 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Expressive Power of Deep Neural Networks
Jun 18, 2017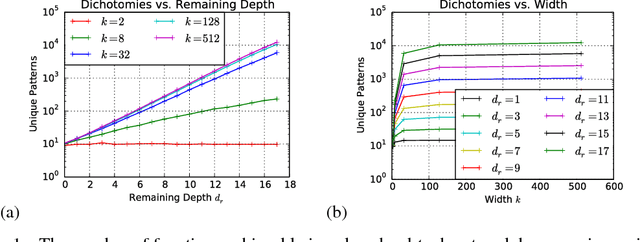


We propose a new approach to the problem of neural network expressivity, which seeks to characterize how structural properties of a neural network family affect the functions it is able to compute. Our approach is based on an interrelated set of measures of expressivity, unified by the novel notion of trajectory length, which measures how the output of a network changes as the input sweeps along a one-dimensional path. Our findings can be summarized as follows: (1) The complexity of the computed function grows exponentially with depth. (2) All weights are not equal: trained networks are more sensitive to their lower (initial) layer weights. (3) Regularizing on trajectory length (trajectory regularization) is a simpler alternative to batch normalization, with the same performance.
Continual Learning Through Synaptic Intelligence
Jun 12, 2017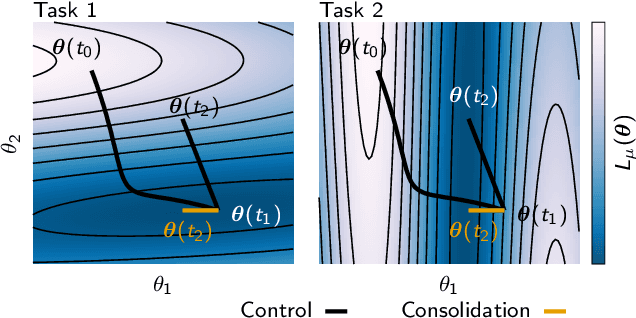
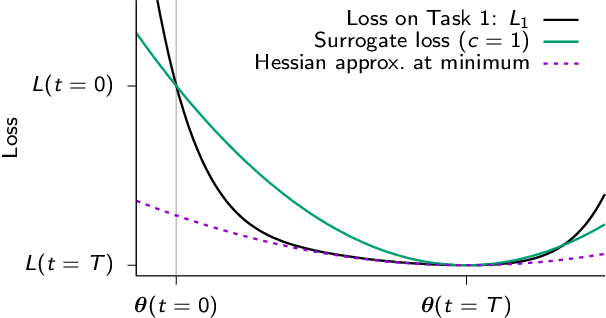
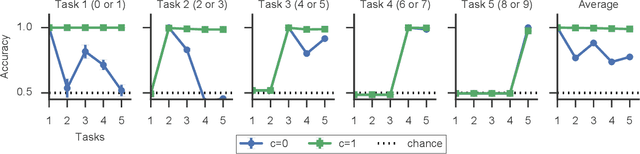
While deep learning has led to remarkable advances across diverse applications, it struggles in domains where the data distribution changes over the course of learning. In stark contrast, biological neural networks continually adapt to changing domains, possibly by leveraging complex molecular machinery to solve many tasks simultaneously. In this study, we introduce intelligent synapses that bring some of this biological complexity into artificial neural networks. Each synapse accumulates task relevant information over time, and exploits this information to rapidly store new memories without forgetting old ones. We evaluate our approach on continual learning of classification tasks, and show that it dramatically reduces forgetting while maintaining computational efficiency.
