 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Adaptation for Height Completion via Self-Supervised ViT Features and Monocular Foundation Models
Apr 02, 2026Accurate digital surface models (DSMs) are essential for many geospatial applications, including urban monitoring, environmental analyses, infrastructure management, and change detection. However, large-scale DSMs frequently contain incomplete or outdated regions due to acquisition limitations, reconstruction artifacts, or changes in the built environment. Traditional height completion approaches primarily rely on spatial interpolation or which assume spatial continuity and therefore fail when objects are missing. Recent learning-based approaches improve reconstruction quality but typically require supervised training on sensor-specific datasets, limiting their generalization across domains and sensing conditions. We propose Prior2DSM, a training-free framework for metric DSM completion that operates entirely at test time by leveraging foundation models. Unlike previous height completion approaches that require task-specific training, the proposed method combines self-supervised Vision Transformer (ViT) features from DINOv3 with monocular depth foundation models to propagate metric information from incomplete height priors through semantic feature-space correspondence. Test-time adaptation (TTA) is performed using parameter-efficient low-rank adaptation (LoRA) together with a lightweight multilayer perceptron (MLP), which predicts spatially varying scale and shift parameters to convert relative depth estimates into metric heights. Experiments demonstrate consistent improvements over interpolation based methods, prior-based rescaling height approaches, and state-of-the-art monocular depth estimation models. Prior2DSM reduces reconstruction error while preserving structural fidelity, achieving up to a 46% reduction in RMSE compared to linear fitting of MDE, and further enables DSM updating and coupled RGB-DSM generation.
On the Effectiveness of Textual Prompting with Lightweight Fine-Tuning for SAM3 Remote Sensing Segmentation
Dec 17, 2025Remote sensing (RS) image segmentation is constrained by the limited availability of annotated data and a gap between overhead imagery and natural images used to train foundational models. This motivates effective adaptation under limited supervision. SAM3 concept-driven framework generates masks from textual prompts without requiring task-specific modifications, which may enable this adaptation. We evaluate SAM3 for RS imagery across four target types, comparing textual, geometric, and hybrid prompting strategies, under lightweight fine-tuning scales with increasing supervision, alongside zero-shot inference. Results show that combining semantic and geometric cues yields the highest performance across targets and metrics. Text-only prompting exhibits the lowest performance, with marked score gaps for irregularly shaped targets, reflecting limited semantic alignment between SAM3 textual representations and their overhead appearances. Nevertheless, textual prompting with light fine-tuning offers a practical performance-effort trade-off for geometrically regular and visually salient targets. Across targets, performance improves between zero-shot inference and fine-tuning, followed by diminishing returns as the supervision scale increases. Namely, a modest geometric annotation effort is sufficient for effective adaptation. A persistent gap between Precision and IoU further indicates that under-segmentation and boundary inaccuracies remain prevalent error patterns in RS tasks, particularly for irregular and less prevalent targets.
SinkSAM: A Monocular Depth-Guided SAM Framework for Automatic Sinkhole Segmentation
Oct 02, 2024



Soil sinkholes significantly influence soil degradation, but their irregular shapes, along with interference from shadow and vegetation, make it challenging to accurately quantify their properties using remotely sensed data. We present a novel framework for sinkhole segmentation that combines traditional topographic computations of closed depressions with the newly developed prompt-based Segment Anything Model (SAM). Within this framework, termed SinkSAM, we highlight four key improvements: (1) The integration of topographic computations with SAM enables pixel-level refinement of sinkhole boundaries segmentation; (2) A coherent mathematical prompting strategy, based on closed depressions, addresses the limitations of purely learning-based models (CNNs) in detecting and segmenting undefined sinkhole features, while improving generalization to new, unseen regions; (3) Using Depth Anything V2 monocular depth for automatic prompts eliminates photogrammetric biases, enabling sinkhole mapping without the dependence on LiDAR data; and (4) An established sinkhole database facilitates fine-tuning of SAM, improving its zero-shot performance in sinkhole segmentation. These advancements allow the deployment of SinkSAM, in an unseen test area, in the highly variable semiarid region, achieving an intersection-over-union (IoU) of 40.27\% and surpassing previous results. This paper also presents the first SAM implementation for sinkhole segmentation and demonstrates the robustness of SinkSAM in extracting sinkhole maps using a single RGB image.
Performance of Human Annotators in Object Detection and Segmentation of Remotely Sensed Data
Sep 16, 2024



