 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoramic Image-to-Image Translation
Apr 11, 2023



In this paper, we tackle the challenging task of Panoramic Image-to-Image translation (Pano-I2I) for the first time. This task is difficult due to the geometric distortion of panoramic images and the lack of a panoramic image dataset with diverse conditions, like weather or time. To address these challenges, we propose a panoramic distortion-aware I2I model that preserves the structure of the panoramic images while consistently translating their global style referenced from a pinhole image. To mitigate the distortion issue in naive 360 panorama translation, we adopt spherical positional embedding to our transformer encoders, introduce a distortion-free discriminator, and apply sphere-based rotation for augmentation and its ensemble. We also design a content encoder and a style encoder to be deformation-aware to deal with a large domain gap between panoramas and pinhole images, enabling us to work on diverse conditions of pinhole images. In addition, considering the large discrepancy between panoramas and pinhole images, our framework decouples the learning procedure of the panoramic reconstruction stage from the translation stage. We show distinct improvements over existing I2I models in translating the StreetLearn dataset in the daytime into diverse conditions. The code will be publicly available online for our community.
Robust Camera Pose Refinement for Multi-Resolution Hash Encoding
Feb 03, 2023



Multi-resolution hash encoding has recently been proposed to reduce the computational cost of neural renderings, such as NeRF. This method requires accurate camera poses for the neural renderings of given scenes. However, contrary to previous methods jointly optimizing camera poses and 3D scenes, the naive gradient-based camera pose refinement method using multi-resolution hash encoding severely deteriorates performance. We propose a joint optimization algorithm to calibrate the camera pose and learn a geometric representation using efficient multi-resolution hash encoding. Showing that the oscillating gradient flows of hash encoding interfere with the registration of camera poses, our method addresses the issue by utilizing smooth interpolation weighting to stabilize the gradient oscillation for the ray samplings across hash grids. Moreover, the curriculum training procedure helps to learn the level-wise hash encoding, further increasing the pose refinement. Experiments on the novel-view synthesis datasets validate that our learning frameworks achieve state-of-the-art performance and rapid convergence of neural rendering, even when initial camera poses are unknown.
Uncertainty Reduction for 3D Point Cloud Self-Supervised Traversability Estimation
Nov 21, 2022



Traversability estimation in off-road environments requires a robust perception system. Recently, approaches to learning a traversability estimation from past vehicle experiences in a self-supervised manner are arising as they can greatly reduce human labeling costs and labeling errors. Nonetheless, the learning setting from self-supervised traversability estimation suffers from congenital uncertainties that appear according to the scarcity of negative information. Negative data are rarely harvested as the system can be severely damaged while logging the data. To mitigate the uncertainty, we introduce a method to incorporate unlabeled data in order to leverage the uncertainty. First, we design a learning architecture that inputs query and support data. Second, unlabeled data are assigned based on the proximity in the metric space. Third, a new metric for uncertainty measures is introduced. We evaluated our approach on our own dataset, `Dtrail', which is composed of a wide variety of negative data.
ScaTE: A Scalable Framework for Self-Supervised Traversability Estimation in Unstructured Environments
Sep 14, 2022

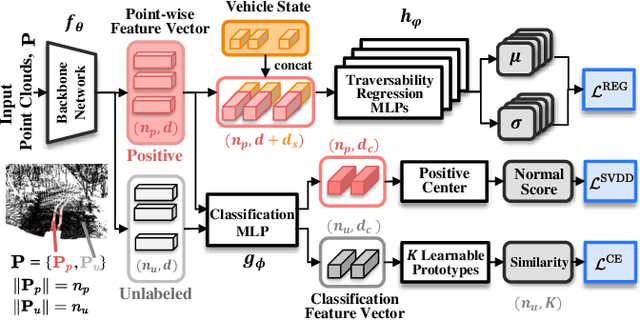

For the safe and successful navigation of autonomous vehicles in unstructured environments, the traversability of terrain should vary based on the driving capabilities of the vehicles. Actual driving experience can be utilized in a self-supervised fashion to learn vehicle-specific traversability. However, existing methods for learning self-supervised traversability are not highly scalable for learning the traversability of various vehicles. In this work, we introduce a scalable framework for learning self-supervised traversability, which can learn the traversability directly from vehicle-terrain interaction without any human supervision. We train a neural network that predicts the proprioceptive experience that a vehicle would undergo from 3D point clouds. Using a novel PU learning method, the network simultaneously identifies non-traversable regions where estimations can be overconfident. With driving data of various vehicles gathered from simulation and the real world, we show that our framework is capable of learning the self-supervised traversability of various vehicles. By integrating our framework with a model predictive controller, we demonstrate that estimated traversability results in effective navigation that enables distinct maneuvers based on the driving characteristics of the vehicles. In addition, experimental results validate the ability of our method to identify and avoid non-traversable regions.
