 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Embeddings: A Similarity-based Approach to Automatic Performance Optimization
Mar 14, 2023



Performance optimization is an increasingly challenging but often repetitive task. While each platform has its quirks, the underlying code transformations rely on data movement and computational characteristics that recur across applications. This paper proposes to leverage those similarities by constructing an embedding space for subprograms. The continuous space captures both static and dynamic properties of loop nests via symbolic code analysis and performance profiling, respectively. Performance embeddings enable direct knowledge transfer of performance tuning between applications, which can result from autotuning or tailored improvements. We demonstrate this transfer tuning approach on case studies in deep neural networks, dense and sparse linear algebra compositions, and numerical weather prediction stencils. Transfer tuning reduces the search complexity by up to four orders of magnitude and outperforms the MKL library in sparse-dense matrix multiplication. The results exhibit clear correspondences between program characteristics and optimizations, outperforming prior specialized state-of-the-art approaches and generalizing beyond their capabilities.
A Theory of I/O-Efficient Sparse Neural Network Inference
Jan 03, 2023



As the accuracy of machine learning models increases at a fast rate, so does their demand for energy and compute resources. On a low level, the major part of these resources is consumed by data movement between different memory units. Modern hardware architectures contain a form of fast memory (e.g., cache, registers), which is small, and a slow memory (e.g., DRAM), which is larger but expensive to access. We can only process data that is stored in fast memory, which incurs data movement (input/output-operations, or I/Os) between the two units. In this paper, we provide a rigorous theoretical analysis of the I/Os needed in sparse feedforward neural network (FFNN) inference. We establish bounds that determine the optimal number of I/Os up to a factor of 2 and present a method that uses a number of I/Os within that range. Much of the I/O-complexity is determined by a few high-level properties of the FFNN (number of inputs, outputs, neurons, and connections), but if we want to get closer to the exact lower bound, the instance-specific sparsity patterns need to be considered. Departing from the 2-optimal computation strategy, we show how to reduce the number of I/Os further with simulated annealing. Complementing this result, we provide an algorithm that constructively generates networks with maximum I/O-efficiency for inference. We test the algorithms and empirically verify our theoretical and algorithmic contributions. In our experiments on real hardware we observe speedups of up to 45$\times$ relative to the standard way of performing inference.
ENS-10: A Dataset For Post-Processing Ensemble Weather Forecast
Jun 29, 2022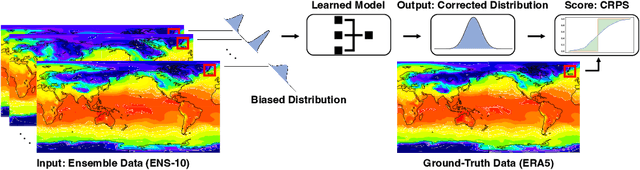
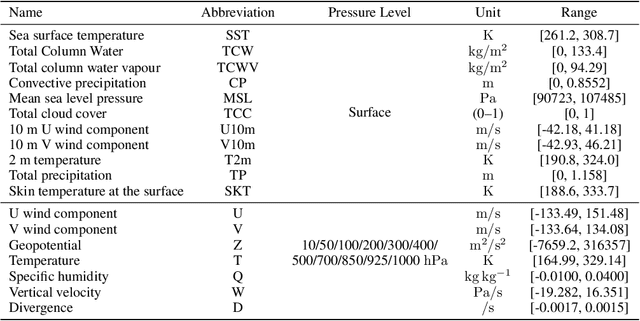
