 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Augmented Theory of Mind Network
Jan 17, 2023



Social reasoning necessitates the capacity of theory of mind (ToM), the ability to contextualise and attribute mental states to others without having access to their internal cognitive structure. Recent machine learning approaches to ToM have demonstrated that we can train the observer to read the past and present behaviours of other agents and infer their beliefs (including false beliefs about things that no longer exist), goals, intentions and future actions. The challenges arise when the behavioural space is complex, demanding skilful space navigation for rapidly changing contexts for an extended period. We tackle the challenges by equipping the observer with novel neural memory mechanisms to encode, and hierarchical attention to selectively retrieve information about others. The memories allow rapid, selective querying of distal related past behaviours of others to deliberatively reason about their current mental state, beliefs and future behaviours. This results in ToMMY, a theory of mind model that learns to reason while making little assumptions about the underlying mental processes. We also construct a new suite of experiments to demonstrate that memories facilitate the learning process and achieve better theory of mind performance, especially for high-demand false-belief tasks that require inferring through multiple steps of changes.
On Instance-Dependent Bounds for Offline Reinforcement Learning with Linear Function Approximation
Nov 23, 2022



Sample-efficient offline reinforcement learning (RL) with linear function approximation has recently been studied extensively. Much of prior work has yielded the minimax-optimal bound of $\tilde{\mathcal{O}}(\frac{1}{\sqrt{K}})$, with $K$ being the number of episodes in the offline data. In this work, we seek to understand instance-dependent bounds for offline RL with function approximation. We present an algorithm called Bootstrapped and Constrained Pessimistic Value Iteration (BCP-VI), which leverages data bootstrapping and constrained optimization on top of pessimism. We show that under a partial data coverage assumption, that of \emph{concentrability} with respect to an optimal policy, the proposed algorithm yields a fast rate of $\tilde{\mathcal{O}}(\frac{1}{K})$ for offline RL when there is a positive gap in the optimal Q-value functions, even when the offline data were adaptively collected. Moreover, when the linear features of the optimal actions in the states reachable by an optimal policy span those reachable by the behavior policy and the optimal actions are unique, offline RL achieves absolute zero sub-optimality error when $K$ exceeds a (finite) instance-dependent threshold. To the best of our knowledge, these are the first $\tilde{\mathcal{O}}(\frac{1}{K})$ bound and absolute zero sub-optimality bound respectively for offline RL with linear function approximation from adaptive data with partial coverage. We also provide instance-agnostic and instance-dependent information-theoretical lower bounds to complement our upper bounds.
Momentum Adversarial Distillation: Handling Large Distribution Shifts in Data-Free Knowledge Distillation
Sep 21, 2022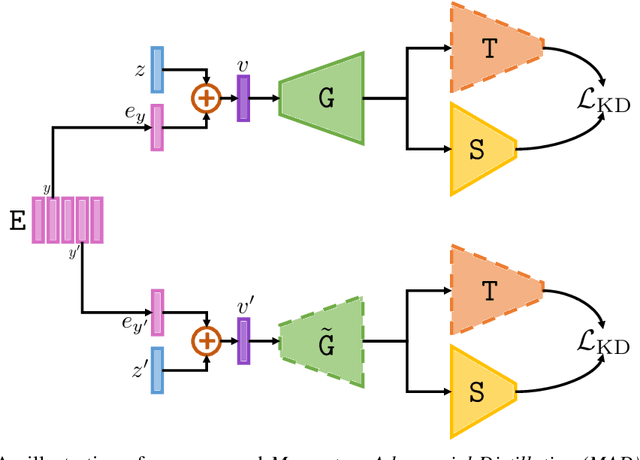


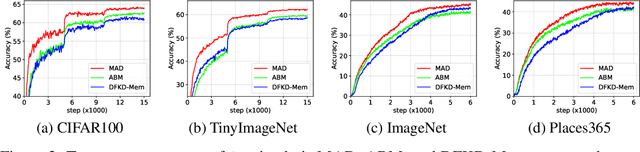
Data-free Knowledge Distillation (DFKD) has attracted attention recently thanks to its appealing capability of transferring knowledge from a teacher network to a student network without using training data. The main idea is to use a generator to synthesize data for training the student. As the generator gets updated, the distribution of synthetic data will change. Such distribution shift could be large if the generator and the student are trained adversarially, causing the student to forget the knowledge it acquired at previous steps. To alleviate this problem, we propose a simple yet effective method called Momentum Adversarial Distillation (MAD) which maintains an exponential moving average (EMA) copy of the generator and uses synthetic samples from both the generator and the EMA generator to train the student. Since the EMA generator can be considered as an ensemble of the generator's old versions and often undergoes a smaller change in updates compared to the generator, training on its synthetic samples can help the student recall the past knowledge and prevent the student from adapting too quickly to new updates of the generator. Our experiments on six benchmark datasets including big datasets like ImageNet and Places365 demonstrate the superior performance of MAD over competing methods for handling the large distribution shift problem. Our method also compares favorably to existing DFKD methods and even achieves state-of-the-art results in some cases.