Physics Embedded Neural Network Vehicle Model and Applications in Risk-Aware Autonomous Driving Using Latent Features
Jul 16, 2022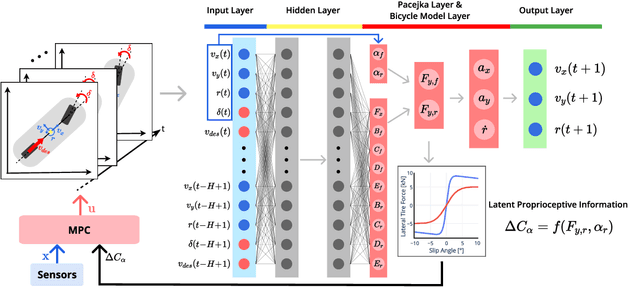
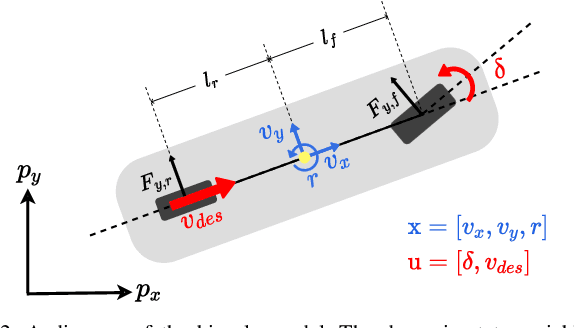
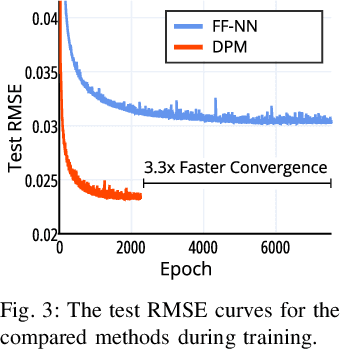
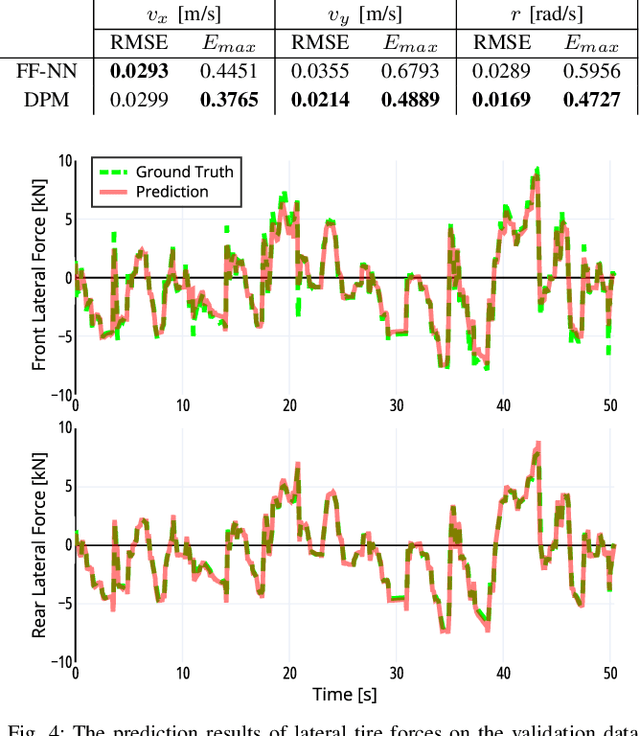
Non-holonomic vehicle motion has been studied extensively using physics-based models. Common approaches when using these models interpret the wheel/ground interactions using a linear tire model and thus may not fully capture the nonlinear and complex dynamics under various environments. On the other hand, neural network models have been widely employed in this domain, demonstrating powerful function approximation capabilities. However, these black-box learning strategies completely abandon the existing knowledge of well-known physics. In this paper, we seamlessly combine deep learning with a fully differentiable physics model to endow the neural network with available prior knowledge. The proposed model shows better generalization performance than the vanilla neural network model by a large margin. We also show that the latent features of our model can accurately represent lateral tire forces without the need for any additional training. Lastly, We develop a risk-aware model predictive controller using proprioceptive information derived from the latent features. We validate our idea in two autonomous driving tasks under unknown friction, outperforming the baseline control framework.