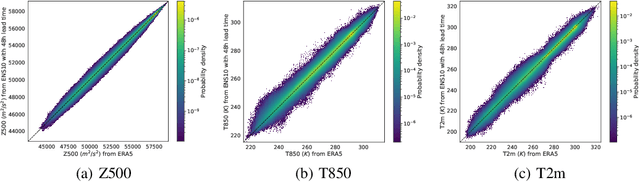
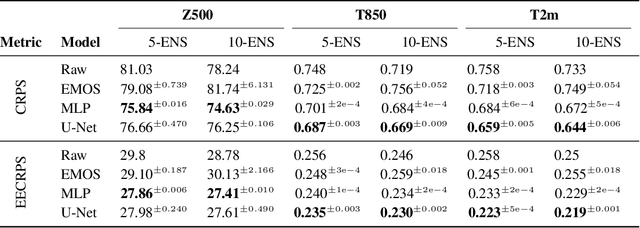
Post-processing ensemble prediction systems can improve weather forecasting, especially for extreme event prediction. In recent years, different machine learning models have been developed to improve the quality of the post-processing step. However, these models heavily rely on the data and generating such ensemble members requires multiple runs of numerical weather prediction models, at high computational cost. This paper introduces the ENS-10 dataset, consisting of ten ensemble members spread over 20 years (1998-2017). The ensemble members are generated by perturbing numerical weather simulations to capture the chaotic behavior of the Earth. To represent the three-dimensional state of the atmosphere, ENS-10 provides the most relevant atmospheric variables in 11 distinct pressure levels as well as the surface at 0.5-degree resolution. The dataset targets the prediction correction task at 48-hour lead time, which is essentially improving the forecast quality by removing the biases of the ensemble members. To this end, ENS-10 provides the weather variables for forecast lead times T=0, 24, and 48 hours (two data points per week). We provide a set of baselines for this task on ENS-10 and compare their performance in correcting the prediction of different weather variables. We also assess our baselines for predicting extreme events using our dataset. The ENS-10 dataset is available under the Creative Commons Attribution 4.0 International (CC BY 4.0) licence.
A Data-Centric Optimization Framework for Machine Learning
Oct 20, 2021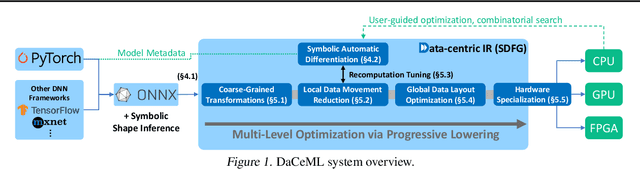
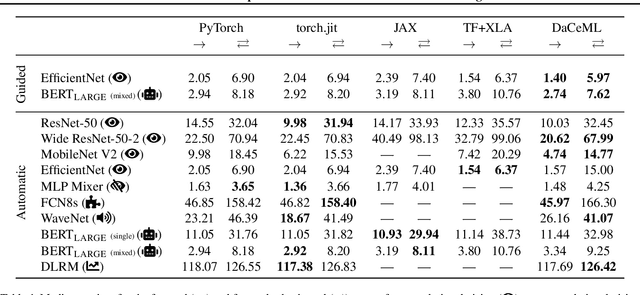
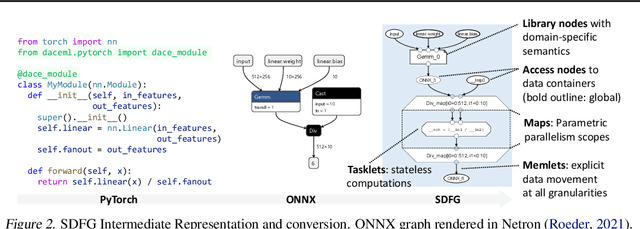
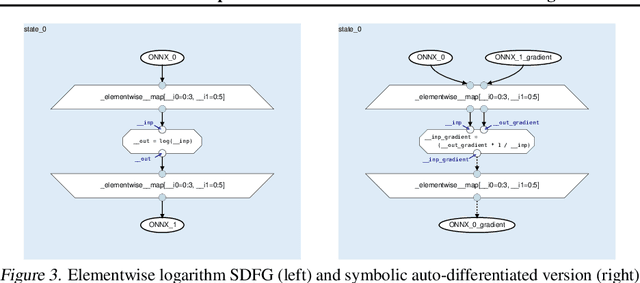
Rapid progress in deep learning is leading to a diverse set of quickly changing models, with a dramatically growing demand for compute. However, as frameworks specialize optimization to patterns in popular networks, they implicitly constrain novel and diverse models that drive progress in research. We empower deep learning researchers by defining a flexible and user-customizable pipeline for optimizing training of arbitrary deep neural networks, based on data movement minimization. The pipeline begins with standard networks in PyTorch or ONNX and transforms computation through progressive lowering. We define four levels of general-purpose transformations, from local intra-operator optimizations to global data movement reduction. These operate on a data-centric graph intermediate representation that expresses computation and data movement at all levels of abstraction, including expanding basic operators such as convolutions to their underlying computations. Central to the design is the interactive and introspectable nature of the pipeline. Every part is extensible through a Python API, and can be tuned interactively using a GUI. We demonstrate competitive performance or speedups on ten different networks, with interactive optimizations discovering new opportunities in EfficientNet.
