 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Techniques for Cone Beam Computed Tomography in Dentistry: Trends and Practices
Jun 06, 2023Cone-beam computed tomography (CBCT) is a popular imaging modality in dentistry for diagnosing and planning treatment for a variety of oral diseases with the ability to produce detailed, three-dimensional images of the teeth, jawbones, and surrounding structures. CBCT imaging has emerged as an essential diagnostic tool in dentistry. CBCT imaging has seen significant improvements in terms of its diagnostic value, as well as its accuracy and efficiency, with the most recent development of artificial intelligence (AI) techniques. This paper reviews recent AI trends and practices in dental CBCT imaging. AI has been used for lesion detection, malocclusion classification, measurement of buccal bone thickness, and classification and segmentation of teeth, alveolar bones, mandibles, landmarks, contours, and pharyngeal airways using CBCT images. Mainly machine learning algorithms, deep learning algorithms, and super-resolution techniques are used for these tasks. This review focuses on the potential of AI techniques to transform CBCT imaging in dentistry, which would improve both diagnosis and treatment planning. Finally, we discuss the challenges and limitations of artificial intelligence in dentistry and CBCT imaging.
IJCB 2022 Mobile Behavioral Biometrics Competition (MobileB2C)
Oct 06, 2022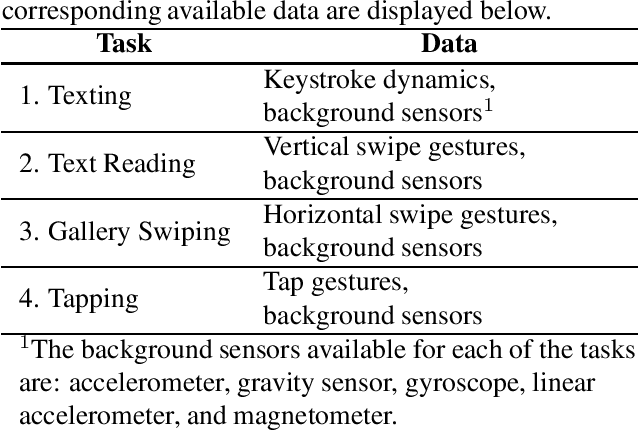
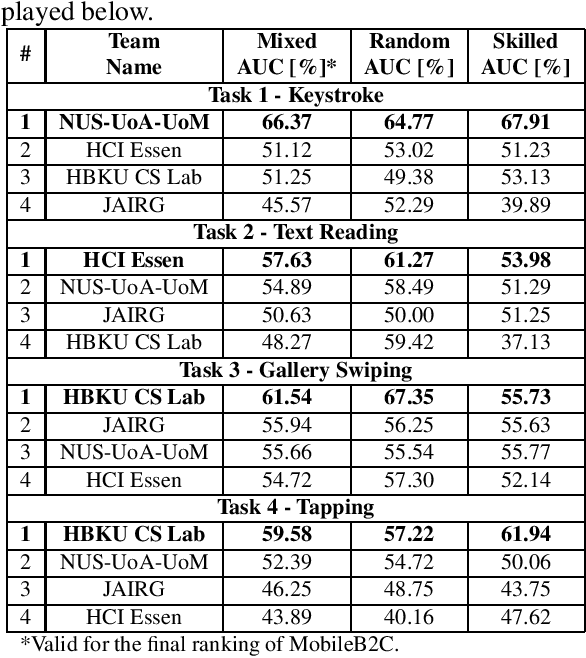
This paper describes the experimental framework and results of the IJCB 2022 Mobile Behavioral Biometrics Competition (MobileB2C). The aim of MobileB2C is benchmarking mobile user authentication systems based on behavioral biometric traits transparently acquired by mobile devices during ordinary Human-Computer Interaction (HCI), using a novel public database, BehavePassDB, and a standard experimental protocol. The competition is divided into four tasks corresponding to typical user activities: keystroke, text reading, gallery swiping, and tapping. The data are composed of touchscreen data and several background sensor data simultaneously acquired. "Random" (different users with different devices) and "skilled" (different user on the same device attempting to imitate the legitimate one) impostor scenarios are considered. The results achieved by the participants show the feasibility of user authentication through behavioral biometrics, although this proves to be a non-trivial challenge. MobileB2C will be established as an on-going competition.
