 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Contextual Multi-armed Bandits
Nov 22, 2022


Motivated by a range of applications, we study in this paper the problem of transfer learning for nonparametric contextual multi-armed bandits under the covariate shift model, where we have data collected on source bandits before the start of the target bandit learning. The minimax rate of convergence for the cumulative regret is established and a novel transfer learning algorithm that attains the minimax regret is proposed. The results quantify the contribution of the data from the source domains for learning in the target domain in the context of nonparametric contextual multi-armed bandits. In view of the general impossibility of adaptation to unknown smoothness, we develop a data-driven algorithm that achieves near-optimal statistical guarantees (up to a logarithmic factor) while automatically adapting to the unknown parameters over a large collection of parameter spaces under an additional self-similarity assumption. A simulation study is carried out to illustrate the benefits of utilizing the data from the auxiliary source domains for learning in the target domain.
Locally Adaptive Transfer Learning Algorithms for Large-Scale Multiple Testing
Mar 25, 2022


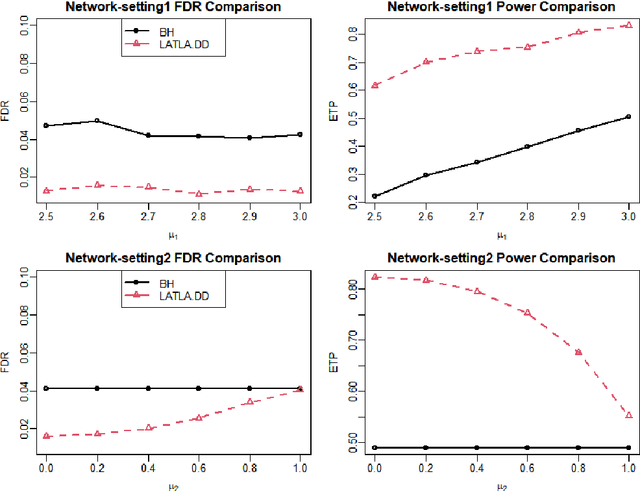
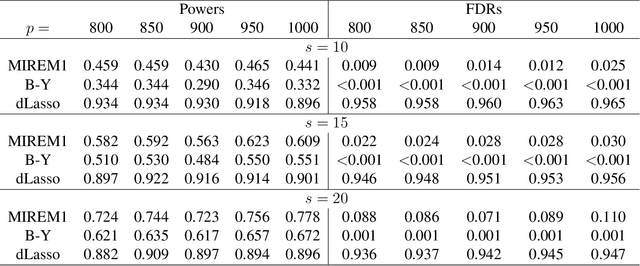
Transfer learning has enjoyed increasing popularity in a range of big data applications. In the context of large-scale multiple testing, the goal is to extract and transfer knowledge learned from related source domains to improve the accuracy of simultaneously testing of a large number of hypotheses in the target domain. This article develops a locally adaptive transfer learning algorithm (LATLA) for transfer learning for multiple testing. In contrast with existing covariate-assisted multiple testing methods that require the auxiliary covariates to be collected alongside the primary data on the same testing units, LATLA provides a principled and generic transfer learning framework that is capable of incorporating multiple samples of auxiliary data from related source domains, possibly in different dimensions/structures and from diverse populations. Both the theoretical and numerical results show that LATLA controls the false discovery rate and outperforms existing methods in power. LATLA is illustrated through an application to genome-wide association studies for the identification of disease-associated SNPs by cross-utilizing the auxiliary data from a related linkage analysis.
