 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2015 Task 10: Sentiment Analysis in Twitter
Dec 05, 2019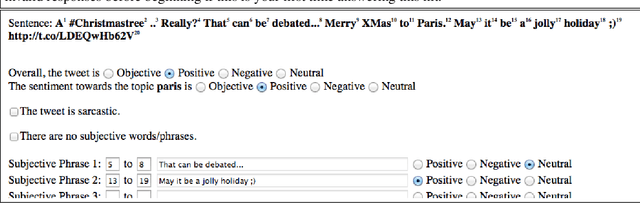

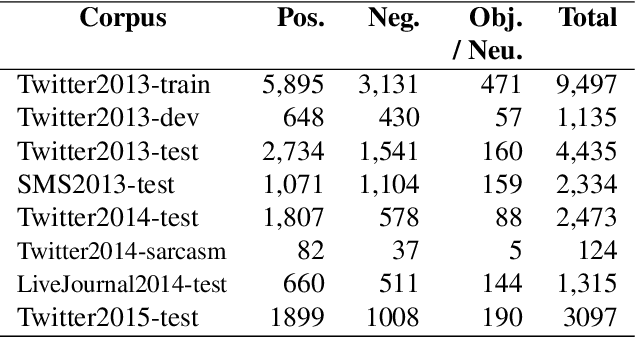
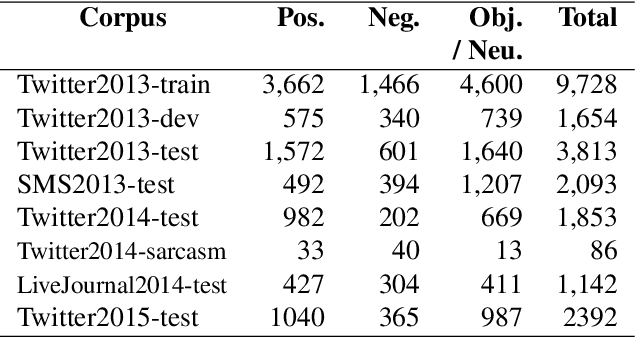
In this paper, we describe the 2015 iteration of the SemEval shared task on Sentiment Analysis in Twitter. This was the most popular sentiment analysis shared task to date with more than 40 teams participating in each of the last three years. This year's shared task competition consisted of five sentiment prediction subtasks. Two were reruns from previous years: (A) sentiment expressed by a phrase in the context of a tweet, and (B) overall sentiment of a tweet. We further included three new subtasks asking to predict (C) the sentiment towards a topic in a single tweet, (D) the overall sentiment towards a topic in a set of tweets, and (E) the degree of prior polarity of a phrase.
* Sentiment analysis, sentiment towards a topic, quantification, microblog sentiment analysis; Twitter opinion mining
NRC-Canada at SMM4H Shared Task: Classifying Tweets Mentioning Adverse Drug Reactions and Medication Intake
May 11, 2018

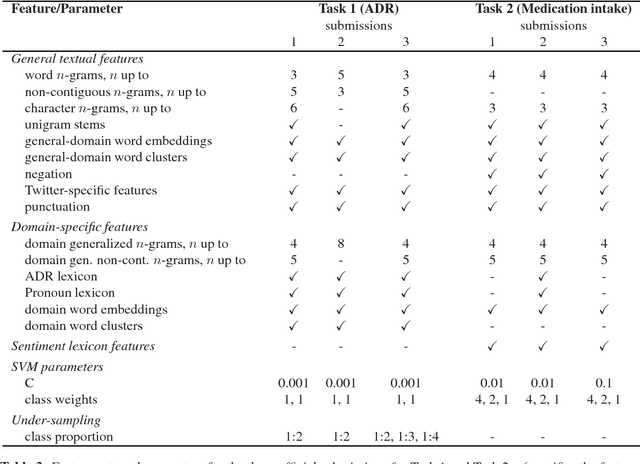
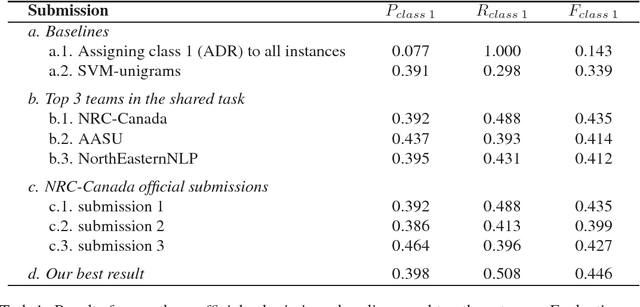
Our team, NRC-Canada, participated in two shared tasks at the AMIA-2017 Workshop on Social Media Mining for Health Applications (SMM4H): Task 1 - classification of tweets mentioning adverse drug reactions, and Task 2 - classification of tweets describing personal medication intake. For both tasks, we trained Support Vector Machine classifiers using a variety of surface-form, sentiment, and domain-specific features. With nine teams participating in each task, our submissions ranked first on Task 1 and third on Task 2. Handling considerable class imbalance proved crucial for Task 1. We applied an under-sampling technique to reduce class imbalance (from about 1:10 to 1:2). Standard n-gram features, n-grams generalized over domain terms, as well as general-domain and domain-specific word embeddings had a substantial impact on the overall performance in both tasks. On the other hand, including sentiment lexicon features did not result in any improvement.