This study introduces a laboratory experiment designed to assess the influence of annotation strategies, levels of imbalanced data, and prior experience, on the performance of human annotators. The experiment focuses on labeling aerial imagery, using ArcGIS Pro tools, to detect and segment small-scale photovoltaic solar panels, selected as a case study for rectangular objects. The experiment is conducted using images with a pixel size of 0.15\textbf{$m$}, involving both expert and non-expert participants, across different setup strategies and target-background ratio datasets. Our findings indicate that human annotators generally perform more effectively in object detection than in segmentation tasks. A marked tendency to commit more Type II errors (False Negatives, i.e., undetected objects) than Type I errors (False Positives, i.e. falsely detecting objects that do not exist) was observed across all experimental setups and conditions, suggesting a consistent bias in detection and segmentation processes. Performance was better in tasks with higher target-background ratios (i.e., more objects per unit area). Prior experience did not significantly impact performance and may, in some cases, even lead to overestimation in segmentation. These results provide evidence that human annotators are relatively cautious and tend to identify objects only when they are confident about them, prioritizing underestimation over overestimation. Annotators' performance is also influenced by object scarcity, showing a decline in areas with extremely imbalanced datasets and a low ratio of target-to-background. These findings may enhance annotation strategies for remote sensing research while efficient human annotators are crucial in an era characterized by growing demands for high-quality training data to improve segmentation and detection models.
Prompt-Based Segmentation at Multiple Resolutions and Lighting Conditions using Segment Anything Model 2
Aug 15, 2024

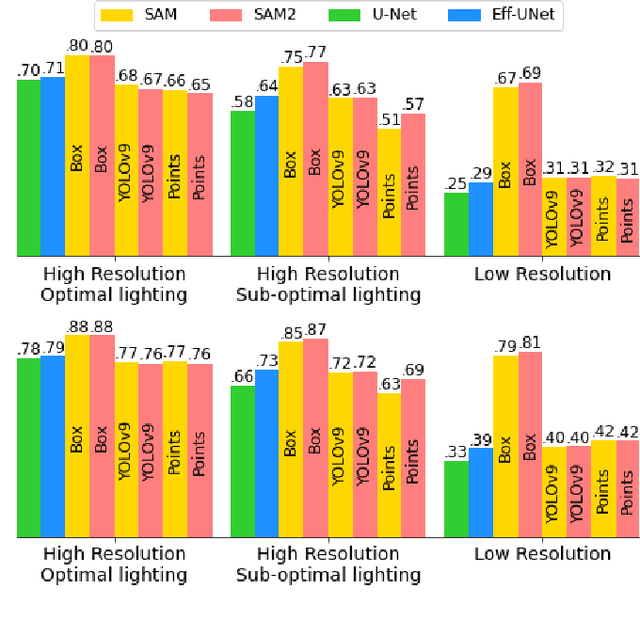

This paper provides insight into the effectiveness of zero-shot, prompt-based, Segment Anything Model (SAM), and its updated version, SAM 2, and the non-promptable, conventional convolutional network (CNN), in segmenting solar panels, in RGB aerial imagery, across lighting conditions, spatial resolutions, and prompt strategies. SAM 2 demonstrates improvements over SAM, particularly in sub-optimal lighting conditions when prompted by points. Both SAMs, prompted by user-box, outperformed CNN, in all scenarios. Additionally, YOLOv9 prompting outperformed user points prompting. In high-resolution imagery, both in optimal and sub-optimal lighting conditions, Eff-UNet outperformed both SAM models prompted by YOLOv9 boxes, positioning Eff-UNet as the appropriate model for automatic segmentation in high-resolution data. In low-resolution data, user box prompts were found crucial to achieve a reasonable performance. This paper provides details on strengths and limitations of each model and outlines robustness of user prompted image segmentation models in inconsistent resolution and lighting conditions of remotely sensed data.