Matrix Reordering for Noisy Disordered Matrices: Optimality and Computationally Efficient Algorithms
Jan 17, 2022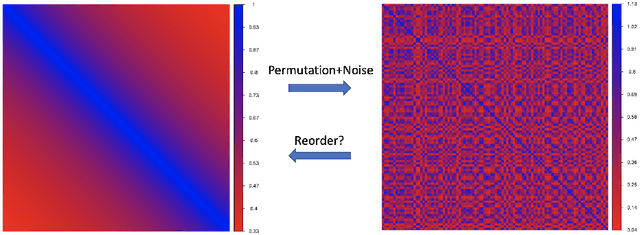
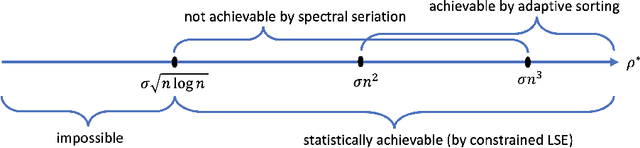
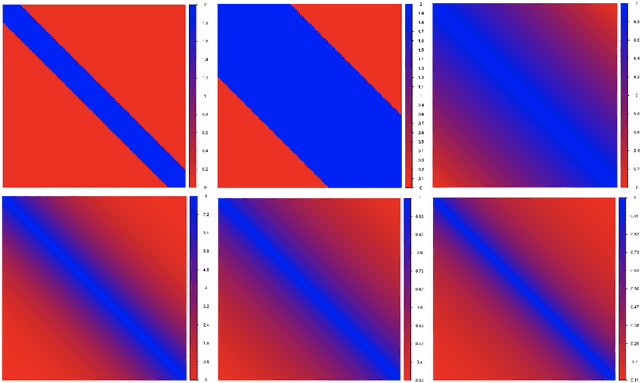
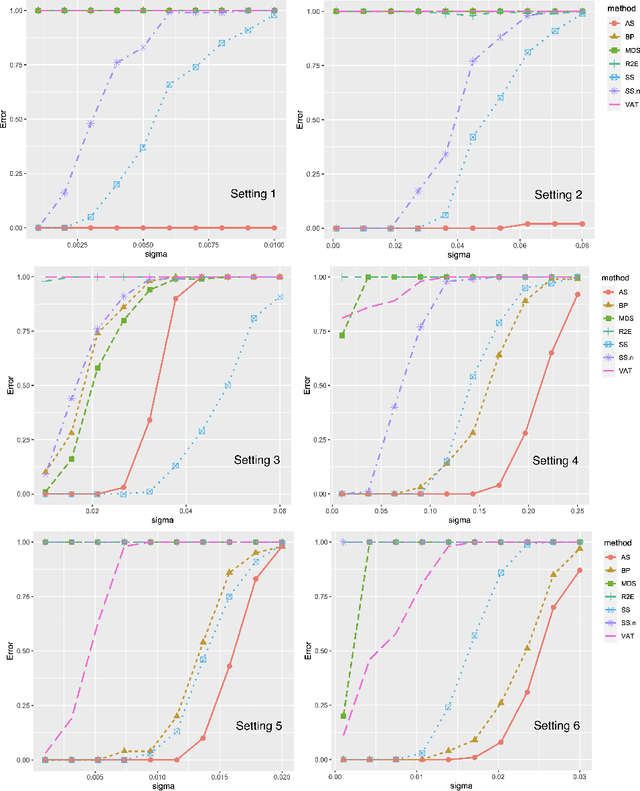
Motivated by applications in single-cell biology and metagenomics, we consider matrix reordering based on the noisy disordered matrix model. We first establish the fundamental statistical limit for the matrix reordering problem in a decision-theoretic framework and show that a constrained least square estimator is rate-optimal. Given the computational hardness of the optimal procedure, we analyze a popular polynomial-time algorithm, spectral seriation, and show that it is suboptimal. We then propose a novel polynomial-time adaptive sorting algorithm with guaranteed improvement on the performance. The superiority of the adaptive sorting algorithm over the existing methods is demonstrated in simulation studies and in the analysis of two real single-cell RNA sequencing datasets.
Distributed Nonparametric Function Estimation: Optimal Rate of Convergence and Cost of Adaptation
Jul 01, 2021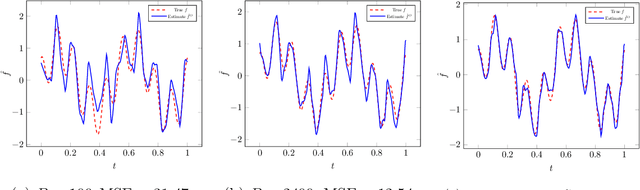
Distributed minimax estimation and distributed adaptive estimation under communication constraints for Gaussian sequence model and white noise model are studied. The minimax rate of convergence for distributed estimation over a given Besov class, which serves as a benchmark for the cost of adaptation, is established. We then quantify the exact communication cost for adaptation and construct an optimally adaptive procedure for distributed estimation over a range of Besov classes. The results demonstrate significant differences between nonparametric function estimation in the distributed setting and the conventional centralized setting. For global estimation, adaptation in general cannot be achieved for free in the distributed setting. The new technical tools to obtain the exact characterization for the cost of adaptation can be of independent interest.