SVC-onGoing: Signature Verification Competition
Aug 13, 2021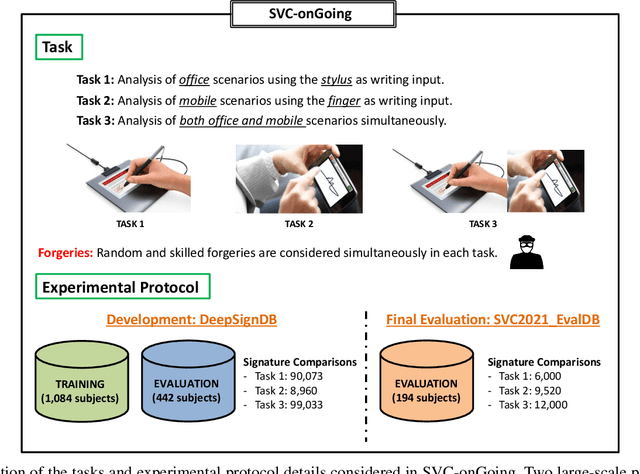
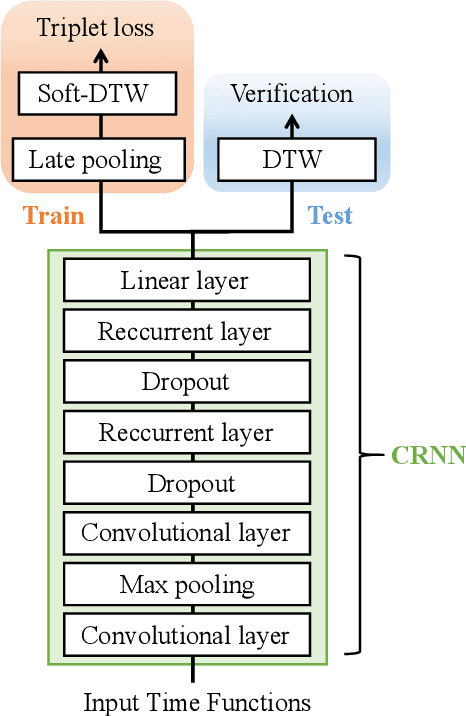
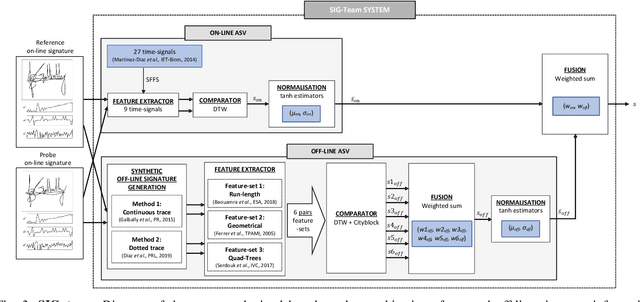
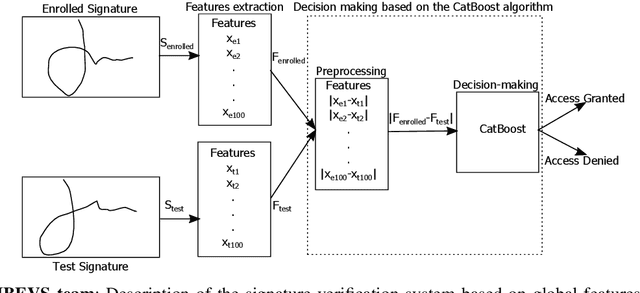
This article presents SVC-onGoing, an on-going competition for on-line signature verification where researchers can easily benchmark their systems against the state of the art in an open common platform using large-scale public databases, such as DeepSignDB and SVC2021_EvalDB, and standard experimental protocols. SVC-onGoing is based on the ICDAR 2021 Competition on On-Line Signature Verification (SVC 2021), which has been extended to allow participants anytime. The goal of SVC-onGoing is to evaluate the limits of on-line signature verification systems on popular scenarios (office/mobile) and writing inputs (stylus/finger) through large-scale public databases. Three different tasks are considered in the competition, simulating realistic scenarios as both random and skilled forgeries are simultaneously considered on each task. The results obtained in SVC-onGoing prove the high potential of deep learning methods in comparison with traditional methods. In particular, the best signature verification system has obtained Equal Error Rate (EER) values of 3.33% (Task 1), 7.41% (Task 2), and 6.04% (Task 3). Future studies in the field should be oriented to improve the performance of signature verification systems on the challenging mobile scenarios of SVC-onGoing in which several mobile devices and the finger are used during the signature acquisition.