Learning Combinatorial Node Labeling Algorithms
Jun 15, 2021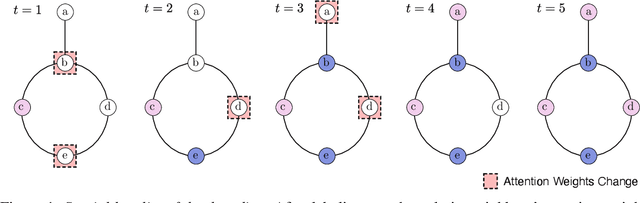
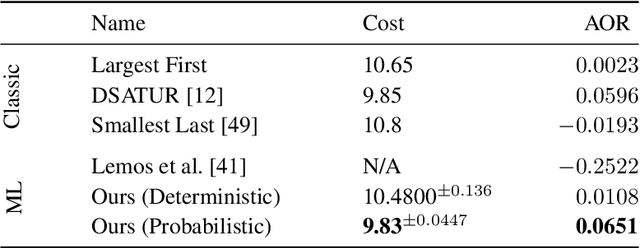
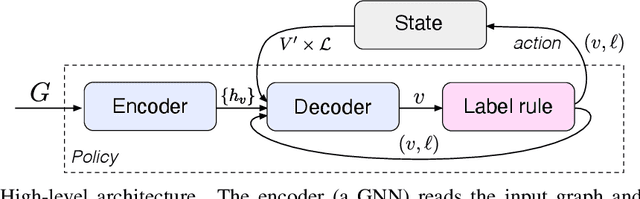

We present a graph neural network to learn graph coloring heuristics using reinforcement learning. Our learned deterministic heuristics give better solutions than classical degree-based greedy heuristics and only take seconds to evaluate on graphs with tens of thousands of vertices. As our approach is based on policy-gradients, it also learns a probabilistic policy as well. These probabilistic policies outperform all greedy coloring baselines and a machine learning baseline. Our approach generalizes several previous machine-learning frameworks, which applied to problems like minimum vertex cover. We also demonstrate that our approach outperforms two greedy heuristics on minimum vertex cover.