Black-box Few-shot Knowledge Distillation
Jul 25, 2022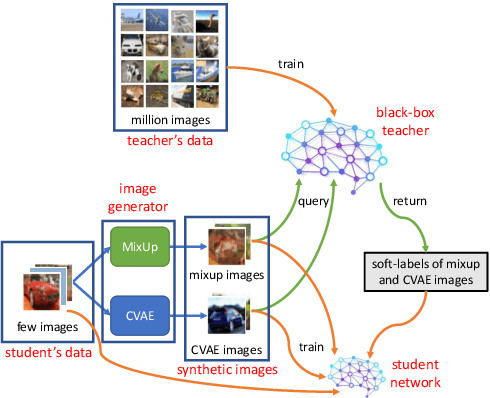
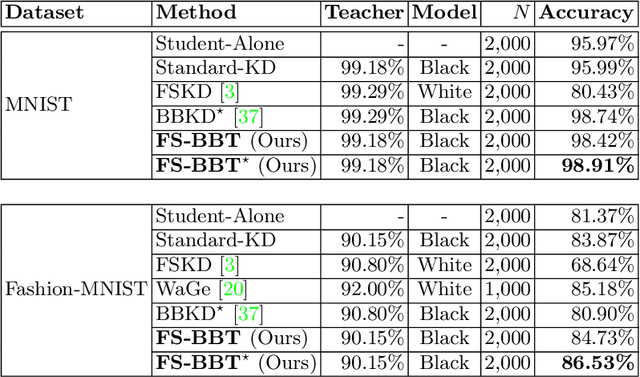
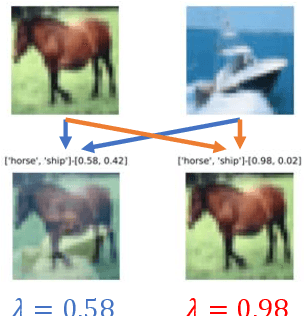
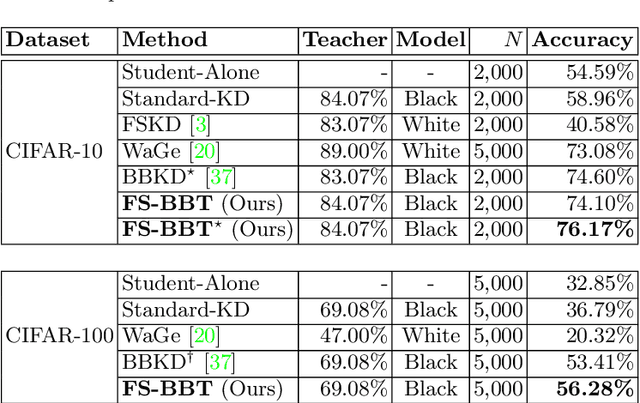
Knowledge distillation (KD) is an efficient approach to transfer the knowledge from a large "teacher" network to a smaller "student" network. Traditional KD methods require lots of labeled training samples and a white-box teacher (parameters are accessible) to train a good student. However, these resources are not always available in real-world applications. The distillation process often happens at an external party side where we do not have access to much data, and the teacher does not disclose its parameters due to security and privacy concerns. To overcome these challenges, we propose a black-box few-shot KD method to train the student with few unlabeled training samples and a black-box teacher. Our main idea is to expand the training set by generating a diverse set of out-of-distribution synthetic images using MixUp and a conditional variational auto-encoder. These synthetic images along with their labels obtained from the teacher are used to train the student. We conduct extensive experiments to show that our method significantly outperforms recent SOTA few/zero-shot KD methods on image classification tasks. The code and models are available at: https://github.com/nphdang/FS-BBT
Guiding Visual Question Answering with Attention Priors
May 25, 2022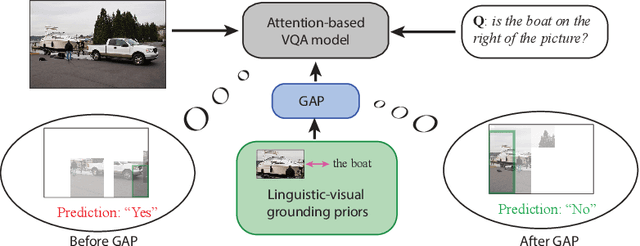
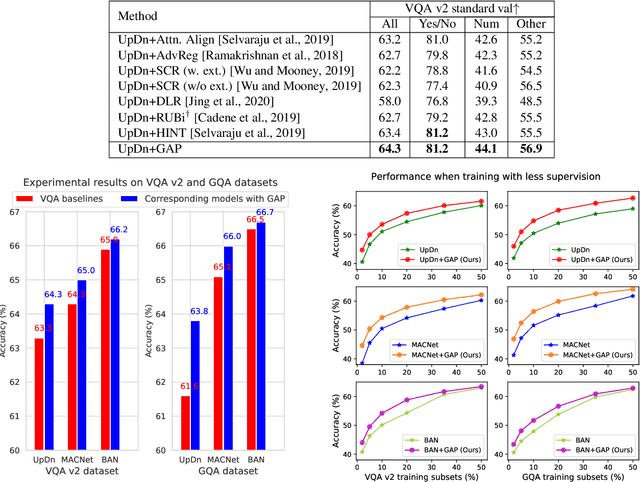
