 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Groundedness in Dialogue Systems: The BEGIN Benchmark
Apr 30, 2021
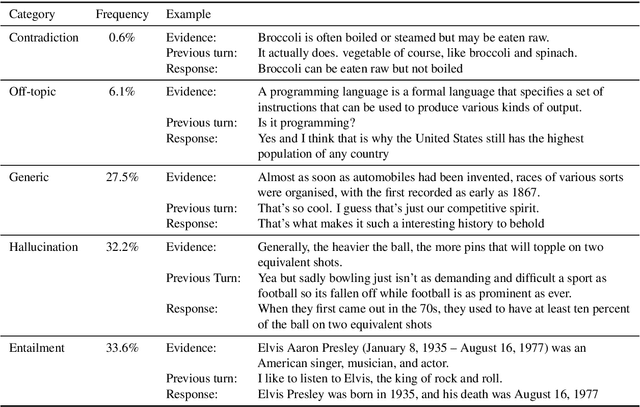

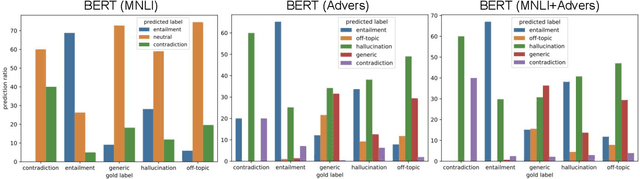
Knowledge-grounded dialogue agents are systems designed to conduct a conversation based on externally provided background information, such as a Wikipedia page. Such dialogue agents, especially those based on neural network language models, often produce responses that sound fluent but are not justified by the background information. Progress towards addressing this problem requires developing automatic evaluation metrics that can quantify the extent to which responses are grounded in background information. To facilitate evaluation of such metrics, we introduce the Benchmark for Evaluation of Grounded INteraction (BEGIN). BEGIN consists of 8113 dialogue turns generated by language-model-based dialogue systems, accompanied by humans annotations specifying the relationship between the system's response and the background information. These annotations are based on an extension of the natural language inference paradigm. We use the benchmark to demonstrate the effectiveness of adversarially generated data for improving an evaluation metric based on existing natural language inference datasets.
Does Putting a Linguist in the Loop Improve NLU Data Collection?
Apr 15, 2021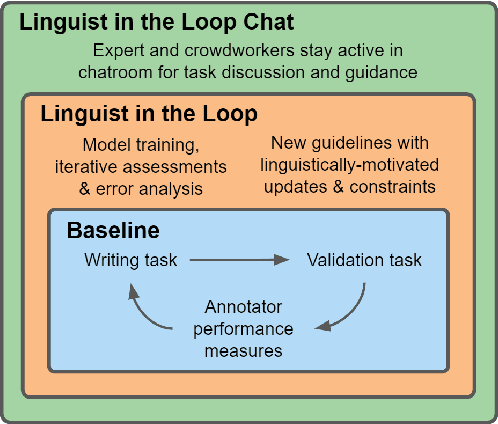
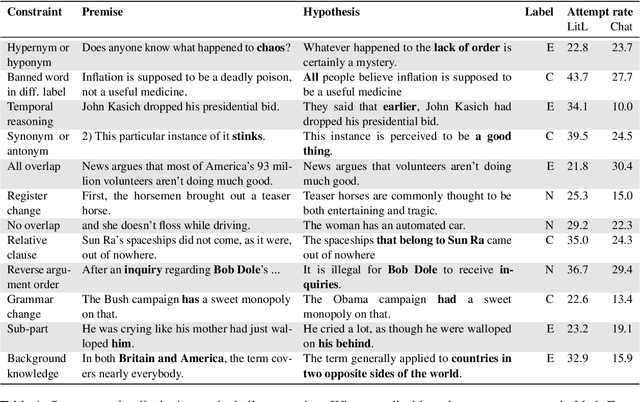

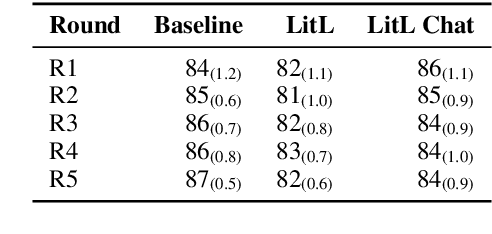
Many crowdsourced NLP datasets contain systematic gaps and biases that are identified only after data collection is complete. Identifying these issues from early data samples during crowdsourcing should make mitigation more efficient, especially when done iteratively. We take natural language inference as a test case and ask whether it is beneficial to put a linguist `in the loop' during data collection to dynamically identify and address gaps in the data by introducing novel constraints on the task. We directly compare three data collection protocols: (i) a baseline protocol, (ii) a linguist-in-the-loop intervention with iteratively-updated constraints on the task, and (iii) an extension of linguist-in-the-loop that provides direct interaction between linguists and crowdworkers via a chatroom. The datasets collected with linguist involvement are more reliably challenging than baseline, without loss of quality. But we see no evidence that using this data in training leads to better out-of-domain model performance, and the addition of a chat platform has no measurable effect on the resulting dataset. We suggest integrating expert analysis \textit{during} data collection so that the expert can dynamically address gaps and biases in the dataset.