TOAST: Trajectory Optimization and Simultaneous Tracking using Shared Neural Network Dynamics
Jan 21, 2022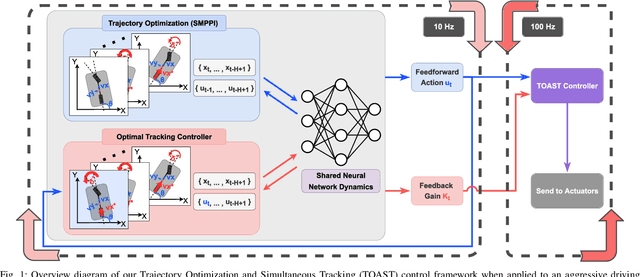
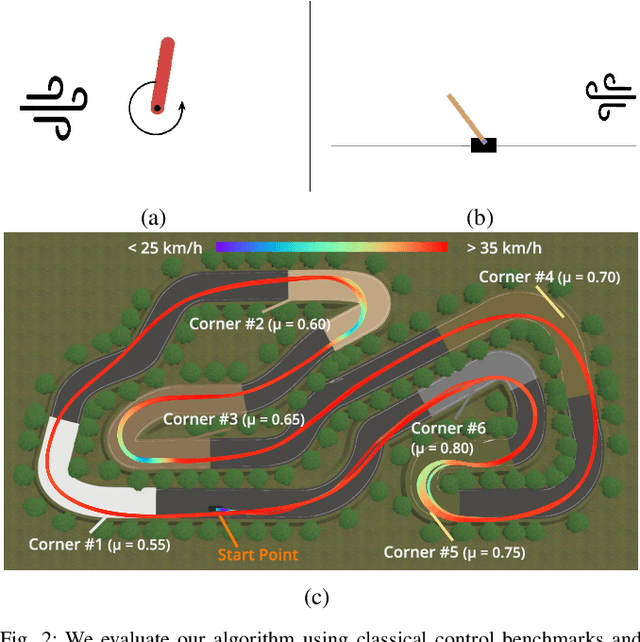
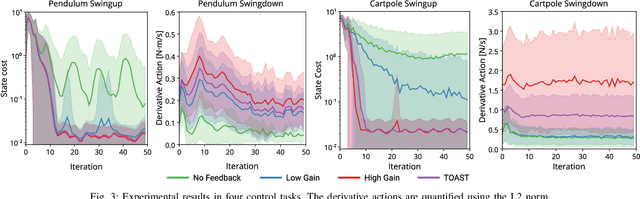
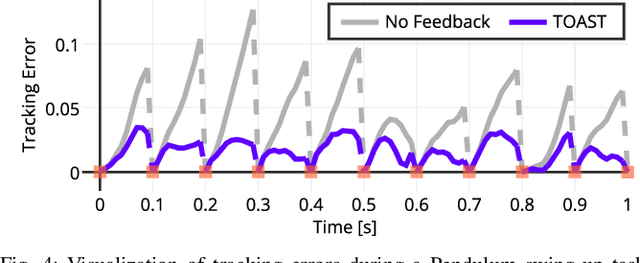
Neural networks have been increasingly employed in Model Predictive Controller (MPC) to control nonlinear dynamic systems. However, MPC still poses a problem that an achievable update rate is insufficient to cope with model uncertainty and external disturbances. In this paper, we present a novel control scheme that can design an optimal tracking controller using the neural network dynamics of the MPC, making it possible to be applied as a plug-and-play extension for any existing model-based feedforward controller. We also describe how our method handles a neural network containing historical information, which does not follow a general form of dynamics. The proposed method is evaluated by its performance in classical control benchmarks with external disturbances. We also extend our control framework to be applied in an aggressive autonomous driving task with unknown friction. In all experiments, our method outperformed the compared methods by a large margin. Our controller also showed low control chattering levels, demonstrating that our feedback controller does not interfere with the optimal command of MPC.