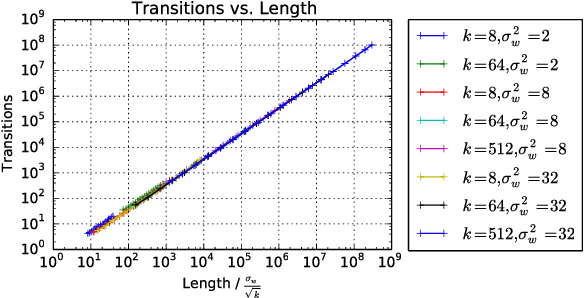
Deep Information Propagation
Apr 04, 2017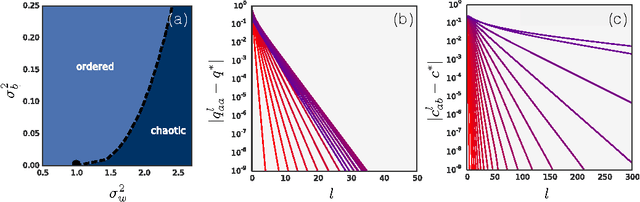
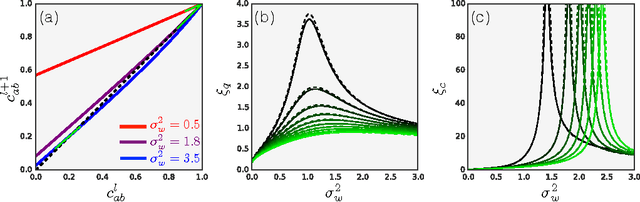
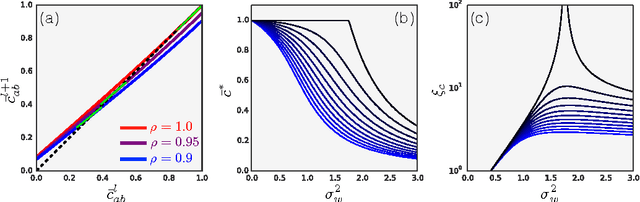
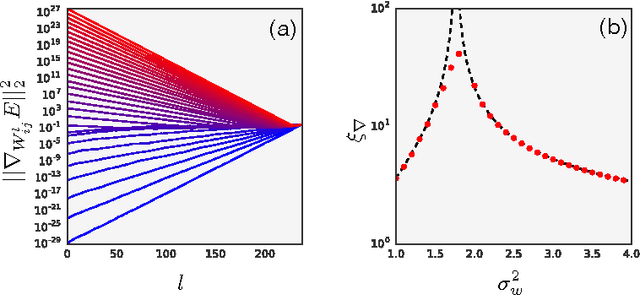
We study the behavior of untrained neural networks whose weights and biases are randomly distributed using mean field theory. We show the existence of depth scales that naturally limit the maximum depth of signal propagation through these random networks. Our main practical result is to show that random networks may be trained precisely when information can travel through them. Thus, the depth scales that we identify provide bounds on how deep a network may be trained for a specific choice of hyperparameters. As a corollary to this, we argue that in networks at the edge of chaos, one of these depth scales diverges. Thus arbitrarily deep networks may be trained only sufficiently close to criticality. We show that the presence of dropout destroys the order-to-chaos critical point and therefore strongly limits the maximum trainable depth for random networks. Finally, we develop a mean field theory for backpropagation and we show that the ordered and chaotic phases correspond to regions of vanishing and exploding gradient respectively.
Biologically inspired protection of deep networks from adversarial attacks
Mar 27, 2017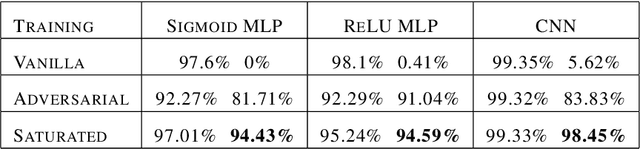
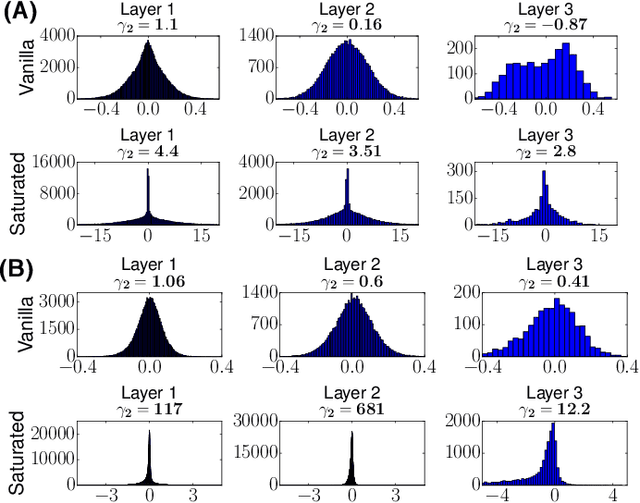
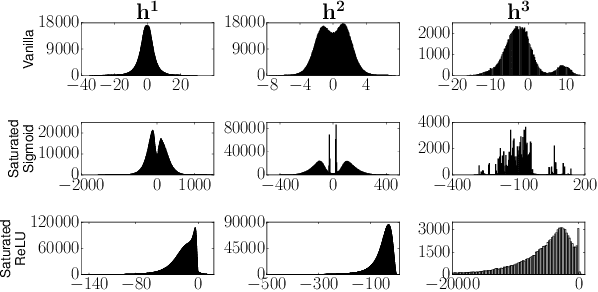
Inspired by biophysical principles underlying nonlinear dendritic computation in neural circuits, we develop a scheme to train deep neural networks to make them robust to adversarial attacks. Our scheme generates highly nonlinear, saturated neural networks that achieve state of the art performance on gradient based adversarial examples on MNIST, despite never being exposed to adversarially chosen examples during training. Moreover, these networks exhibit unprecedented robustness to targeted, iterative schemes for generating adversarial examples, including second-order methods. We further identify principles governing how these networks achieve their robustness, drawing on methods from information geometry. We find these networks progressively create highly flat and compressed internal representations that are sensitive to very few input dimensions, while still solving the task. Moreover, they employ highly kurtotic weight distributions, also found in the brain, and we demonstrate how such kurtosis can protect even linear classifiers from adversarial attack.