COGS: A Compositional Generalization Challenge Based on Semantic Interpretation
Oct 12, 2020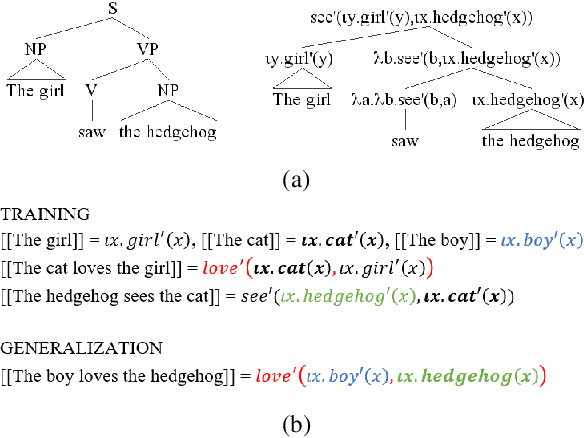
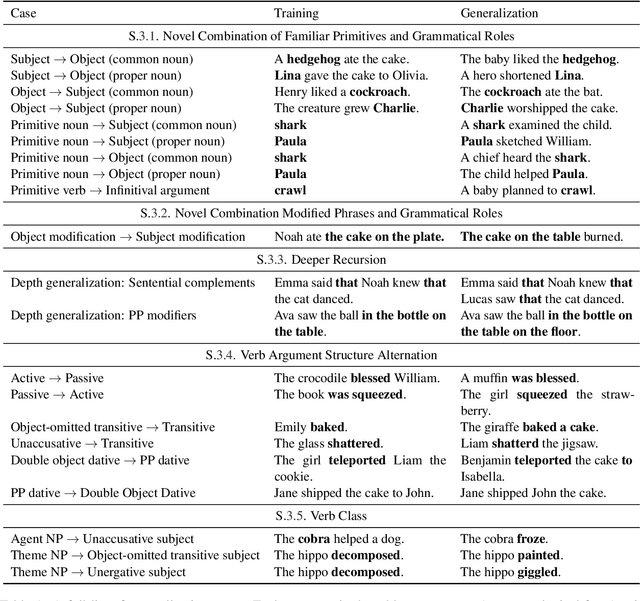
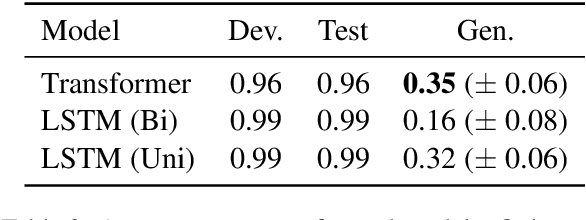
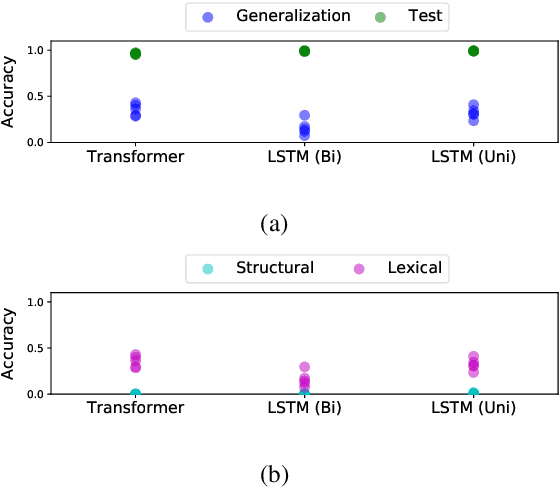
Natural language is characterized by compositionality: the meaning of a complex expression is constructed from the meanings of its constituent parts. To facilitate the evaluation of the compositional abilities of language processing architectures, we introduce COGS, a semantic parsing dataset based on a fragment of English. The evaluation portion of COGS contains multiple systematic gaps that can only be addressed by compositional generalization; these include new combinations of familiar syntactic structures, or new combinations of familiar words and familiar structures. In experiments with Transformers and LSTMs, we found that in-distribution accuracy on the COGS test set was near-perfect (96--99%), but generalization accuracy was substantially lower (16--35%) and showed high sensitivity to random seed ($\pm$6--8%). These findings indicate that contemporary standard NLP models are limited in their compositional generalization capacity, and position COGS as a good way to measure progress.