Sentiment Composition of Words with Opposing Polarities
May 11, 2018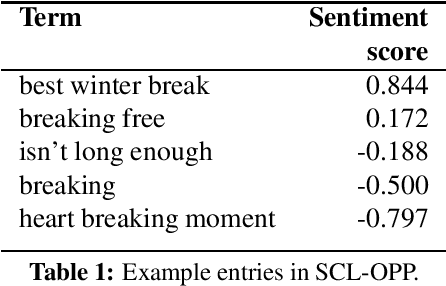

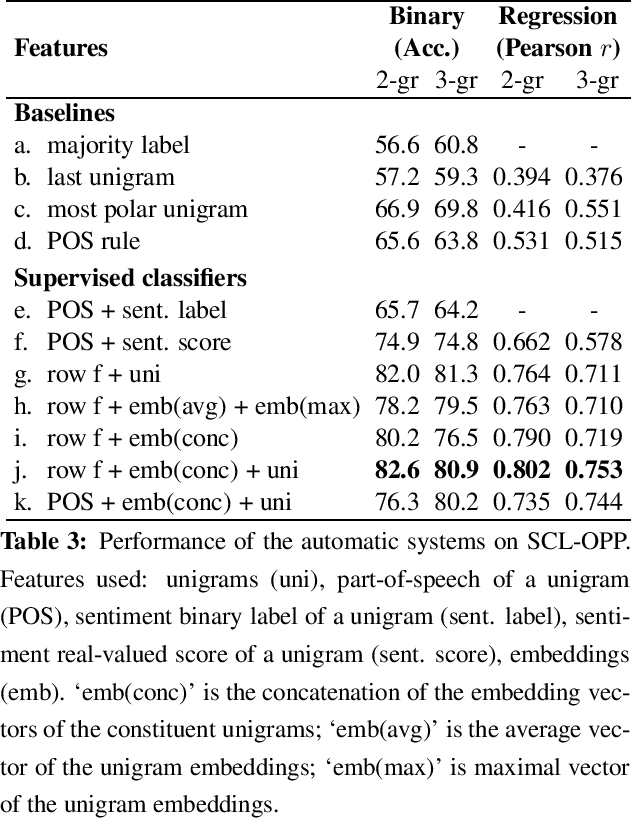
In this paper, we explore sentiment composition in phrases that have at least one positive and at least one negative word---phrases like 'happy accident' and 'best winter break'. We compiled a dataset of such opposing polarity phrases and manually annotated them with real-valued scores of sentiment association. Using this dataset, we analyze the linguistic patterns present in opposing polarity phrases. Finally, we apply several unsupervised and supervised techniques of sentiment composition to determine their efficacy on this dataset. Our best system, which incorporates information from the phrase's constituents, their parts of speech, their sentiment association scores, and their embedding vectors, obtains an accuracy of over 80% on the opposing polarity phrases.