Derivative Action Control: Smooth Model Predictive Path Integral Control without Smoothing
Jan 13, 2022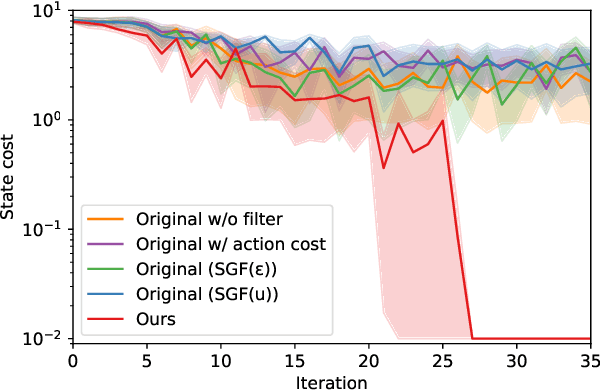
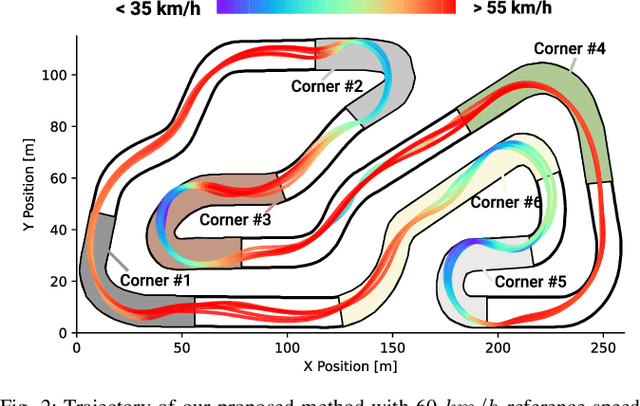
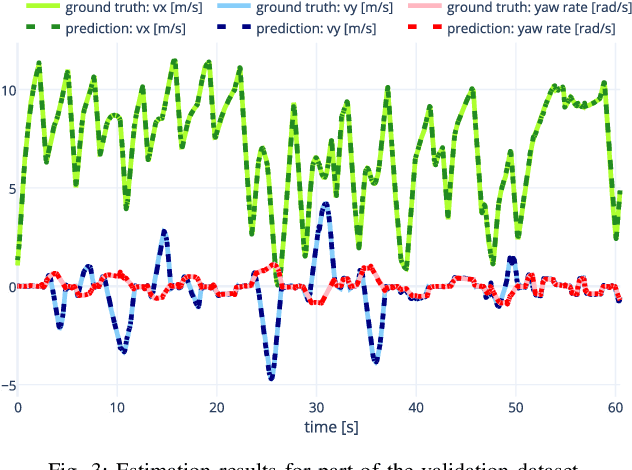
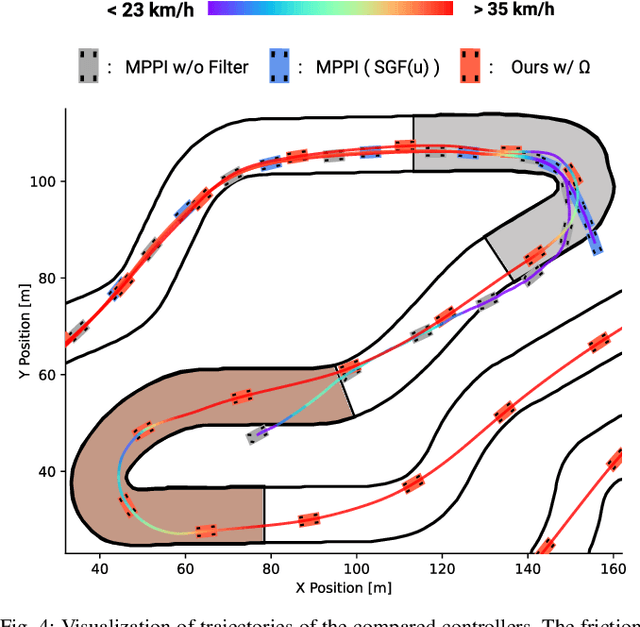
Here, we present a new approach to generate smooth control sequences in Model Predictive Path Integral control (MPPI) tasks without any additional smoothing algorithms. Our method effectively alleviates the chattering in sampling, while the information theoretic derivation of MPPI remains the same. We demonstrated the proposed method in a challenging autonomous driving task with quantitative evaluation of different algorithms. A neural network vehicle model for estimating system dynamics under varying road friction conditions is also presented. Our video can be found at: \url{https://youtu.be/o3Nmi0UJFqg}.