Universal linguistic inductive biases via meta-learning
Jun 29, 2020
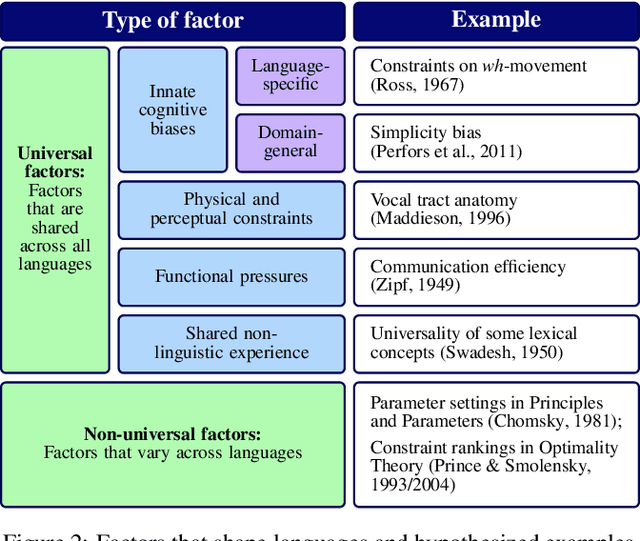

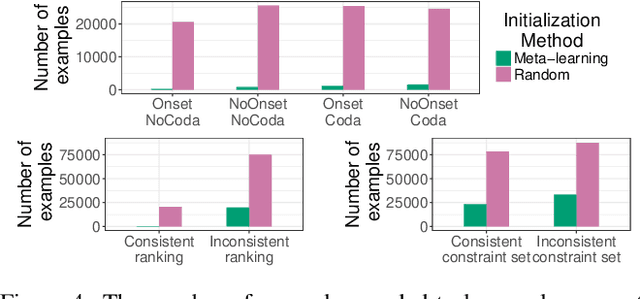
How do learners acquire languages from the limited data available to them? This process must involve some inductive biases - factors that affect how a learner generalizes - but it is unclear which inductive biases can explain observed patterns in language acquisition. To facilitate computational modeling aimed at addressing this question, we introduce a framework for giving particular linguistic inductive biases to a neural network model; such a model can then be used to empirically explore the effects of those inductive biases. This framework disentangles universal inductive biases, which are encoded in the initial values of a neural network's parameters, from non-universal factors, which the neural network must learn from data in a given language. The initial state that encodes the inductive biases is found with meta-learning, a technique through which a model discovers how to acquire new languages more easily via exposure to many possible languages. By controlling the properties of the languages that are used during meta-learning, we can control the inductive biases that meta-learning imparts. We demonstrate this framework with a case study based on syllable structure. First, we specify the inductive biases that we intend to give our model, and then we translate those inductive biases into a space of languages from which a model can meta-learn. Finally, using existing analysis techniques, we verify that our approach has imparted the linguistic inductive biases that it was intended to impart.