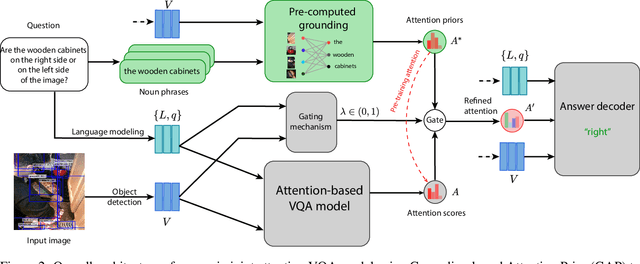

The current success of modern visual reasoning systems is arguably attributed to cross-modality attention mechanisms. However, in deliberative reasoning such as in VQA, attention is unconstrained at each step, and thus may serve as a statistical pooling mechanism rather than a semantic operation intended to select information relevant to inference. This is because at training time, attention is only guided by a very sparse signal (i.e. the answer label) at the end of the inference chain. This causes the cross-modality attention weights to deviate from the desired visual-language bindings. To rectify this deviation, we propose to guide the attention mechanism using explicit linguistic-visual grounding. This grounding is derived by connecting structured linguistic concepts in the query to their referents among the visual objects. Here we learn the grounding from the pairing of questions and images alone, without the need for answer annotation or external grounding supervision. This grounding guides the attention mechanism inside VQA models through a duality of mechanisms: pre-training attention weight calculation and directly guiding the weights at inference time on a case-by-case basis. The resultant algorithm is capable of probing attention-based reasoning models, injecting relevant associative knowledge, and regulating the core reasoning process. This scalable enhancement improves the performance of VQA models, fortifies their robustness to limited access to supervised data, and increases interpretability.