Theoretical Foundations of t-SNE for Visualizing High-Dimensional Clustered Data
May 18, 2021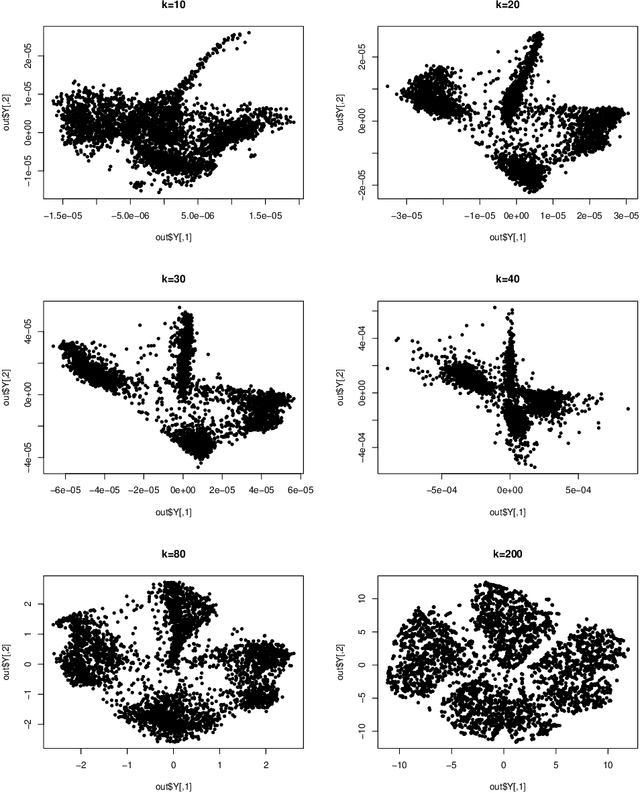
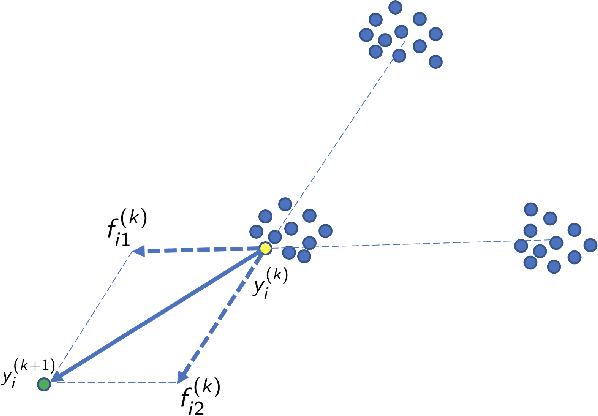
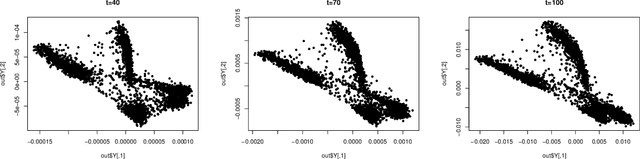
This study investigates the theoretical foundations of t-distributed stochastic neighbor embedding (t-SNE), a popular nonlinear dimension reduction and data visualization method. A novel theoretical framework for the analysis of t-SNE based on the gradient descent approach is presented. For the early exaggeration stage of t-SNE, we show its asymptotic equivalence to a power iteration based on the underlying graph Laplacian, characterize its limiting behavior, and uncover its deep connection to Laplacian spectral clustering, and fundamental principles including early stopping as implicit regularization. The results explain the intrinsic mechanism and the empirical benefits of such a computational strategy. For the embedding stage of t-SNE, we characterize the kinematics of the low-dimensional map throughout the iterations, and identify an amplification phase, featuring the intercluster repulsion and the expansive behavior of the low-dimensional map. The general theory explains the fast convergence rate and the exceptional empirical performance of t-SNE for visualizing clustered data, brings forth the interpretations of the t-SNE output, and provides theoretical guidance for selecting tuning parameters in various applications.