Deep Learning Models of the Retinal Response to Natural Scenes
Feb 06, 2017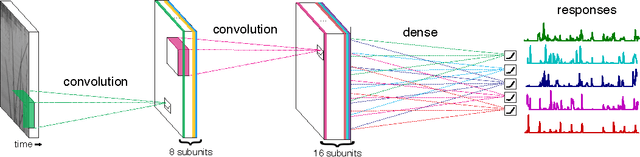
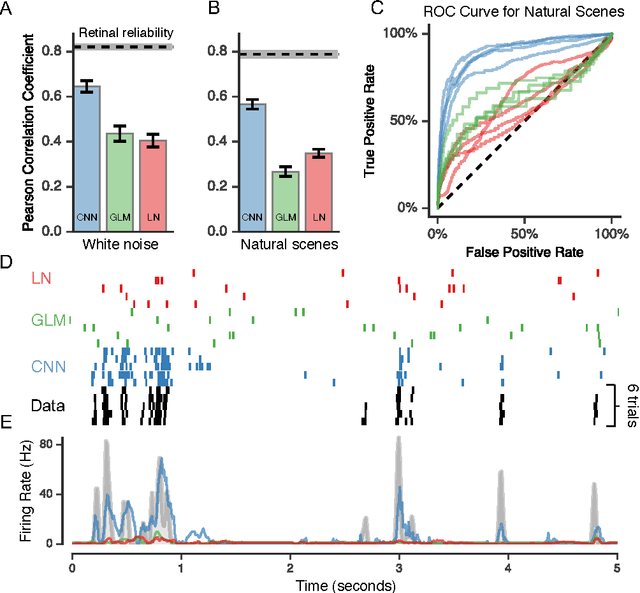
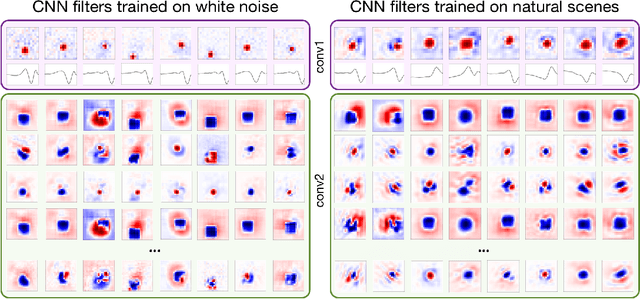
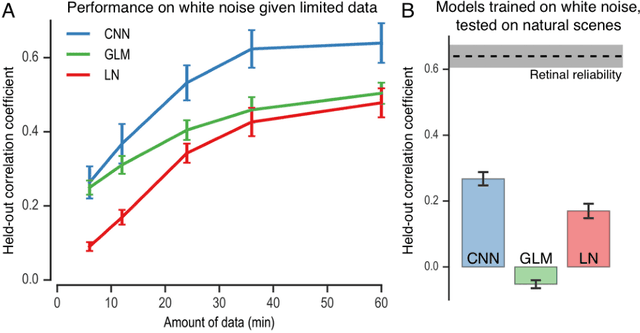
A central challenge in neuroscience is to understand neural computations and circuit mechanisms that underlie the encoding of ethologically relevant, natural stimuli. In multilayered neural circuits, nonlinear processes such as synaptic transmission and spiking dynamics present a significant obstacle to the creation of accurate computational models of responses to natural stimuli. Here we demonstrate that deep convolutional neural networks (CNNs) capture retinal responses to natural scenes nearly to within the variability of a cell's response, and are markedly more accurate than linear-nonlinear (LN) models and Generalized Linear Models (GLMs). Moreover, we find two additional surprising properties of CNNs: they are less susceptible to overfitting than their LN counterparts when trained on small amounts of data, and generalize better when tested on stimuli drawn from a different distribution (e.g. between natural scenes and white noise). Examination of trained CNNs reveals several properties. First, a richer set of feature maps is necessary for predicting the responses to natural scenes compared to white noise. Second, temporally precise responses to slowly varying inputs originate from feedforward inhibition, similar to known retinal mechanisms. Third, the injection of latent noise sources in intermediate layers enables our model to capture the sub-Poisson spiking variability observed in retinal ganglion cells. Fourth, augmenting