Fast Conditional Network Compression Using Bayesian HyperNetworks
May 13, 2022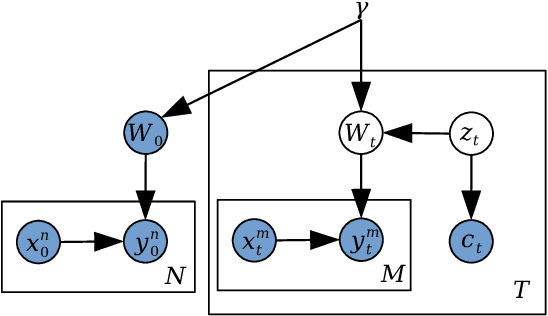
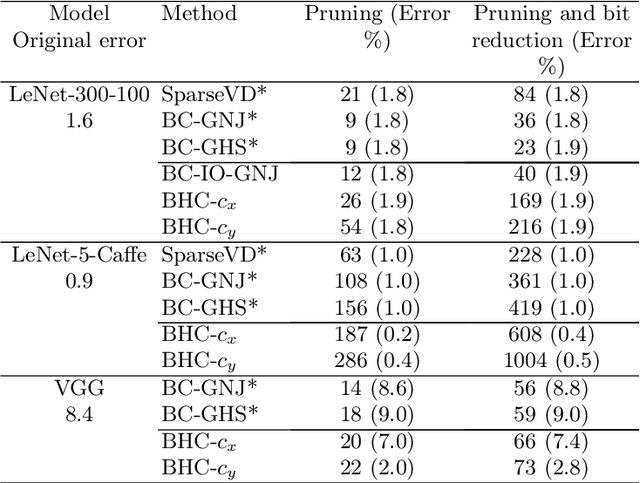
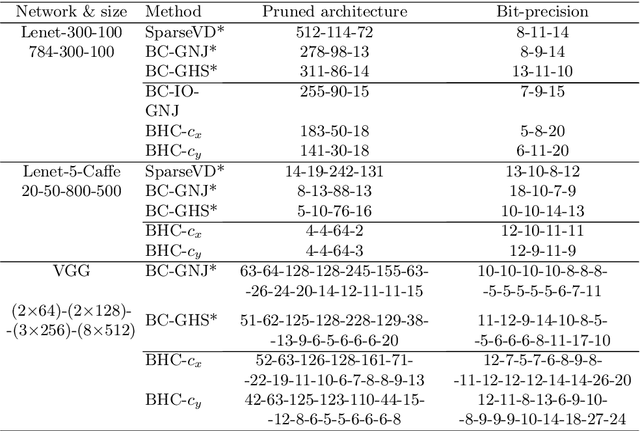
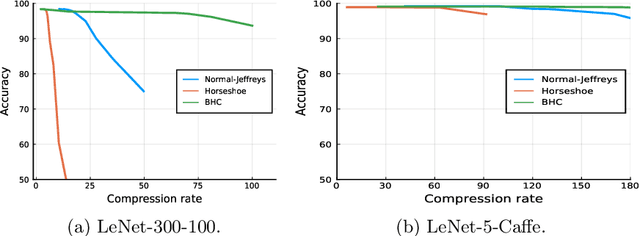
We introduce a conditional compression problem and propose a fast framework for tackling it. The problem is how to quickly compress a pretrained large neural network into optimal smaller networks given target contexts, e.g. a context involving only a subset of classes or a context where only limited compute resource is available. To solve this, we propose an efficient Bayesian framework to compress a given large network into much smaller size tailored to meet each contextual requirement. We employ a hypernetwork to parameterize the posterior distribution of weights given conditional inputs and minimize a variational objective of this Bayesian neural network. To further reduce the network sizes, we propose a new input-output group sparsity factorization of weights to encourage more sparseness in the generated weights. Our methods can quickly generate compressed networks with significantly smaller sizes than baseline methods.