Examining Gender and Race Bias in Two Hundred Sentiment Analysis Systems
May 11, 2018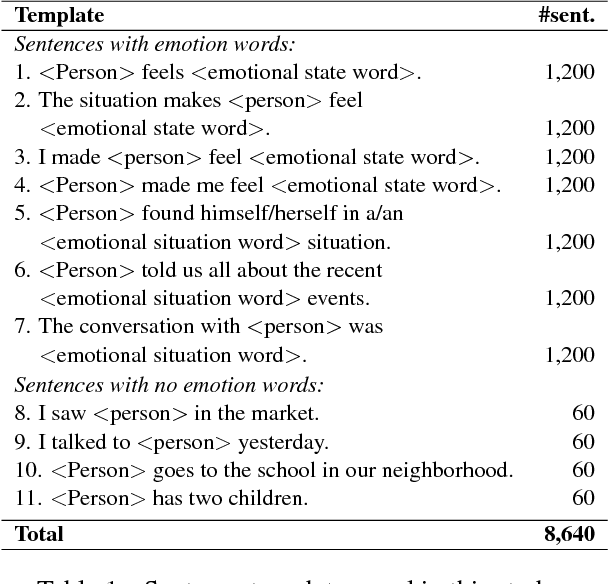
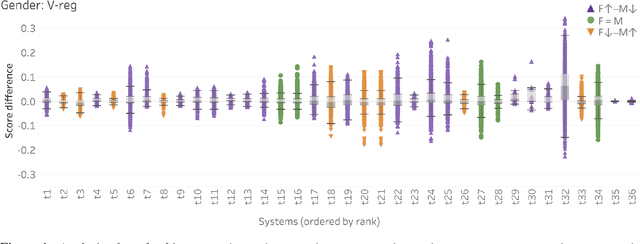
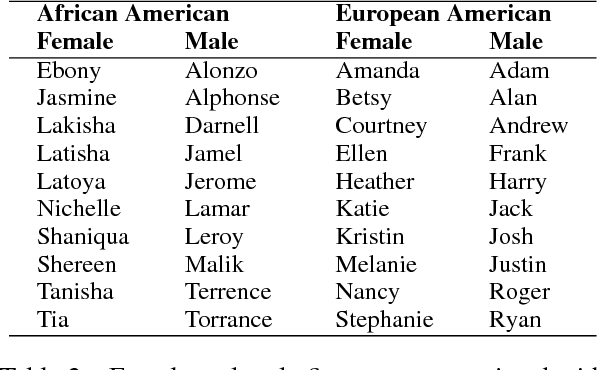
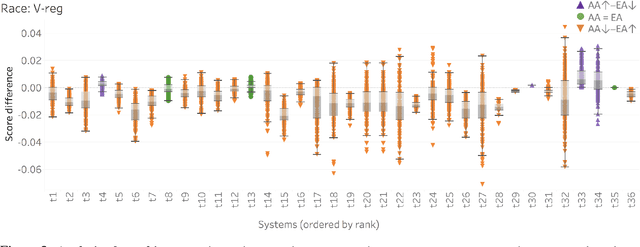
Automatic machine learning systems can inadvertently accentuate and perpetuate inappropriate human biases. Past work on examining inappropriate biases has largely focused on just individual systems. Further, there is no benchmark dataset for examining inappropriate biases in systems. Here for the first time, we present the Equity Evaluation Corpus (EEC), which consists of 8,640 English sentences carefully chosen to tease out biases towards certain races and genders. We use the dataset to examine 219 automatic sentiment analysis systems that took part in a recent shared task, SemEval-2018 Task 1 'Affect in Tweets'. We find that several of the systems show statistically significant bias; that is, they consistently provide slightly higher sentiment intensity predictions for one race or one gender. We make the EEC freely available.
The Effect of Negators, Modals, and Degree Adverbs on Sentiment Composition
Dec 05, 2017

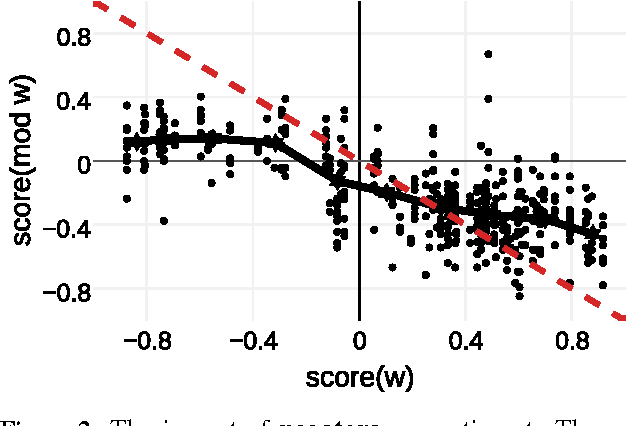
Negators, modals, and degree adverbs can significantly affect the sentiment of the words they modify. Often, their impact is modeled with simple heuristics; although, recent work has shown that such heuristics do not capture the true sentiment of multi-word phrases. We created a dataset of phrases that include various negators, modals, and degree adverbs, as well as their combinations. Both the phrases and their constituent content words were annotated with real-valued scores of sentiment association. Using phrasal terms in the created dataset, we analyze the impact of individual modifiers and the average effect of the groups of modifiers on overall sentiment. We find that the effect of modifiers varies substantially among the members of the same group. Furthermore, each individual modifier can affect sentiment words in different ways. Therefore, solutions based on statistical learning seem more promising than fixed hand-crafted rules on the task of automatic sentiment prediction.
