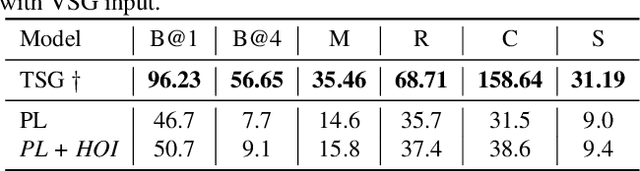
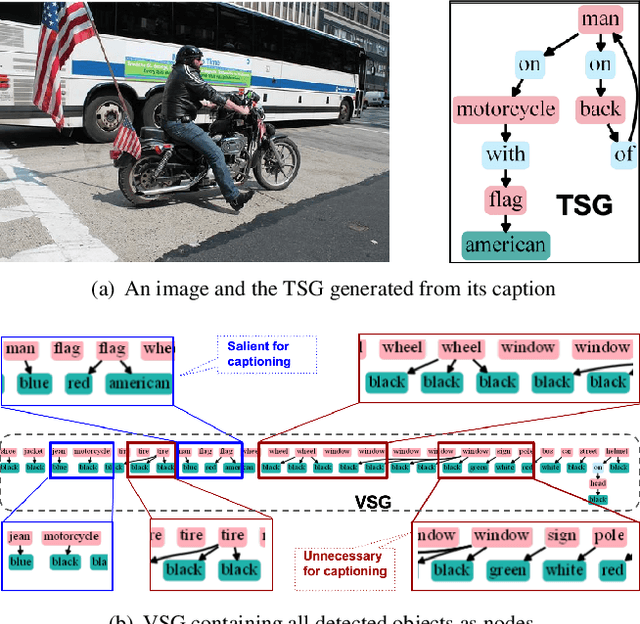
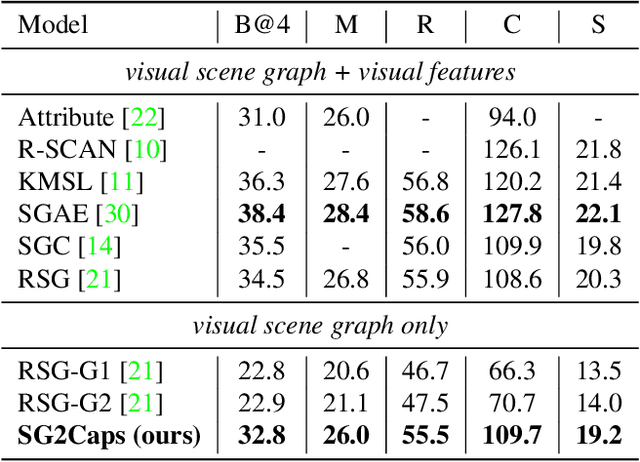
The mainstream image captioning models rely on Convolutional Neural Network (CNN) image features with an additional attention to salient regions and objects to generate captions via recurrent models. Recently, scene graph representations of images have been used to augment captioning models so as to leverage their structural semantics, such as object entities, relationships and attributes. Several studies have noted that naive use of scene graphs from a black-box scene graph generator harms image caption-ing performance, and scene graph-based captioning mod-els have to incur the overhead of explicit use of image features to generate decent captions. Addressing these challenges, we propose a framework, SG2Caps, that utilizes only the scene graph labels for competitive image caption-ing performance. The basic idea is to close the semantic gap between two scene graphs - one derived from the input image and the other one from its caption. In order to achieve this, we leverage the spatial location of objects and the Human-Object-Interaction (HOI) labels as an additional HOI graph. Our framework outperforms existing scene graph-only captioning models by a large margin (CIDEr score of 110 vs 71) indicating scene graphs as a promising representation for image captioning. Direct utilization of the scene graph labels avoids expensive graph convolutions over high-dimensional CNN features resulting in 49%fewer trainable parameters.