Residual-Guided Learning Representation for Self-Supervised Monocular Depth Estimation
Nov 08, 2021Photometric consistency loss is one of the representative objective functions commonly used for self-supervised monocular depth estimation. However, this loss often causes unstable depth predictions in textureless or occluded regions due to incorrect guidance. Recent self-supervised learning approaches tackle this issue by utilizing feature representations explicitly learned from auto-encoders, expecting better discriminability than the input image. Despite the use of auto-encoded features, we observe that the method does not embed features as discriminative as auto-encoded features. In this paper, we propose residual guidance loss that enables the depth estimation network to embed the discriminative feature by transferring the discriminability of auto-encoded features. We conducted experiments on the KITTI benchmark and verified our method's superiority and orthogonality on other state-of-the-art methods.
Real-Time Navigation System for a Low-Cost Mobile Robot with an RGB-D Camera
Mar 04, 2021


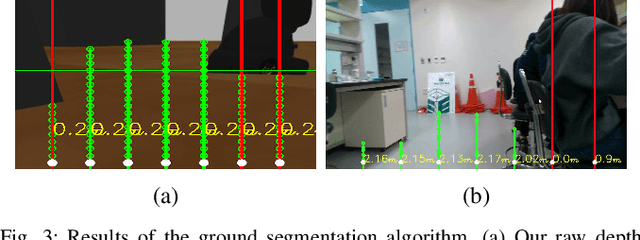
Currently, mobile robots are developing rapidly and are finding numerous applications in industry. However, there remain a number of problems related to their practical use, such as the need for expensive hardware and their high power consumption levels. In this study, we propose a navigation system that is operable on a low-end computer with an RGB-D camera and a mobile robot platform for the operation of an integrated autonomous driving system. The proposed system does not require LiDARs or a GPU. Our raw depth image ground segmentation approach extracts a traversability map for the safe driving of low-body mobile robots. It is designed to guarantee real-time performance on a low-cost commercial single board computer with integrated SLAM, global path planning, and motion planning. Running sensor data processing and other autonomous driving functions simultaneously, our navigation method performs rapidly at a refresh rate of 18Hz for control command, whereas other systems have slower refresh rates. Our method outperforms current state-of-the-art navigation approaches as shown in 3D simulation tests. In addition, we demonstrate the applicability of our mobile robot system through successful autonomous driving in a residential lobby.