Cross-Linguistic Syntactic Evaluation of Word Prediction Models
May 21, 2020
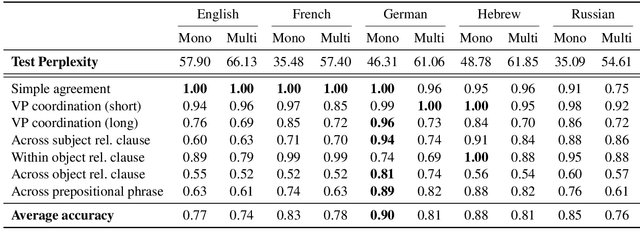
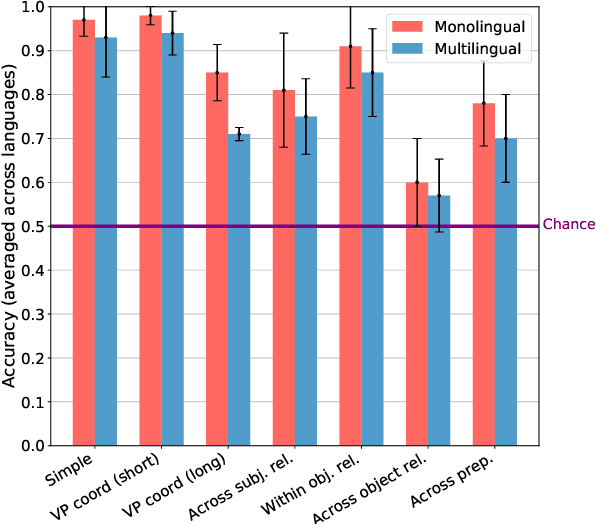
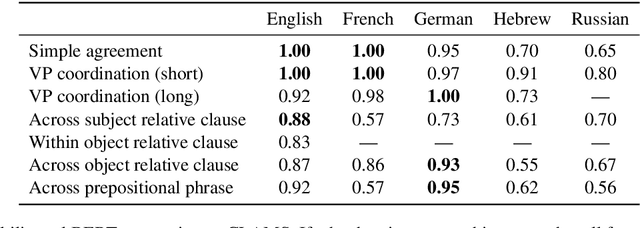
A range of studies have concluded that neural word prediction models can distinguish grammatical from ungrammatical sentences with high accuracy. However, these studies are based primarily on monolingual evidence from English. To investigate how these models' ability to learn syntax varies by language, we introduce CLAMS (Cross-Linguistic Assessment of Models on Syntax), a syntactic evaluation suite for monolingual and multilingual models. CLAMS includes subject-verb agreement challenge sets for English, French, German, Hebrew and Russian, generated from grammars we develop. We use CLAMS to evaluate LSTM language models as well as monolingual and multilingual BERT. Across languages, monolingual LSTMs achieved high accuracy on dependencies without attractors, and generally poor accuracy on agreement across object relative clauses. On other constructions, agreement accuracy was generally higher in languages with richer morphology. Multilingual models generally underperformed monolingual models. Multilingual BERT showed high syntactic accuracy on English, but noticeable deficiencies in other languages.
How Can We Accelerate Progress Towards Human-like Linguistic Generalization?
May 03, 2020This position paper describes and critiques the Pretraining-Agnostic Identically Distributed (PAID) evaluation paradigm, which has become a central tool for measuring progress in natural language understanding. This paradigm consists of three stages: (1) pre-training of a word prediction model on a corpus of arbitrary size; (2) fine-tuning (transfer learning) on a training set representing a classification task; (3) evaluation on a test set drawn from the same distribution as that training set. This paradigm favors simple, low-bias architectures, which, first, can be scaled to process vast amounts of data, and second, can capture the fine-grained statistical properties of a particular data set, regardless of whether those properties are likely to generalize to examples of the task outside the data set. This contrasts with humans, who learn language from several orders of magnitude less data than the systems favored by this evaluation paradigm, and generalize to new tasks in a consistent way. We advocate for supplementing or replacing PAID with paradigms that reward architectures that generalize as quickly and robustly as humans.
Representations of Syntax [MASK] Useful: Effects of Constituency and Dependency Structure in Recursive LSTMs
Apr 30, 2020![Figure 1 for Representations of Syntax [MASK] Useful: Effects of Constituency and Dependency Structure in Recursive LSTMs](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F25316018268ed68c7096fe8b2d8fbd66f998a201%2F1-Table1-1.png&w=640&q=75)
![Figure 2 for Representations of Syntax [MASK] Useful: Effects of Constituency and Dependency Structure in Recursive LSTMs](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F25316018268ed68c7096fe8b2d8fbd66f998a201%2F3-Figure1-1.png&w=640&q=75)
![Figure 3 for Representations of Syntax [MASK] Useful: Effects of Constituency and Dependency Structure in Recursive LSTMs](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F25316018268ed68c7096fe8b2d8fbd66f998a201%2F9-Figure2-1.png&w=640&q=75)
![Figure 4 for Representations of Syntax [MASK] Useful: Effects of Constituency and Dependency Structure in Recursive LSTMs](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F25316018268ed68c7096fe8b2d8fbd66f998a201%2F11-Table2-1.png&w=640&q=75)
Sequence-based neural networks show significant sensitivity to syntactic structure, but they still perform less well on syntactic tasks than tree-based networks. Such tree-based networks can be provided with a constituency parse, a dependency parse, or both. We evaluate which of these two representational schemes more effectively introduces biases for syntactic structure that increase performance on the subject-verb agreement prediction task. We find that a constituency-based network generalizes more robustly than a dependency-based one, and that combining the two types of structure does not yield further improvement. Finally, we show that the syntactic robustness of sequential models can be substantially improved by fine-tuning on a small amount of constructed data, suggesting that data augmentation is a viable alternative to explicit constituency structure for imparting the syntactic biases that sequential models are lacking.