The Cost of Privacy in Generalized Linear Models: Algorithms and Minimax Lower Bounds
Nov 08, 2020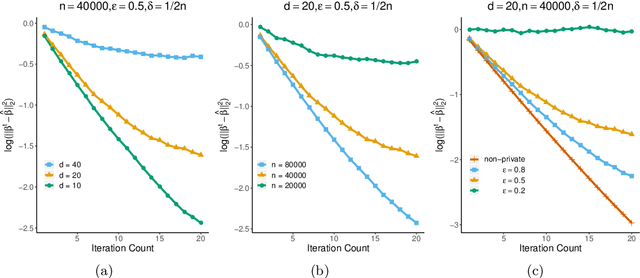
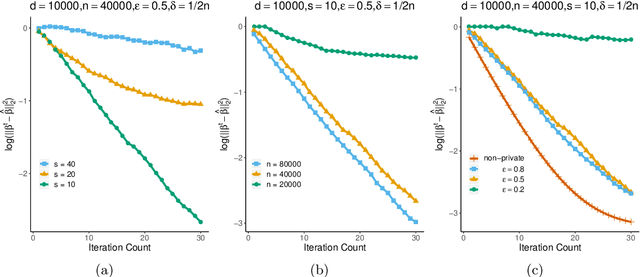

The trade-off between differential privacy and statistical accuracy in generalized linear models (GLMs) is studied. We propose differentially private algorithms for parameter estimation in both low-dimensional and high-dimensional sparse GLMs and characterize their statistical performance. We establish privacy-constrained minimax lower bounds for GLMs, which imply that the proposed algorithms are rate-optimal up to logarithmic factors in sample size. The lower bounds are obtained via a novel technique, which is based on Stein's Lemma and generalizes the tracing attack technique for privacy-constrained lower bounds. This lower bound argument can be of independent interest as it is applicable to general parametric models. Simulated and real data experiments are conducted to demonstrate the numerical performance of our algorithms.
Estimation, Confidence Intervals, and Large-Scale Hypotheses Testing for High-Dimensional Mixed Linear Regression
Nov 06, 2020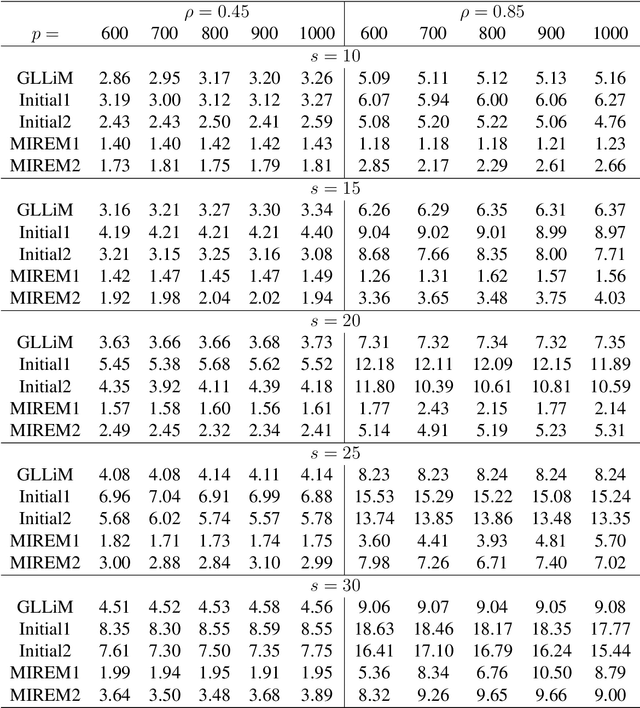
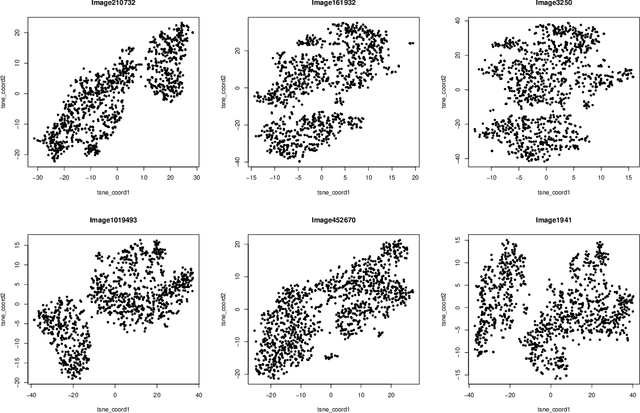
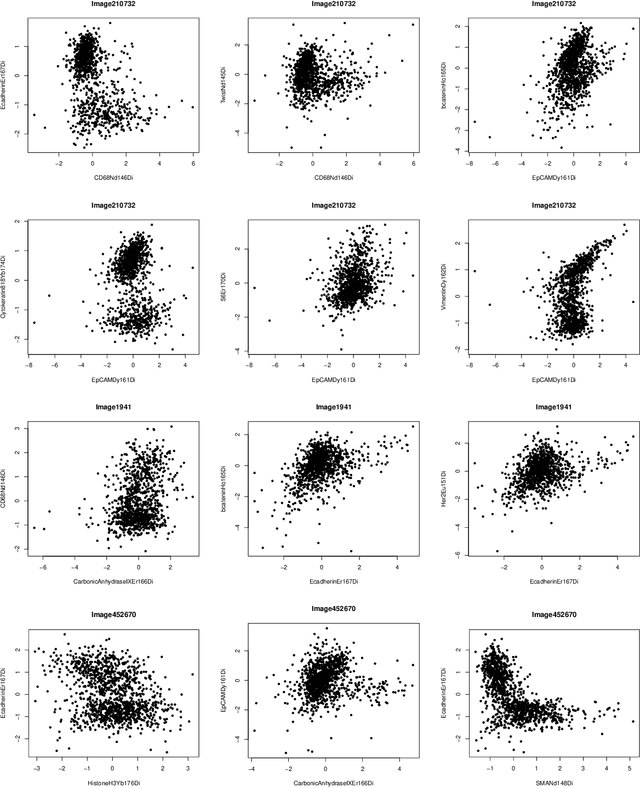
This paper studies the high-dimensional mixed linear regression (MLR) where the output variable comes from one of the two linear regression models with an unknown mixing proportion and an unknown covariance structure of the random covariates. Building upon a high-dimensional EM algorithm, we propose an iterative procedure for estimating the two regression