Persistent-Transient Duality in Human Behavior Modeling
Apr 21, 2022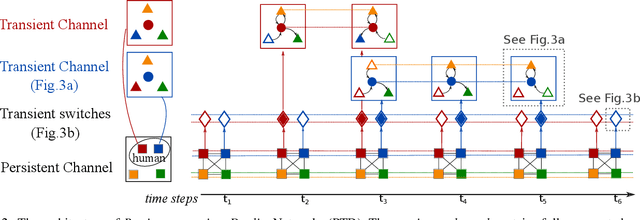
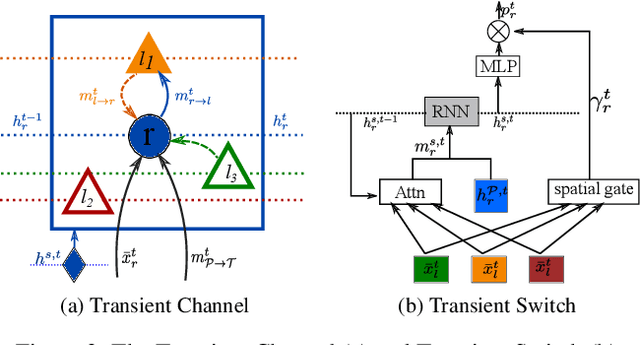
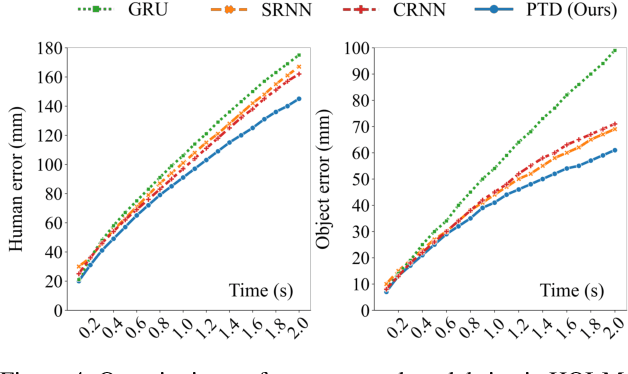
We propose to model the persistent-transient duality in human behavior using a parent-child multi-channel neural network, which features a parent persistent channel that manages the global dynamics and children transient channels that are initiated and terminated on-demand to handle detailed interactive actions. The short-lived transient sessions are managed by a proposed Transient Switch. The neural framework is trained to discover the structure of the duality automatically. Our model shows superior performances in human-object interaction motion prediction.
Memory-Constrained Policy Optimization
Apr 20, 2022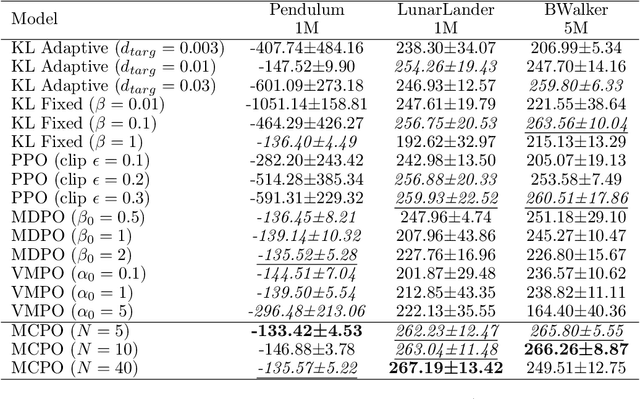


We introduce a new constrained optimization method for policy gradient reinforcement learning, which uses two trust regions to regulate each policy update. In addition to using the proximity of one single old policy as the first trust region as done by prior works, we propose to form a second trust region through the construction of another virtual policy that represents a wide range of past policies. We then enforce the new policy to stay closer to the virtual policy, which is beneficial in case the old policy performs badly. More importantly, we propose a mechanism to automatically build the virtual policy from a memory buffer of past policies, providing a new capability for dynamically selecting appropriate trust regions during the optimization process. Our proposed method, dubbed as Memory-Constrained Policy Optimization (MCPO), is examined on a diverse suite of environments including robotic locomotion control, navigation with sparse rewards and Atari games, consistently demonstrating competitive performance against recent on-policy constrained policy gradient methods.
