 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuel-Evolve: Reward-Free Test-Time Scaling via LLM Self-Preferences
Feb 25, 2026Many applications seek to optimize LLM outputs at test time by iteratively proposing, scoring, and refining candidates over a discrete output space. Existing methods use a calibrated scalar evaluator for the target objective to guide search, but for many tasks such scores are unavailable, too sparse, or unreliable. Pairwise comparisons, by contrast, are often easier to elicit, still provide useful signal on improvement directions, and can be obtained from the LLM itself without external supervision. Building on this observation, we introduce Duel-Evolve, an evolutionary optimization algorithm that replaces external scalar rewards with pairwise preferences elicited from the same LLM used to generate candidates. Duel-Evolve aggregates these noisy candidate comparisons via a Bayesian Bradley-Terry model, yielding uncertainty-aware estimates of candidate quality. These quality estimates guide allocation of the comparison budget toward plausible optima using Double Thompson Sampling, as well as selection of high-quality parents to generate improved candidates. We evaluate Duel-Evolve on MathBench, where it achieves 20 percentage points higher accuracy over existing methods and baselines, and on LiveCodeBench, where it improves over comparable iterative methods by over 12 percentage points. Notably, the method requires no reward model, no ground-truth labels during search, and no hand-crafted scoring function. Results show that pairwise self-preferences provide strong optimization signal for test-time improvement over large, discrete output spaces.
Estimating the Hallucination Rate of Generative AI
Jun 11, 2024



This work is about estimating the hallucination rate for in-context learning (ICL) with Generative AI. In ICL, a conditional generative model (CGM) is prompted with a dataset and asked to make a prediction based on that dataset. The Bayesian interpretation of ICL assumes that the CGM is calculating a posterior predictive distribution over an unknown Bayesian model of a latent parameter and data. With this perspective, we define a \textit{hallucination} as a generated prediction that has low-probability under the true latent parameter. We develop a new method that takes an ICL problem -- that is, a CGM, a dataset, and a prediction question -- and estimates the probability that a CGM will generate a hallucination. Our method only requires generating queries and responses from the model and evaluating its response log probability. We empirically evaluate our method on synthetic regression and natural language ICL tasks using large language models.
SafeCity: Understanding Diverse Forms of Sexual Harassment Personal Stories
Sep 14, 2018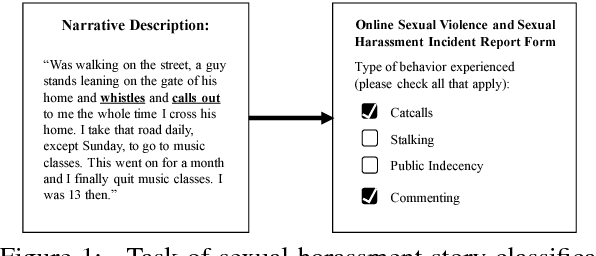
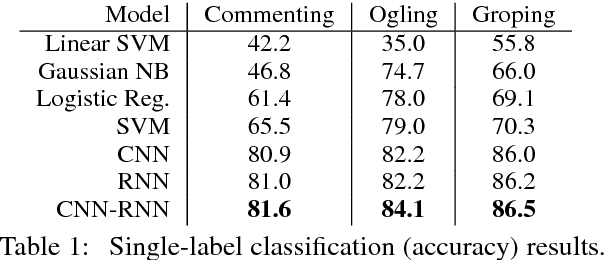
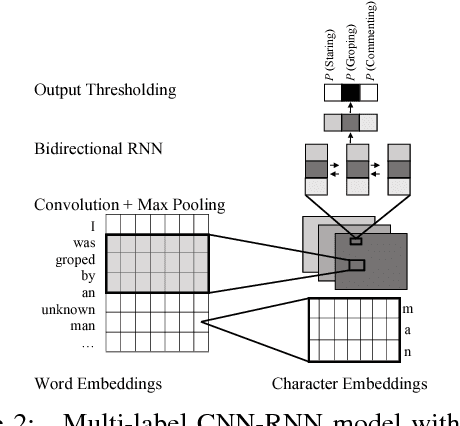
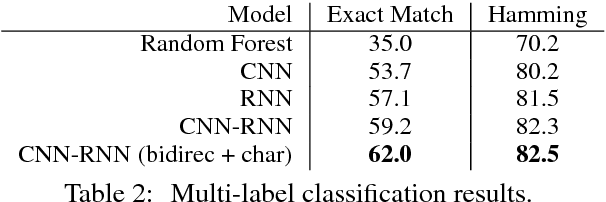
With the recent rise of #MeToo, an increasing number of personal stories about sexual harassment and sexual abuse have been shared online. In order to push forward the fight against such harassment and abuse, we present the task of automatically categorizing and analyzing various forms of sexual harassment, based on stories shared on the online forum SafeCity. For the labels of groping, ogling, and commenting, our single-label CNN-RNN model achieves an accuracy of 86.5%, and our multi-label model achieves a Hamming score of 82.5%. Furthermore, we present analysis using LIME, first-derivative saliency heatmaps, activation clustering, and embedding visualization to interpret neural model predictions and demonstrate how this extracts features that can help automatically fill out incident reports, identify unsafe areas, avoid unsafe practices, and 'pin the creeps'.
Detecting Linguistic Characteristics of Alzheimer's Dementia by Interpreting Neural Models
Apr 17, 2018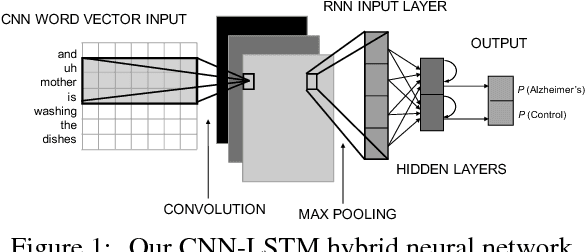


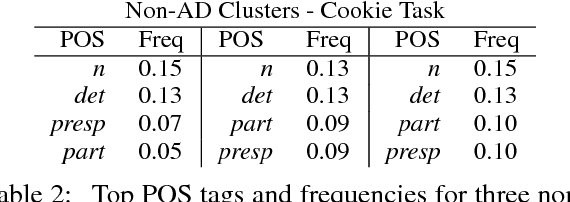
Alzheimer's disease (AD) is an irreversible and progressive brain disease that can be stopped or slowed down with medical treatment. Language changes serve as a sign that a patient's cognitive functions have been impacted, potentially leading to early diagnosis. In this work, we use NLP techniques to classify and analyze the linguistic characteristics of AD patients using the DementiaBank dataset. We apply three neural models based on CNNs, LSTM-RNNs, and their combination, to distinguish between language samples from AD and control patients. We achieve a new independent benchmark accuracy for the AD classification task. More importantly, we next interpret what these neural models have learned about the linguistic characteristics of AD patients, via analysis based on activation clustering and first-derivative saliency techniques. We then perform novel automatic pattern discovery inside activation clusters, and consolidate AD patients' distinctive grammar patterns. Additionally, we show that first derivative saliency can not only rediscover previous language patterns of AD patients, but also shed light on the limitations of neural models. Lastly, we also include analysis of gender-separated AD data.