vectors and establish their rates of convergence. Based on the iterative estimators, we further construct debiased estimators and establish their asymptotic normality. For individual coordinates, confidence intervals centered at the debiased estimators are constructed. Furthermore, a large-scale multiple testing procedure is proposed for testing the regression coefficients and is shown to control the false discovery rate (FDR) asymptotically. Simulation studies are carried out to examine the numerical performance of the proposed methods and their superiority over existing methods. The proposed methods are further illustrated through an analysis of a dataset of multiplex image cytometry, which investigates the interaction networks among the cellular phenotypes that include the expression levels of 20 epitopes or combinations of markers.
Transfer Learning in Large-scale Gaussian Graphical Models with False Discovery Rate Control
Oct 21, 2020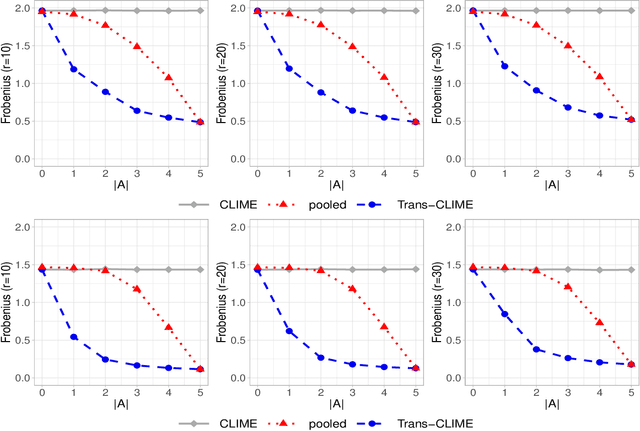
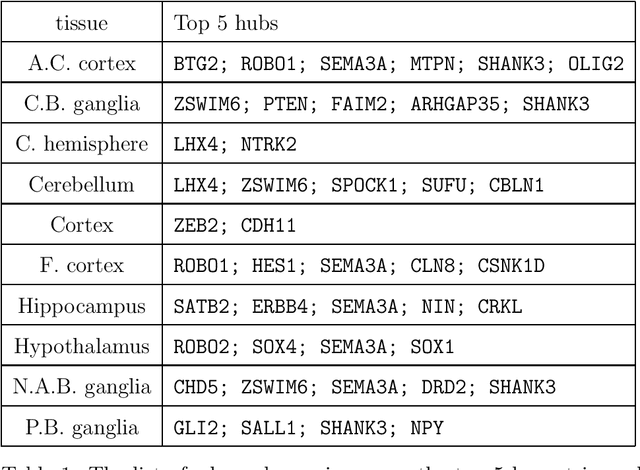
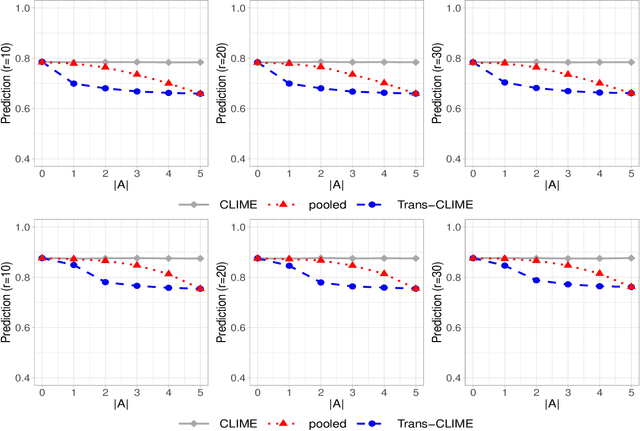
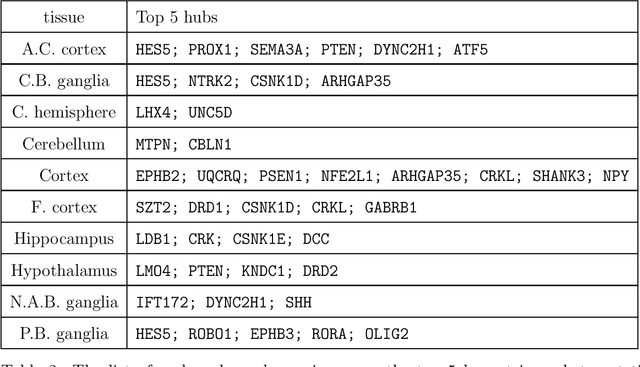
Transfer learning for high-dimensional Gaussian graphical models (GGMs) is studied with the goal of estimating the target GGM by utilizing the data from similar and related auxiliary studies. The similarity between the target graph and each auxiliary graph is characterized by the sparsity of a divergence matrix. An estimation algorithm, Trans-CLIME, is proposed and shown to attain a faster convergence rate than the minimax rate in the single study setting. Furthermore, a debiased Trans-CLIME estimator is