Best-Worst Scaling More Reliable than Rating Scales: A Case Study on Sentiment Intensity Annotation
Dec 05, 2017
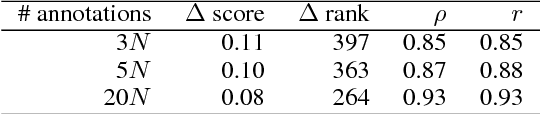

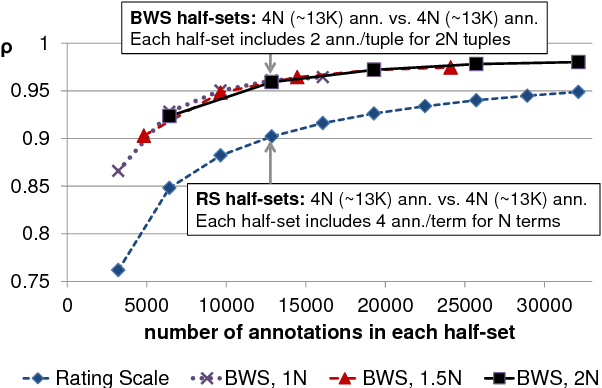
Rating scales are a widely used method for data annotation; however, they present several challenges, such as difficulty in maintaining inter- and intra-annotator consistency. Best-worst scaling (BWS) is an alternative method of annotation that is claimed to produce high-quality annotations while keeping the required number of annotations similar to that of rating scales. However, the veracity of this claim has never been systematically established. Here for the first time, we set up an experiment that directly compares the rating scale method with BWS. We show that with the same total number of annotations, BWS produces significantly more reliable results than the rating scale.
Capturing Reliable Fine-Grained Sentiment Associations by Crowdsourcing and Best-Worst Scaling
Dec 05, 2017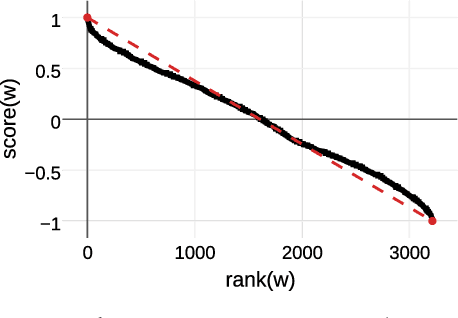
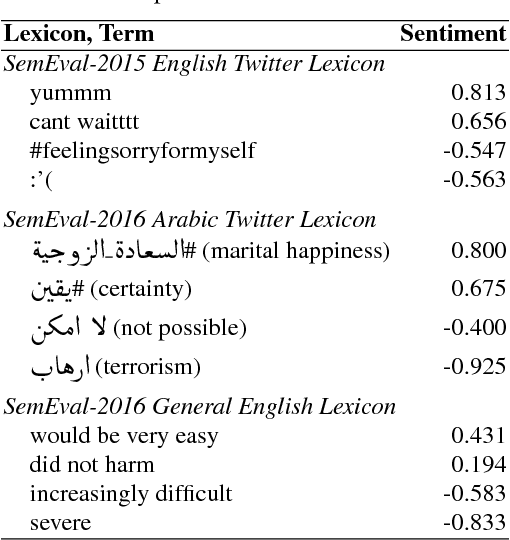
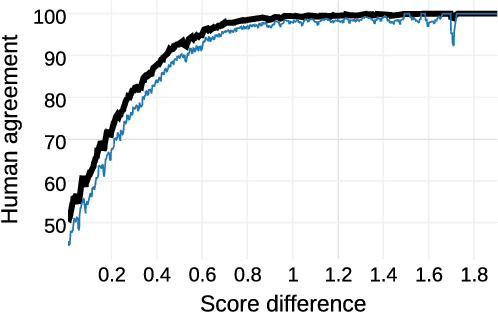
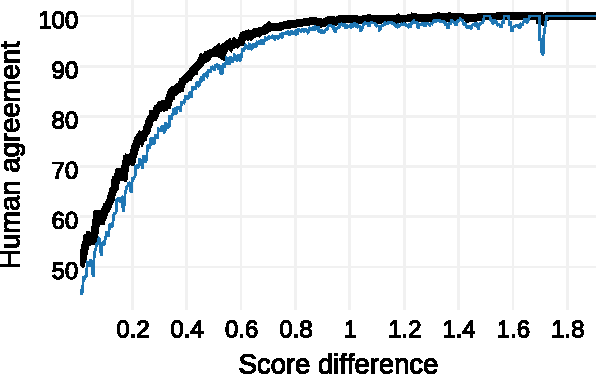
Access to word-sentiment associations is useful for many applications, including sentiment analysis, stance detection, and linguistic analysis. However, manually assigning fine-grained sentiment association scores to words has many challenges with respect to keeping annotations consistent. We apply the annotation technique of Best-Worst Scaling to obtain real-valued sentiment association scores for words and phrases in three different domains: general English, English