our CNNs with recurrent lateral connections enables them to capture contrast adaptation as an emergent property of accurately describing retinal responses to natural scenes. These methods can be readily generalized to other sensory modalities and stimulus ensembles. Overall, this work demonstrates that CNNs not only accurately capture sensory circuit responses to natural scenes, but also yield information about the circuit's internal structure and function.
* L.T.M. and N.M. contributed equally to this work. Presented at NIPS 2016
Survey of Expressivity in Deep Neural Networks
Nov 24, 2016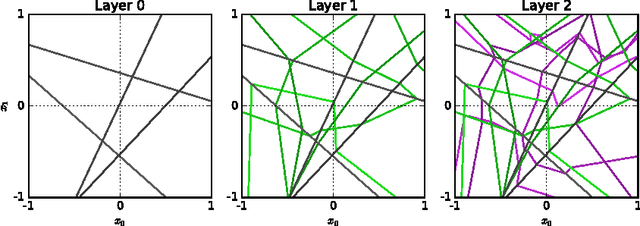

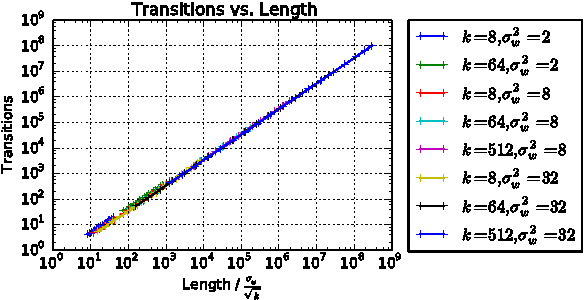
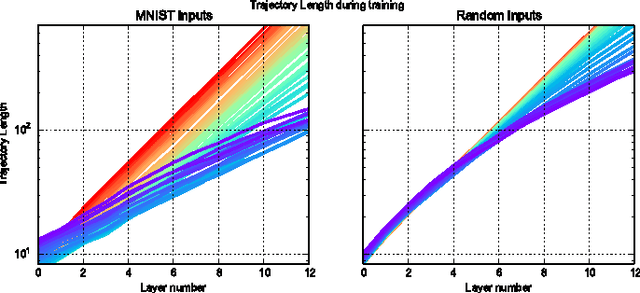
We survey results on neural network expressivity described in "On the Expressive Power of Deep Neural Networks". The paper motivates and develops three natural measures of expressiveness, which all display an exponential dependence on the depth of the network. In fact, all of these measures are related to a fourth quantity, trajectory length. This quantity grows exponentially in the depth of the network, and is responsible for the depth sensitivity observed. These results translate to consequences for networks during and after training. They suggest that parameters earlier in a network have greater influence on its expressive power -- in particular, given a layer, its influence on expressivity is determined by the remaining depth of the network after that layer. This is verified with experiments on MNIST and CIFAR-10. We also explore the effect of training on the input-output map, and find that it trades off between the stability and expressivity.