Sparsity in Deep Learning: Pruning and growth for efficient inference and training in neural networks
Jan 31, 2021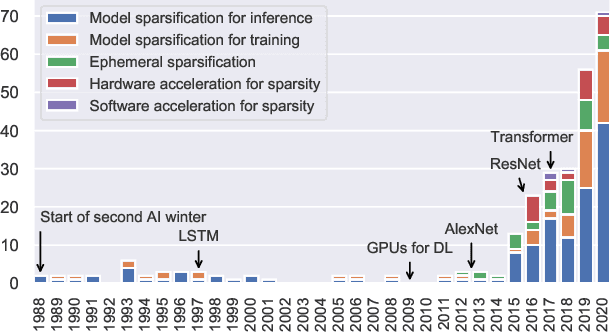
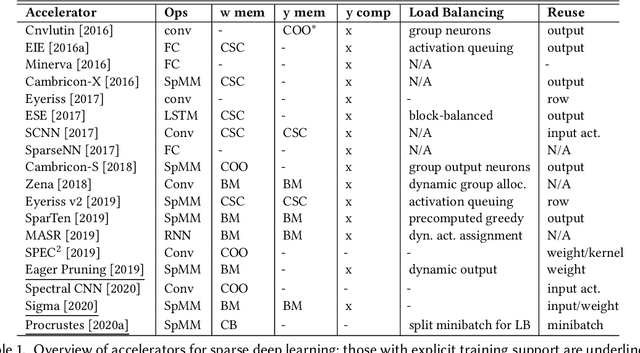
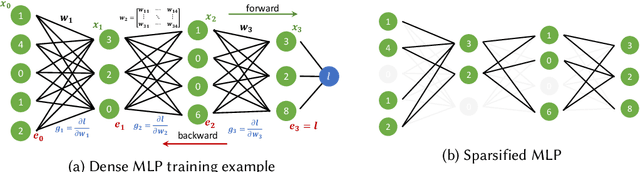
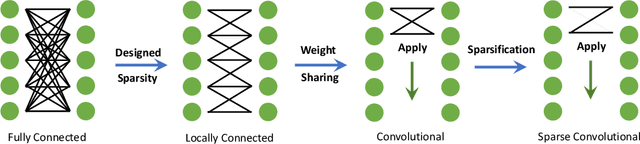
The growing energy and performance costs of deep learning have driven the community to reduce the size of neural networks by selectively pruning components. Similarly to their biological counterparts, sparse networks generalize just as well, if not better than, the original dense networks. Sparsity can reduce the memory footprint of regular networks to fit mobile devices, as well as shorten training time for ever growing networks. In this paper, we survey prior work on sparsity in deep learning and provide an extensive tutorial of sparsification for both inference and training. We describe approaches to remove and add elements of neural networks, different training strategies to achieve model sparsity, and mechanisms to exploit sparsity in practice. Our work distills ideas from more than 300 research papers and provides guidance to practitioners who wish to utilize sparsity today, as well as to researchers whose goal is to push the frontier forward. We include the necessary background on mathematical methods in sparsification, describe phenomena such as early structure adaptation, the intricate relations between sparsity and the training process, and show techniques for achieving acceleration on real hardware. We also define a metric of pruned parameter efficiency that could serve as a baseline for comparison of different sparse networks. We close by speculating on how sparsity can improve future workloads and outline major open problems in the field.
Clairvoyant Prefetching for Distributed Machine Learning I/O
Jan 21, 2021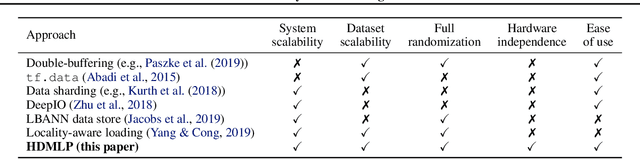
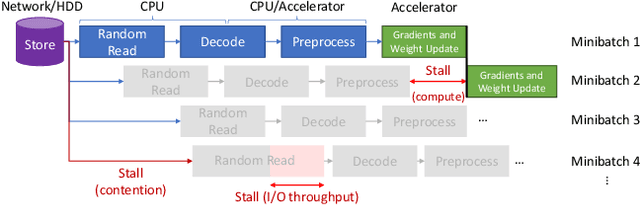
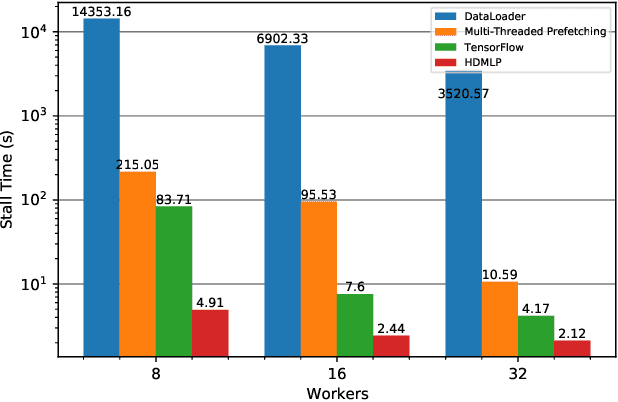
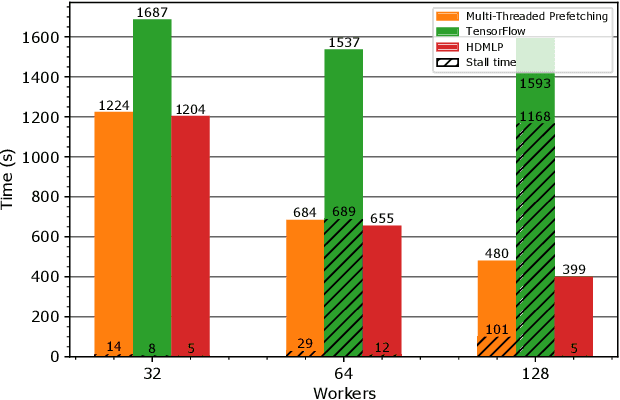