Learning to Transfer Role Assignment Across Team Sizes
Apr 17, 2022
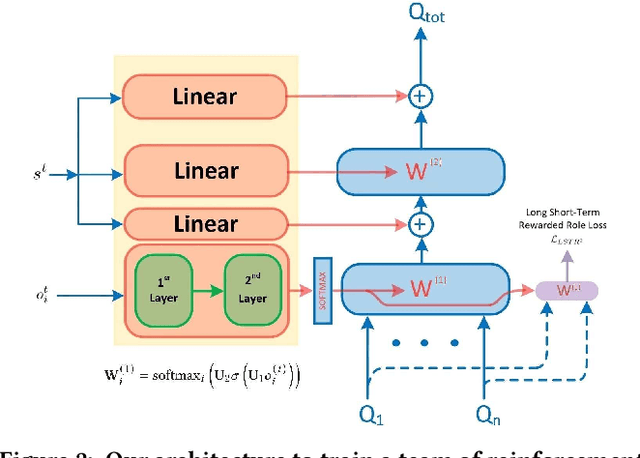
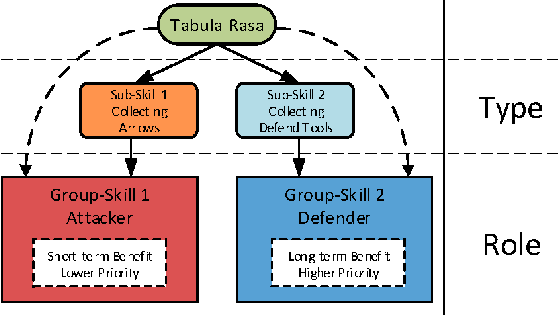

Multi-agent reinforcement learning holds the key for solving complex tasks that demand the coordination of learning agents. However, strong coordination often leads to expensive exploration over the exponentially large state-action space. A powerful approach is to decompose team works into roles, which are ideally assigned to agents with the relevant skills. Training agents to adaptively choose and play emerging roles in a team thus allows the team to scale to complex tasks and quickly adapt to changing environments. These promises, however, have not been fully realised by current role-based multi-agent reinforcement learning methods as they assume either a pre-defined role structure or a fixed team size. We propose a framework to learn role assignment and transfer across team sizes. In particular, we train a role assignment network for small teams by demonstration and transfer the network to larger teams, which continue to learn through interaction with the environment. We demonstrate that re-using the role-based credit assignment structure can foster the learning process of larger reinforcement learning teams to achieve tasks requiring different roles. Our proposal outperforms competing techniques in enriched role-enforcing Prey-Predator games and in new scenarios in the StarCraft II Micro-Management benchmark.