ICDAR 2021 Competition on On-Line Signature Verification
Jun 01, 2021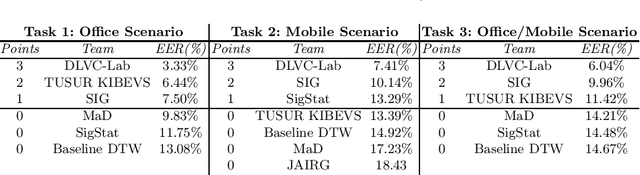
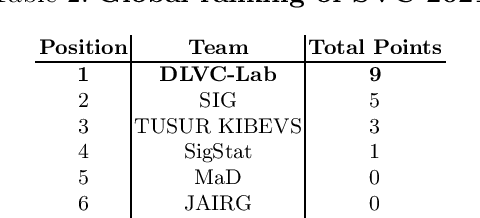
This paper describes the experimental framework and results of the ICDAR 2021 Competition on On-Line Signature Verification (SVC 2021). The goal of SVC 2021 is to evaluate the limits of on-line signature verification systems on popular scenarios (office/mobile) and writing inputs (stylus/finger) through large-scale public databases. Three different tasks are considered in the competition, simulating realistic scenarios as both random and skilled forgeries are simultaneously considered on each task. The results obtained in SVC 2021 prove the high potential of deep learning methods. In particular, the best on-line signature verification system of SVC 2021 obtained Equal Error Rate (EER) values of 3.33% (Task 1), 7.41% (Task 2), and 6.04% (Task 3). SVC 2021 will be established as an on-going competition, where researchers can easily benchmark their systems against the state of the art in an open common platform using large-scale public databases such as DeepSignDB and SVC2021_EvalDB, and standard experimental protocols.
A Novel data Pre-processing method for multi-dimensional and non-uniform data
Aug 05, 2017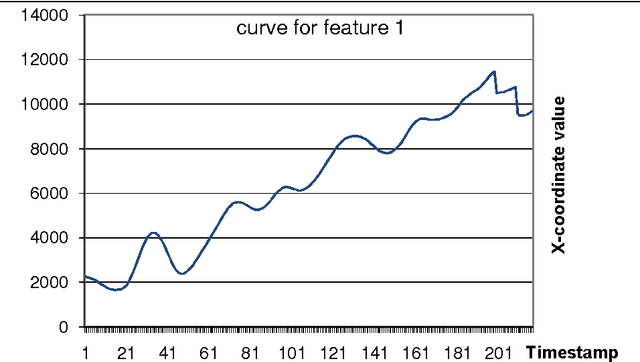
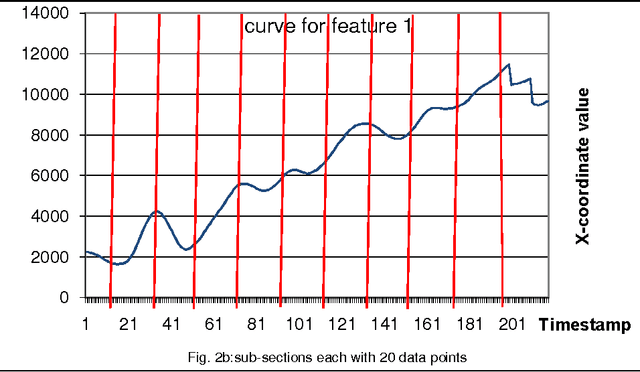
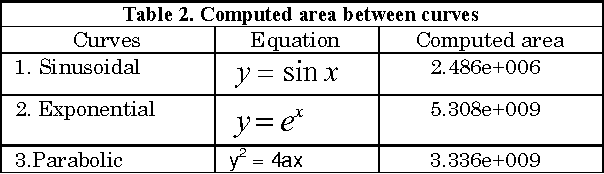
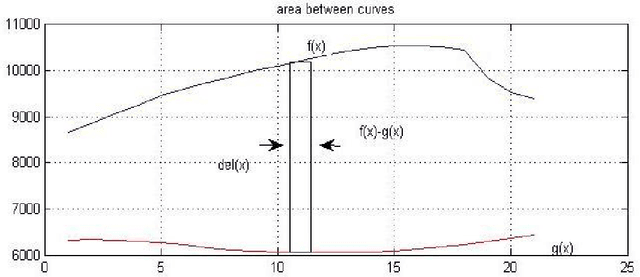
We are in the era of data analytics and data science which is on full bloom. There is abundance of all kinds of data for example biometrics based data, satellite images data, chip-seq data, social network data, sensor based data etc. from a variety of sources. This data abundance is the result of the fact that storage cost is getting cheaper day by day, so people as well as almost all business or scientific organizations are storing more and more data. Most of the real data is multi-dimensional, non-uniform, and big in size, such that it requires a unique pre-processing before analyzing it. In order to make data useful for any kind of analysis, pre-processing is a very important step. This paper presents a unique and novel pre-processing method for multi-dimensional and non-uniform data with the aim of making it uniform and reduced in size without losing much of its value. We have chosen biometric signature data to demonstrate the proposed method as it qualifies for the attributes of being multi-dimensional, non-uniform and big in size. Biometric signature data does not only captures the structural characteristics of a signature but also its behavioral characteristics that are captured using a dynamic signature capture device. These features like pen pressure, pen tilt angle, time taken to sign a document when collected in real-time turn out to be of varying dimensions. This feature data set along with the structural data needs to be pre-processed in order to use it to train a machine learning based model for signature verification purposes. We demonstrate the success of the proposed method over other methods using experimental results for biometric signature data but the same can be implemented for any other data with similar properties from a different domain.