I/O is emerging as a major bottleneck for machine learning training, especially in distributed environments such as clouds and supercomputers. Optimal data ingestion pipelines differ between systems, and increasing efficiency requires a delicate balance between access to local storage, external filesystems, and remote workers; yet existing frameworks fail to efficiently utilize such resources. We observe that, given the seed generating the random access pattern for training with SGD, we have clairvoyance and can exactly predict when a given sample will be accessed. We combine this with a theoretical analysis of access patterns in training and performance modeling to produce a novel machine learning I/O middleware, HDMLP, to tackle the I/O bottleneck. HDMLP provides an easy-to-use, flexible, and scalable solution that delivers better performance than state-of-the-art approaches while requiring very few changes to existing codebases and supporting a broad range of environments.
Deep Data Flow Analysis
Nov 21, 2020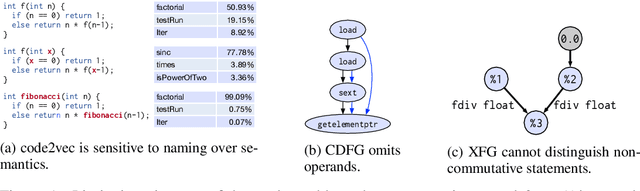

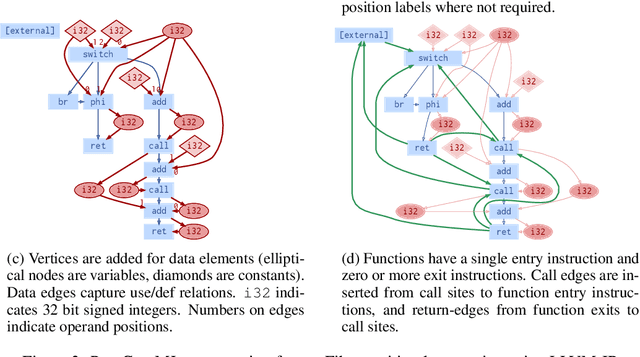
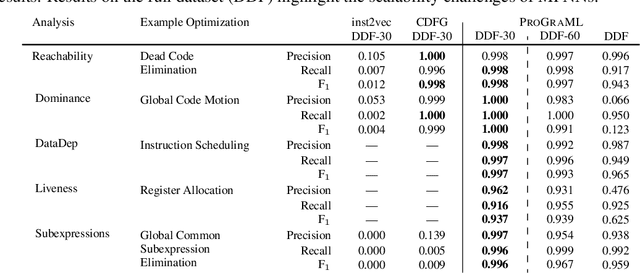
Compiler architects increasingly look to machine learning when building heuristics for compiler optimization. The promise of automatic heuristic design, freeing the compiler engineer from the complex interactions of program, architecture, and other optimizations, is alluring. However, most machine learning methods cannot replicate even the simplest of the abstract interpretations of data flow analysis that are critical to making good optimization decisions. This must change for machine learning to become the dominant technology in compiler heuristics. To this end, we propose ProGraML - Program Graphs for Machine Learning - a language-independent, portable representation of whole-program semantics for deep learning. To benchmark current and future learning techniques for compiler analyses we introduce an open dataset of 461k Intermediate Representation (IR) files for LLVM, covering five source programming languages, and 15.4M corresponding data flow results. We formulate data flow analysis as an MPNN and show that, using ProGraML, standard analyses can be learned, yielding improved performance on downstream compiler optimization tasks.