Learning Theory of Mind via Dynamic Traits Attribution
Apr 17, 2022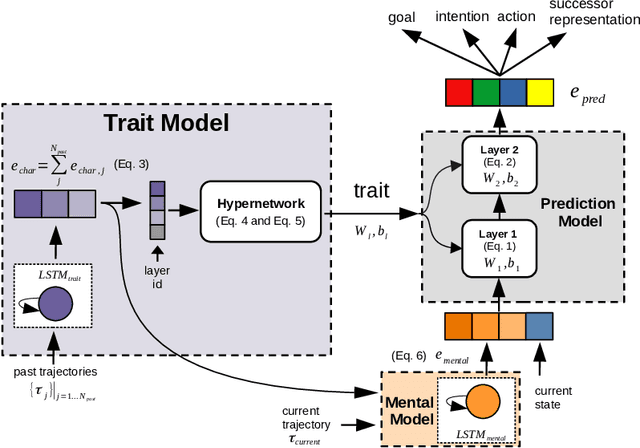
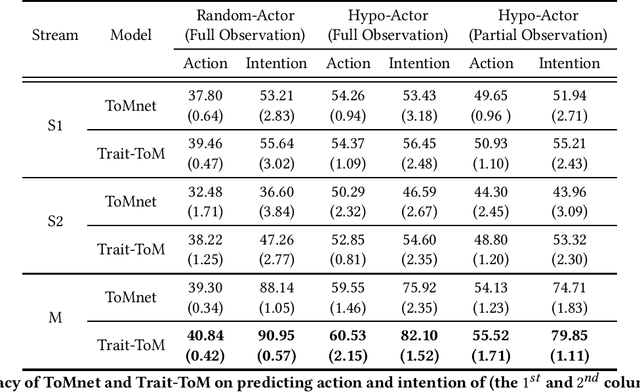
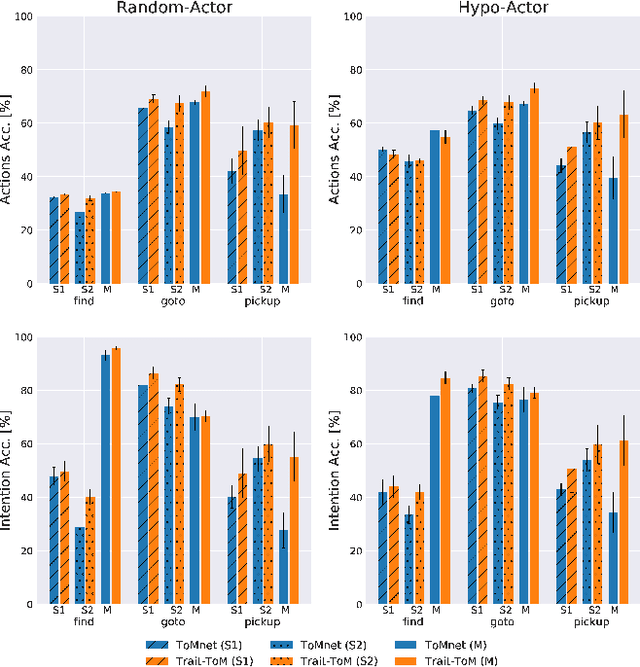
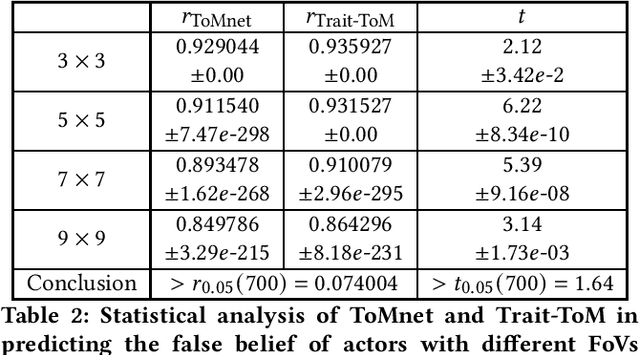
Machine learning of Theory of Mind (ToM) is essential to build social agents that co-live with humans and other agents. This capacity, once acquired, will help machines infer the mental states of others from observed contextual action trajectories, enabling future prediction of goals, intention, actions and successor representations. The underlying mechanism for such a prediction remains unclear, however. Inspired by the observation that humans often infer the character traits of others, then use it to explain behaviour, we propose a new neural ToM architecture that learns to generate a latent trait vector of an actor from the past trajectories. This trait vector then multiplicatively modulates the prediction mechanism via a `fast weights' scheme in the prediction neural network, which reads the current context and predicts the behaviour. We empirically show that the fast weights provide a good inductive bias to model the character traits of agents and hence improves mindreading ability. On the indirect assessment of false-belief understanding, the new ToM model enables more efficient helping behaviours.