Syntactic Data Augmentation Increases Robustness to Inference Heuristics
Apr 24, 2020
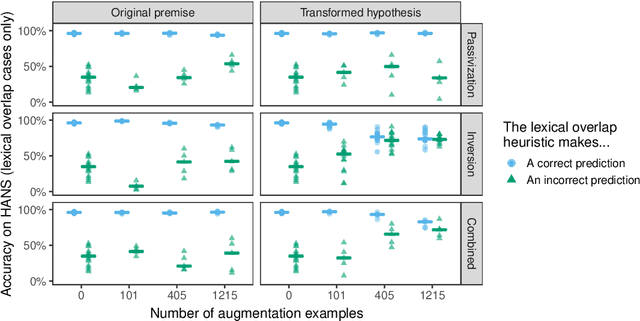
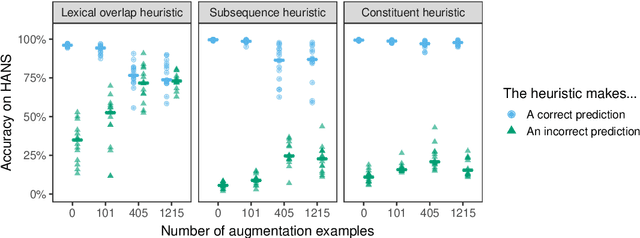

Pretrained neural models such as BERT, when fine-tuned to perform natural language inference (NLI), often show high accuracy on standard datasets, but display a surprising lack of sensitivity to word order on controlled challenge sets. We hypothesize that this issue is not primarily caused by the pretrained model's limitations, but rather by the paucity of crowdsourced NLI examples that might convey the importance of syntactic structure at the fine-tuning stage. We explore several methods to augment standard training sets with syntactically informative examples, generated by applying syntactic transformations to sentences from the MNLI corpus. The best-performing augmentation method, subject/object inversion, improved BERT's accuracy on controlled examples that diagnose sensitivity to word order from 0.28 to 0.73, without affecting performance on the MNLI test set. This improvement generalized beyond the particular construction used for data augmentation, suggesting that augmentation causes BERT to recruit abstract syntactic representations.
Syntactic Structure from Deep Learning
Apr 22, 2020Modern deep neural networks achieve impressive performance in engineering applications that require extensive linguistic skills, such as machine translation. This success has sparked interest in probing whether these models are inducing human-like grammatical knowledge from the raw data they are exposed to, and, consequently, whether they can shed new light on long-standing debates concerning the innate structure necessary for language acquisition. In this article, we survey representative studies of the syntactic abilities of deep networks, and discuss the broader implications that this work has for theoretical linguistics.
Does syntax need to grow on trees? Sources of hierarchical inductive bias in sequence-to-sequence networks
Jan 10, 2020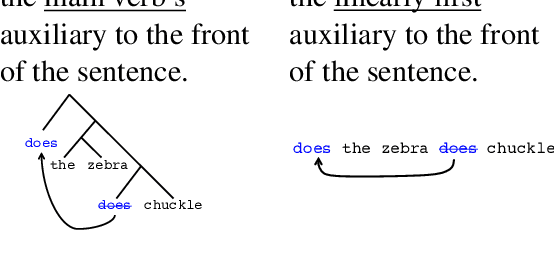

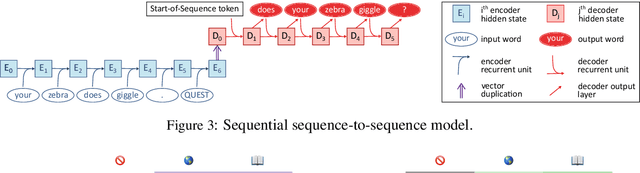

Learners that are exposed to the same training data might generalize differently due to differing inductive biases. In neural network models, inductive biases could in theory arise from any aspect of the model architecture. We investigate which architectural factors affect the generalization behavior of neural sequence-to-sequence models trained on two syntactic tasks, English question formation and English tense reinflection. For both tasks, the training set is consistent with a generalization based on hierarchical structure and a generalization based on linear order. All architectural factors that we investigated qualitatively affected how models generalized, including factors with no clear connection to hierarchical structure. For example, LSTMs and GRUs displayed qualitatively different inductive biases. However, the only factor that consistently contributed a hierarchical bias across tasks was the use of a tree-structured model rather than a model with sequential recurrence, suggesting that human-like syntactic generalization requires architectural syntactic structure.