introduced and shown to be element-wise asymptotically normal. It is used to construct a multiple testing procedure for edge detection with false discovery rate control. The proposed estimation and multiple testing procedures demonstrate superior numerical performance in simulations and are applied to infer the gene networks in a target brain tissue by leveraging the gene expressions from multiple other brain tissues. A significant decrease in prediction errors and a significant increase in power for link detection are observed.
Transfer Learning for High-dimensional Linear Regression: Prediction, Estimation, and Minimax Optimality
Jun 18, 2020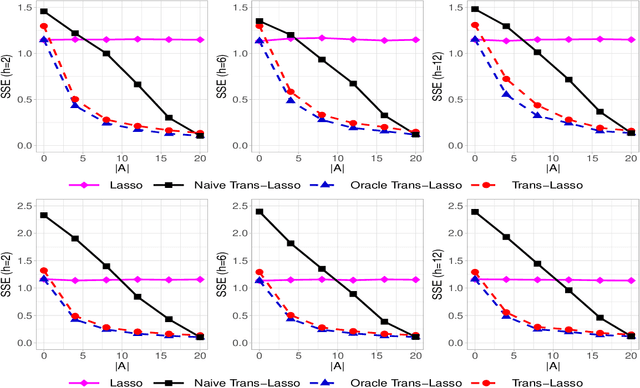
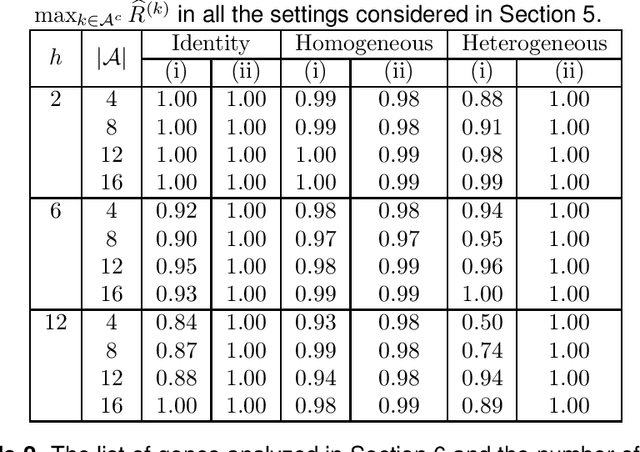
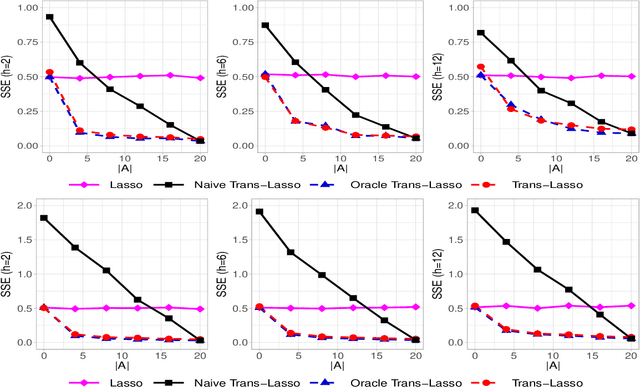
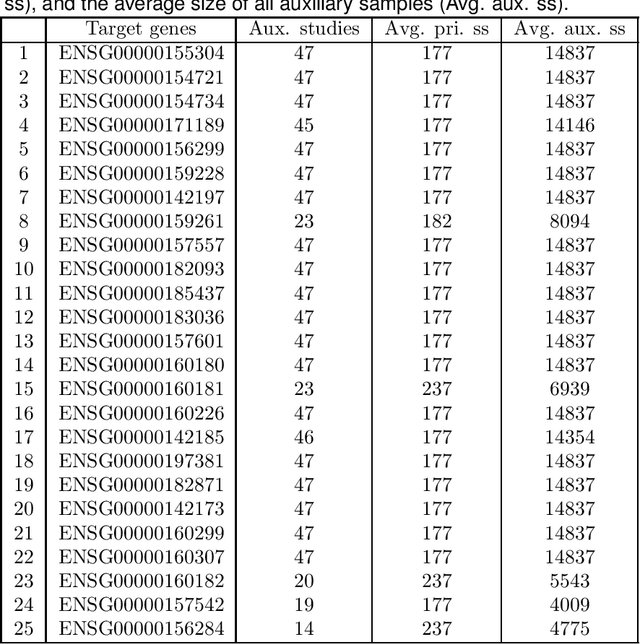
This paper considers the estimation and prediction of a high-dimensional linear regression in the setting of transfer learning, using samples from the target model as well as auxiliary samples from different but possibly related regression models. When the set of "informative" auxiliary samples is known, an estimator and a predictor are proposed and their optimality is established. The optimal rates of convergence for prediction and estimation are faster than the corresponding rates without using the auxiliary samples. This implies that knowledge from the informative auxiliary samples can be transferred to improve the learning performance of the target problem. In the case that the set of informative auxiliary samples is unknown, we propose a data-driven procedure for transfer learning, called