An equivalence between high dimensional Bayes optimal inference and M-estimation
Sep 22, 2016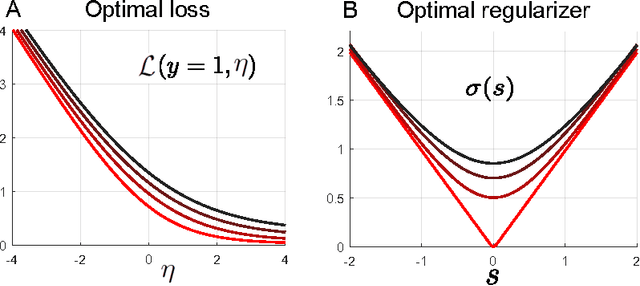
When recovering an unknown signal from noisy measurements, the computational difficulty of performing optimal Bayesian MMSE (minimum mean squared error) inference often necessitates the use of maximum a posteriori (MAP) inference, a special case of regularized M-estimation, as a surrogate. However, MAP is suboptimal in high dimensions, when the number of unknown signal components is similar to the number of measurements. In this work we demonstrate, when the signal distribution and the likelihood function associated with the noise are both log-concave, that optimal MMSE performance is asymptotically achievable via another M-estimation procedure. This procedure involves minimizing convex loss and regularizer functions that are nonlinearly smoothed versions of the widely applied MAP optimization problem. Our findings provide a new heuristic derivation and interpretation for recent optimal M-estimators found in the setting of linear measurements and additive noise, and further extend these results to nonlinear measurements with non-additive noise. We numerically demonstrate superior performance of our optimal M-estimators relative to MAP. Overall, at the heart of our work is the revelation of a remarkable equivalence between two seemingly very different computational problems: namely that of high dimensional Bayesian integration underlying MMSE inference, and high dimensional convex optimization underlying M-estimation. In essence we show that the former difficult integral may be computed by solving the latter, simpler optimization problem.
Random projections of random manifolds
Sep 10, 2016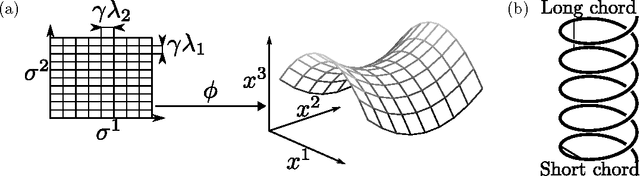
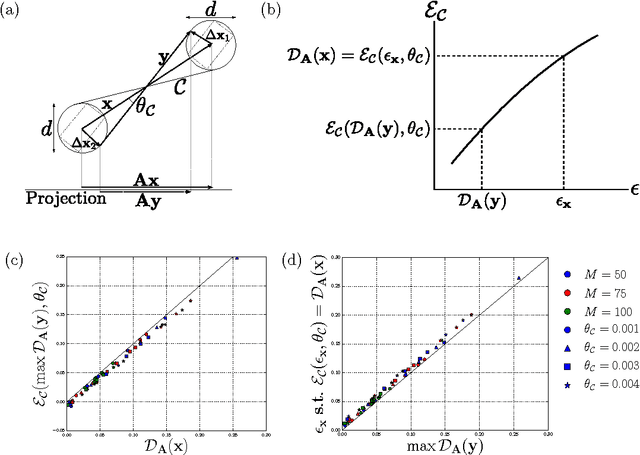
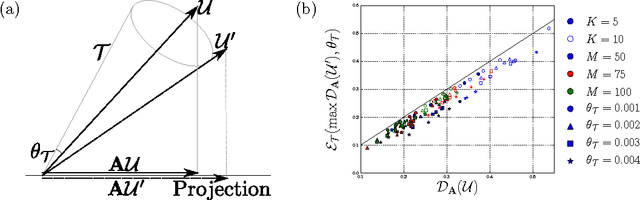
Interesting data often concentrate on low dimensional smooth manifolds inside a high dimensional ambient space. Random projections are a simple, powerful tool for dimensionality reduction of such data. Previous works have studied bounds on how many projections are needed to accurately preserve the geometry of these manifolds, given their intrinsic dimensionality, volume and curvature. However, such works employ definitions of volume and curvature that are inherently difficult to compute. Therefore such theory cannot be easily tested against numerical simulations to understand the tightness of the proven bounds. We instead study typical distortions arising in random projections of an ensemble of smooth Gaussian random manifolds. We find explicitly computable, approximate theoretical bounds on the number of projections required to accurately preserve the geometry of these manifolds. Our bounds, while approximate, can only be violated with a probability that is exponentially small in the ambient dimension, and therefore they hold with high probability in cases of practical interest. Moreover, unlike previous work, we test our theoretical bounds against numerical experiments on the actual geometric distortions that typically occur for random projections of random smooth manifolds. We find our bounds are tighter than previous results by several orders of magnitude.