Data Movement Is All You Need: A Case Study on Optimizing Transformers
Jul 02, 2020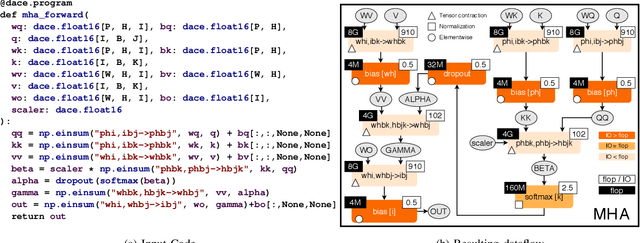
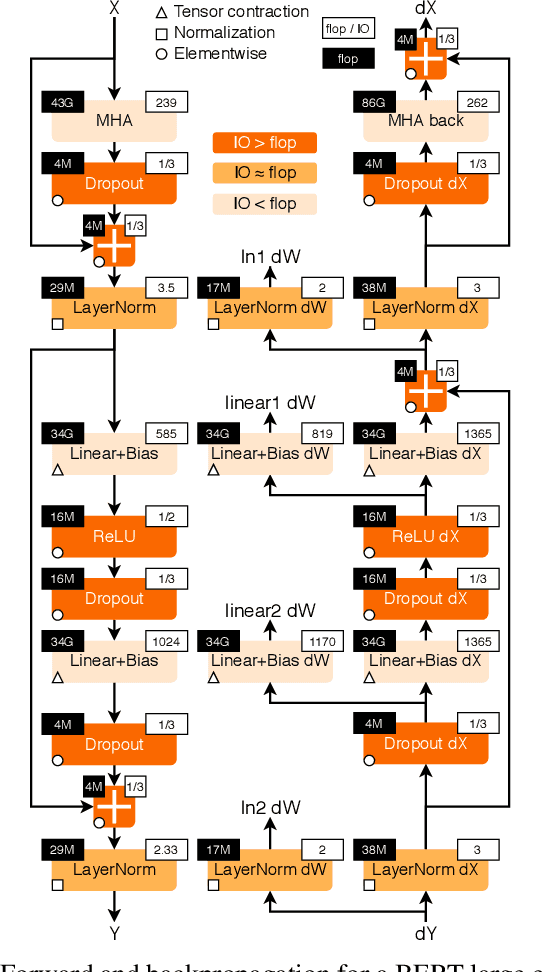
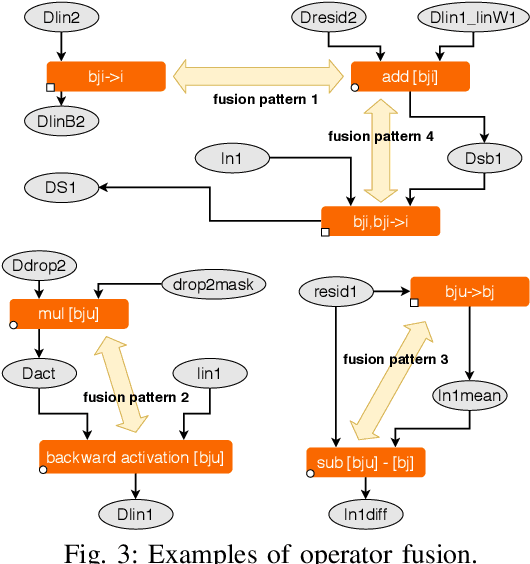
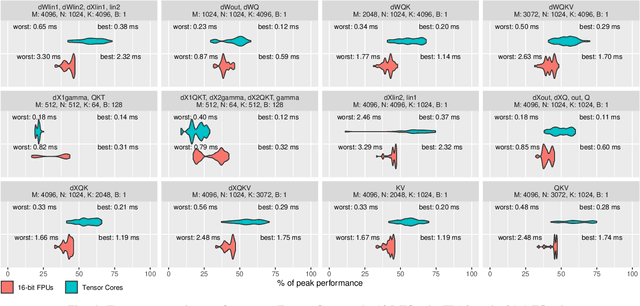
Transformers have become widely used for language modeling and sequence learning tasks, and are one of the most important machine learning workloads today. Training one is a very compute-intensive task, often taking days or weeks, and significant attention has been given to optimizing transformers. Despite this, existing implementations do not efficiently utilize GPUs. We find that data movement is the key bottleneck when training. Due to Amdahl's Law and massive improvements in compute performance, training has now become memory-bound. Further, existing frameworks use suboptimal data layouts. Using these insights, we present a recipe for globally optimizing data movement in transformers. We reduce data movement by up to 22.91% and overall achieve a 1.30x performance improvement over state-of-the-art frameworks when training BERT. Our approach is applicable more broadly to optimizing deep neural networks, and offers insight into how to tackle emerging performance bottlenecks.
Deep Learning for Post-Processing Ensemble Weather Forecasts