Dynamic Character Graph via Online Face Clustering for Movie Analysis
Jul 29, 2020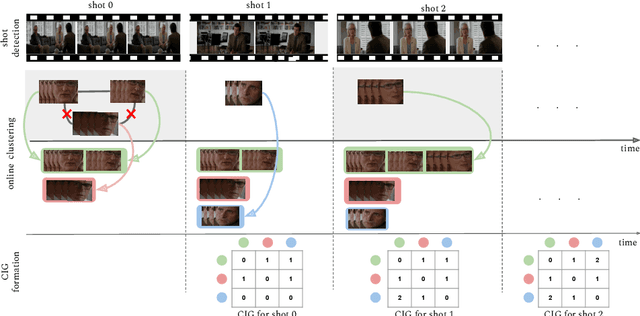
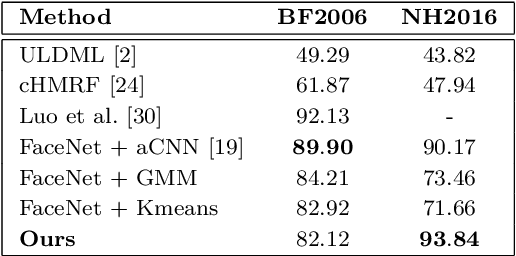

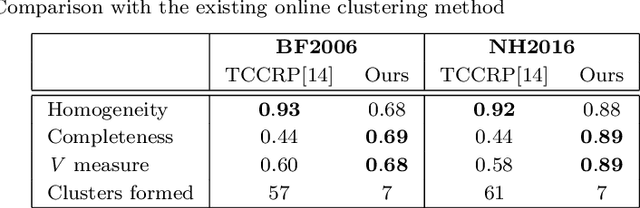
An effective approach to automated movie content analysis involves building a network (graph) of its characters. Existing work usually builds a static character graph to summarize the content using metadata, scripts or manual annotations. We propose an unsupervised approach to building a dynamic character graph that captures the temporal evolution of character interaction. We refer to this as the character interaction graph(CIG). Our approach has two components:(i) an online face clustering algorithm that discovers the characters in the video stream as they appear, and (ii) simultaneous creation of a CIG using the temporal dynamics of the resulting clusters. We demonstrate the usefulness of the CIG for two movie analysis tasks: narrative structure (acts) segmentation, and major character retrieval. Our evaluation on full-length movies containing more than 5000 face tracks shows that the proposed approach achieves superior performance for both the tasks.
Ensemble Network for Ranking Images Based on Visual Appeal
Jun 06, 2020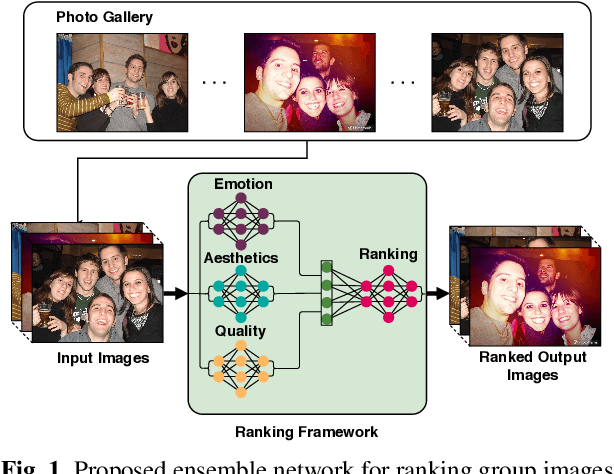


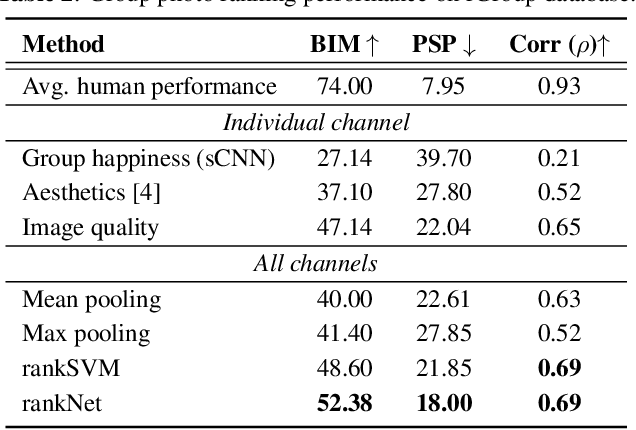
We propose a computational framework for ranking images (group photos in particular) taken at the same event within a short time span. The ranking is expected to correspond with human perception of overall appeal of the images. We hypothesize and provide evidence through subjective analysis that the factors that appeal to humans are its emotional content, aesthetics and image quality. We propose a network which is an ensemble of three information channels, each predicting a score corresponding to one of the three visual appeal factors. For group emotion estimation, we propose a convolutional neural network (CNN) based architecture for predicting group emotion from images. This new architecture enforces the network to put emphasis on the important regions in the images, and achieves comparable results to the state-of-the-art. Next, we develop a network for the image ranking task that combines group emotion, aesthetics and image quality scores. Owing to the unavailability of suitable databases, we created a new database of manually annotated group photos taken during various social events. We present experimental results on this database and other benchmark databases whenever available. Overall, our experiments show that the proposed framework can reliably predict the overall appeal of images with results closely corresponding to human ranking.