Twitter, and Arabic Twitter. We show that on all three domains the ranking of words by sentiment remains remarkably consistent even when the annotation process is repeated with a different set of annotators. We also, for the first time, determine the minimum difference in sentiment association that is perceptible to native speakers of a language.
Stance and Sentiment in Tweets
May 05, 2016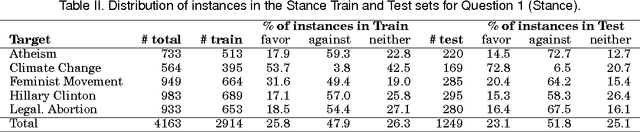

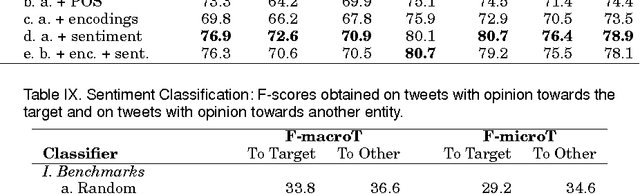
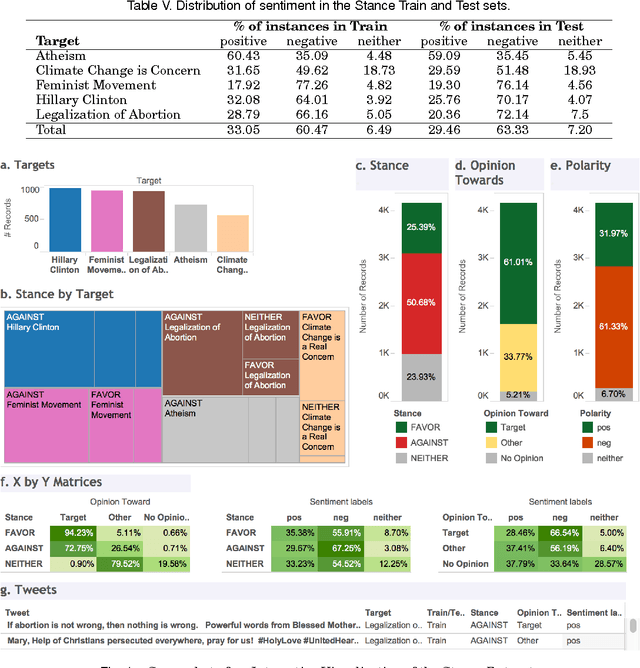
We can often detect from a person's utterances whether he/she is in favor of or against a given target entity -- their stance towards the target. However, a person may express the same stance towards a target by using negative or positive language. Here for the first time we present a dataset of tweet--target pairs annotated for both stance and sentiment. The targets may or may not be referred to in the tweets, and they may or may not be the target of opinion in the tweets. Partitions of this dataset were used as training and test sets in a SemEval-2016 shared task competition. We propose a simple stance detection system that outperforms submissions from all 19 teams that participated in the shared task. Additionally, access to both stance and sentiment annotations allows us to explore several research questions. We show that while knowing the sentiment expressed by a tweet is beneficial for stance classification, it alone is not sufficient. Finally, we use additional unlabeled data through distant supervision techniques and word embeddings to further improve stance classification.