May 18, 2020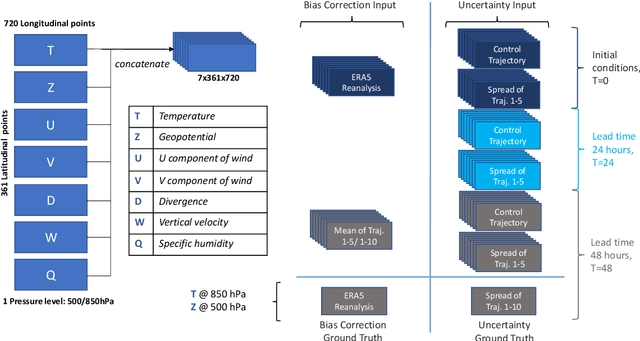

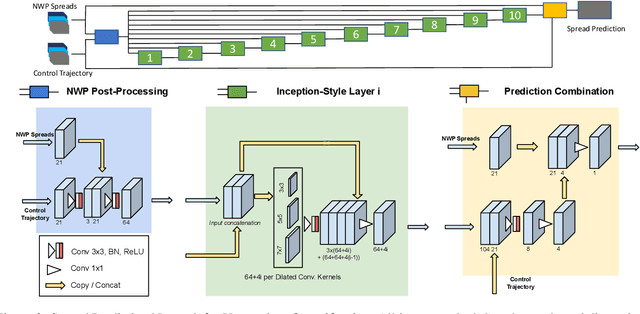

Quantifying uncertainty in weather forecasts typically employs ensemble prediction systems, which consist of many perturbed trajectories run in parallel. These systems are associated with a high computational cost and often include statistical post-processing steps to inexpensively improve their raw prediction qualities. We propose a mixed prediction and post-processing model based on a subset of the original trajectories. In the model, we implement methods from deep learning to account for non-linear relationships that are not captured by current numerical models or other post-processing methods. Applied to global data, our mixed models achieve a relative improvement of the ensemble forecast skill of over 13%. We demonstrate that this is especially the case for extreme weather events on selected case studies, where we see an improvement in predictions by up to 26%. In addition, by using only half the trajectories, the computational costs of ensemble prediction systems can potentially be reduced, allowing weather forecasting pipelines to run higher resolution trajectories, and resulting in even more accurate raw ensemble forecasts.