Meta Batch-Instance Normalization for Generalizable Person Re-Identification
Nov 30, 2020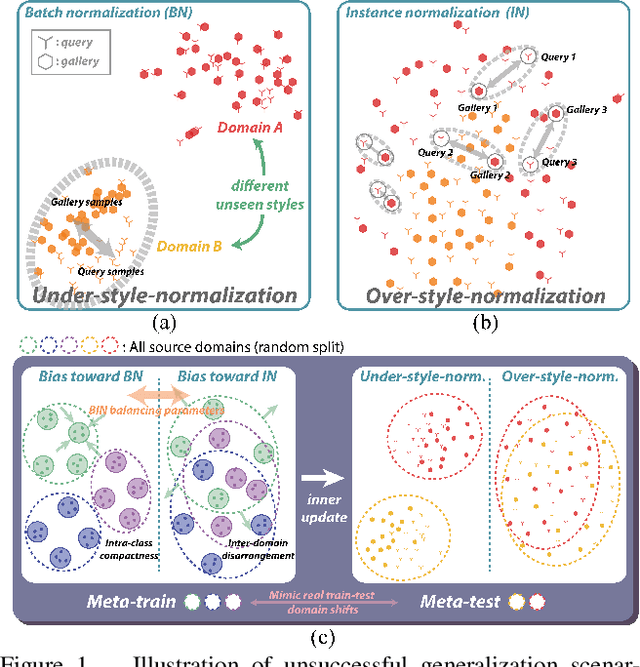
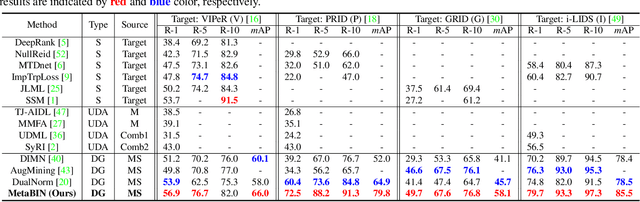
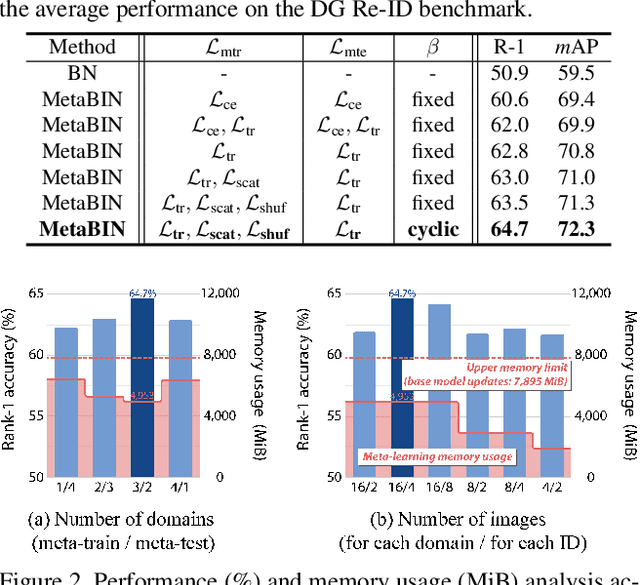
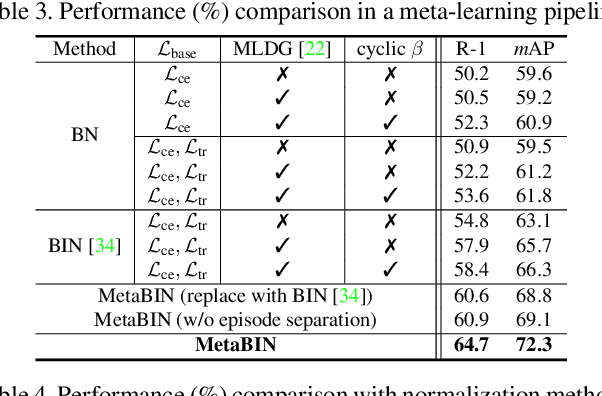
Although supervised person re-identification (Re-ID) methods have shown impressive performance, they suffer from a poor generalization capability on unseen domains. Therefore, generalizable Re-ID has recently attracted growing attention. Many existing methods have employed an instance normalization technique to reduce style variations, but the loss of discriminative information could not be avoided. In this paper, we propose a novel generalizable Re-ID framework, named Meta Batch-Instance Normalization (MetaBIN). Our main idea is to generalize normalization layers by simulating unsuccessful generalization scenarios beforehand in the meta-learning pipeline. To this end, we combine learnable batch-instance normalization layers with meta-learning and investigate the challenging cases caused by both batch and instance normalization layers. Moreover, we diversify the virtual simulations via our meta-train loss accompanied by a cyclic inner-updating manner to boost generalization capability. After all, the MetaBIN framework prevents our model from overfitting to the given source styles and improves the generalization capability to unseen domains without additional data augmentation or complicated network design. Extensive experimental results show that our model outperforms the state-of-the-art methods on the large-scale domain generalization Re-ID benchmark.