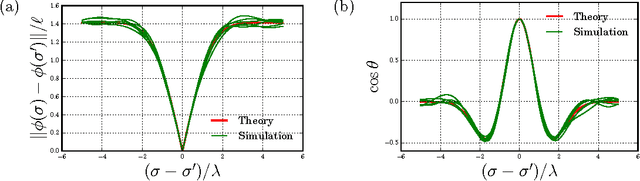
Exponential expressivity in deep neural networks through transient chaos
Jun 17, 2016
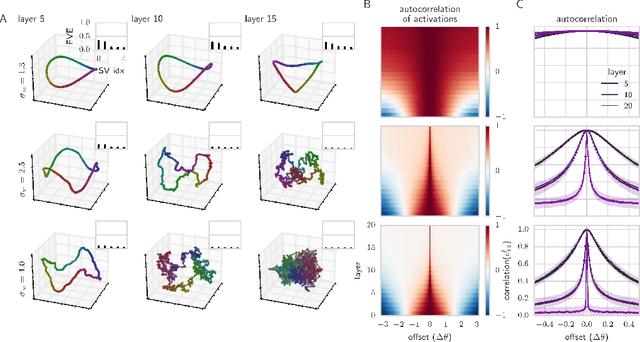
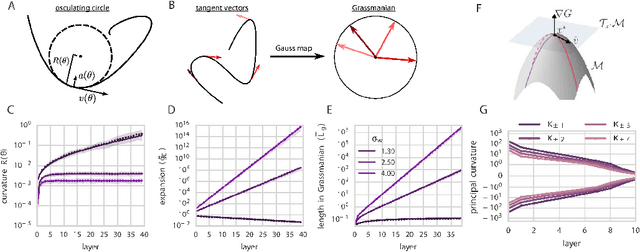
We combine Riemannian geometry with the mean field theory of high dimensional chaos to study the nature of signal propagation in generic, deep neural networks with random weights. Our results reveal an order-to-chaos expressivity phase transition, with networks in the chaotic phase computing nonlinear functions whose global curvature grows exponentially with depth but not width. We prove this generic class of deep random functions cannot be efficiently computed by any shallow network, going beyond prior work restricted to the analysis of single functions. Moreover, we formalize and quantitatively demonstrate the long conjectured idea that deep networks can disentangle highly curved manifolds in input space into flat manifolds in hidden space. Our theoretical analysis of the expressive power of deep networks broadly applies to arbitrary nonlinearities, and provides a quantitative underpinning for previously abstract notions about the geometry of deep functions.
A universal tradeoff between power, precision and speed in physical communication
Mar 24, 2016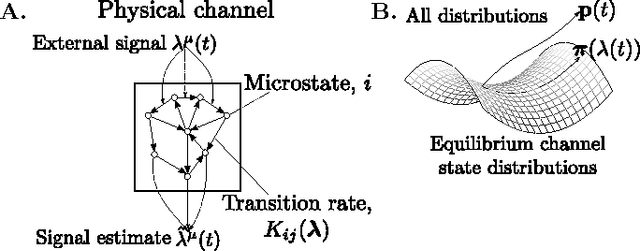
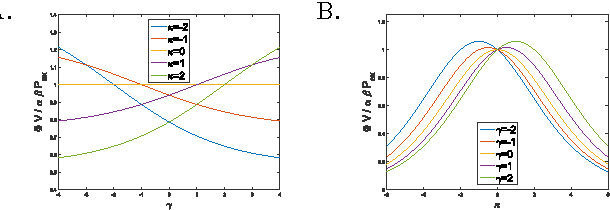
Maximizing the speed and precision of communication while minimizing power dissipation is a fundamental engineering design goal. Also, biological systems achieve remarkable speed, precision and power efficiency using poorly understood physical design principles. Powerful theories like information theory and thermodynamics do not provide general limits on power, precision and speed. Here we go beyond these classical theories to prove that the product of precision and speed is universally bounded by power dissipation in any physical communication channel whose dynamics is faster than that of the signal. Moreover, our derivation involves a novel connection between friction and information geometry. These results may yield insight into both the engineering design of communication devices and the structure and function of biological signaling systems.