Trans-Lasso, and reveal its robustness to non-informative auxiliary samples and its efficiency in knowledge transfer. The proposed procedures are demonstrated in numerical studies and are applied to a dataset concerning the associations among gene expressions. It is shown that Trans-Lasso leads to improved performance in gene expression prediction in a target tissue by incorporating the data from multiple different tissues as auxiliary samples.
Optimal Structured Principal Subspace Estimation: Metric Entropy and Minimax Rates
Feb 23, 2020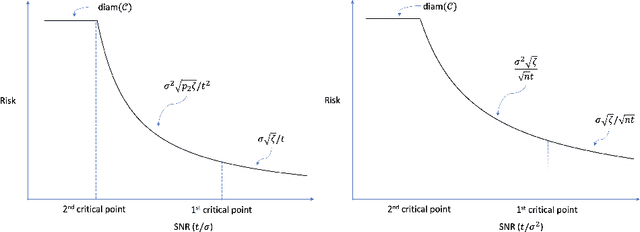
Driven by a wide range of applications, many principal subspace estimation problems have been studied individually under different structural constraints. This paper presents a unified framework for the statistical analysis of a general structured principal subspace estimation problem which includes as special cases non-negative PCA/SVD, sparse PCA/SVD, subspace constrained PCA/SVD, and spectral clustering. General minimax lower and upper bounds are established to characterize the interplay between the information-geometric complexity of the structural set for the principal subspaces, the signal-to-noise ratio (SNR), and the dimensionality. The results yield interesting phase transition phenomena concerning the rates of convergence as a function of the SNRs and the fundamental limit for consistent estimation. Applying the general results to the specific settings yields the minimax rates of convergence for those problems, including the previous unknown optimal rates for non-negative PCA/SVD, sparse SVD and subspace constrained PCA/SVD.