Identifying Purpose Behind Electoral Tweets
Nov 05, 2013

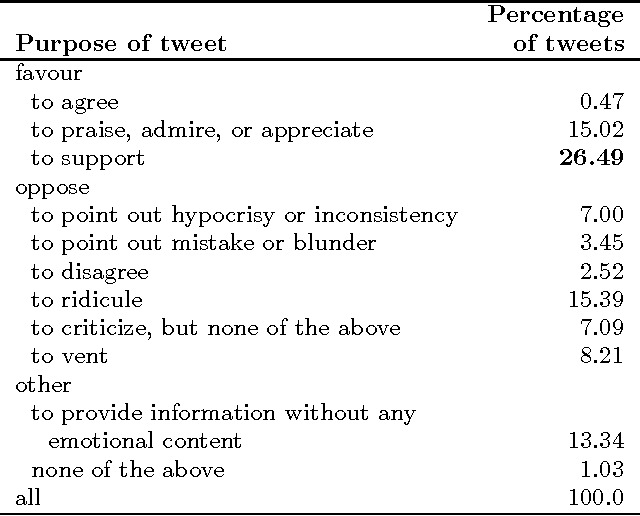

Tweets pertaining to a single event, such as a national election, can number in the hundreds of millions. Automatically analyzing them is beneficial in many downstream natural language applications such as question answering and summarization. In this paper, we propose a new task: identifying the purpose behind electoral tweets--why do people post election-oriented tweets? We show that identifying purpose is correlated with the related phenomenon of sentiment and emotion detection, but yet significantly different. Detecting purpose has a number of applications including detecting the mood of the electorate, estimating the popularity of policies, identifying key issues of contention, and predicting the course of events. We create a large dataset of electoral tweets and annotate a few thousand tweets for purpose. We develop a system that automatically classifies electoral tweets as per their purpose, obtaining an accuracy of 43.56% on an 11-class task and an accuracy of 73.91% on a 3-class task (both accuracies well above the most-frequent-class baseline). Finally, we show that resources developed for emotion detection are also helpful for detecting purpose.
Using Nuances of Emotion to Identify Personality
Sep 24, 2013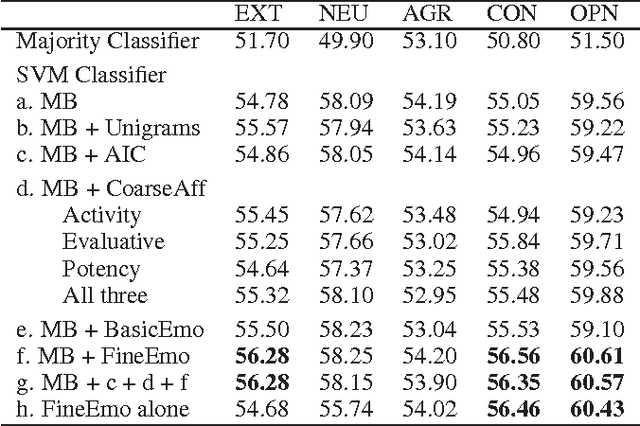
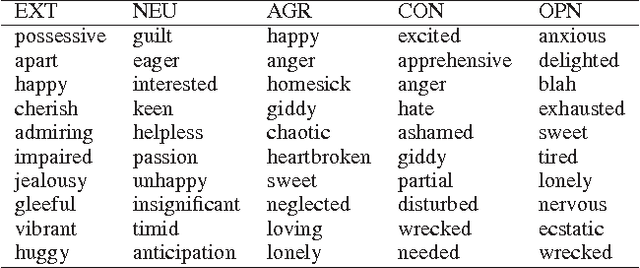
Past work on personality detection has shown that frequency of lexical categories such as first person pronouns, past tense verbs, and sentiment words have significant correlations with personality traits. In this paper, for the first time, we show that fine affect (emotion) categories such as that of excitement, guilt, yearning, and admiration are significant indicators of personality. Additionally, we perform experiments to show that the gains provided by the fine affect categories are not obtained by using coarse affect categories alone or with specificity features alone. We employ these features in five SVM classifiers for detecting five personality traits through essays. We find that the use of fine emotion features leads to statistically significant improvement over a competitive baseline, whereas the use of coarse affect and specificity features does not.