 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Textual Prompting with Lightweight Fine-Tuning for SAM3 Remote Sensing Segmentation
Dec 17, 2025Remote sensing (RS) image segmentation is constrained by the limited availability of annotated data and a gap between overhead imagery and natural images used to train foundational models. This motivates effective adaptation under limited supervision. SAM3 concept-driven framework generates masks from textual prompts without requiring task-specific modifications, which may enable this adaptation. We evaluate SAM3 for RS imagery across four target types, comparing textual, geometric, and hybrid prompting strategies, under lightweight fine-tuning scales with increasing supervision, alongside zero-shot inference. Results show that combining semantic and geometric cues yields the highest performance across targets and metrics. Text-only prompting exhibits the lowest performance, with marked score gaps for irregularly shaped targets, reflecting limited semantic alignment between SAM3 textual representations and their overhead appearances. Nevertheless, textual prompting with light fine-tuning offers a practical performance-effort trade-off for geometrically regular and visually salient targets. Across targets, performance improves between zero-shot inference and fine-tuning, followed by diminishing returns as the supervision scale increases. Namely, a modest geometric annotation effort is sufficient for effective adaptation. A persistent gap between Precision and IoU further indicates that under-segmentation and boundary inaccuracies remain prevalent error patterns in RS tasks, particularly for irregular and less prevalent targets.
Performance of Human Annotators in Object Detection and Segmentation of Remotely Sensed Data
Sep 16, 2024



This study introduces a laboratory experiment designed to assess the influence of annotation strategies, levels of imbalanced data, and prior experience, on the performance of human annotators. The experiment focuses on labeling aerial imagery, using ArcGIS Pro tools, to detect and segment small-scale photovoltaic solar panels, selected as a case study for rectangular objects. The experiment is conducted using images with a pixel size of 0.15\textbf{$m$}, involving both expert and non-expert participants, across different setup strategies and target-background ratio datasets. Our findings indicate that human annotators generally perform more effectively in object detection than in segmentation tasks. A marked tendency to commit more Type II errors (False Negatives, i.e., undetected objects) than Type I errors (False Positives, i.e. falsely detecting objects that do not exist) was observed across all experimental setups and conditions, suggesting a consistent bias in detection and segmentation processes. Performance was better in tasks with higher target-background ratios (i.e., more objects per unit area). Prior experience did not significantly impact performance and may, in some cases, even lead to overestimation in segmentation. These results provide evidence that human annotators are relatively cautious and tend to identify objects only when they are confident about them, prioritizing underestimation over overestimation. Annotators' performance is also influenced by object scarcity, showing a decline in areas with extremely imbalanced datasets and a low ratio of target-to-background. These findings may enhance annotation strategies for remote sensing research while efficient human annotators are crucial in an era characterized by growing demands for high-quality training data to improve segmentation and detection models.
Prompt-Based Segmentation at Multiple Resolutions and Lighting Conditions using Segment Anything Model 2
Aug 15, 2024

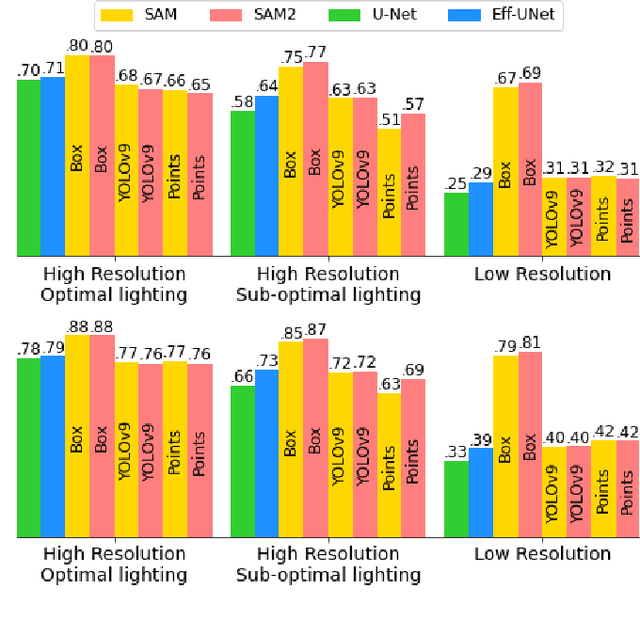

This paper provides insight into the effectiveness of zero-shot, prompt-based, Segment Anything Model (SAM), and its updated version, SAM 2, and the non-promptable, conventional convolutional network (CNN), in segmenting solar panels, in RGB aerial imagery, across lighting conditions, spatial resolutions, and prompt strategies. SAM 2 demonstrates improvements over SAM, particularly in sub-optimal lighting conditions when prompted by points. Both SAMs, prompted by user-box, outperformed CNN, in all scenarios. Additionally, YOLOv9 prompting outperformed user points prompting. In high-resolution imagery, both in optimal and sub-optimal lighting conditions, Eff-UNet outperformed both SAM models prompted by YOLOv9 boxes, positioning Eff-UNet as the appropriate model for automatic segmentation in high-resolution data. In low-resolution data, user box prompts were found crucial to achieve a reasonable performance. This paper provides details on strengths and limitations of each model and outlines robustness of user prompted image segmentation models in inconsistent resolution and lighting conditions of remotely sensed data.