 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Smartphone Cluster for Deep Learning
Oct 23, 2021
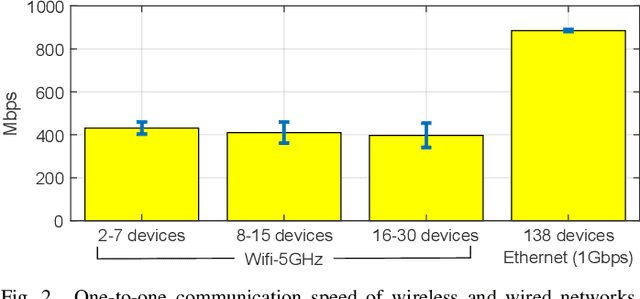
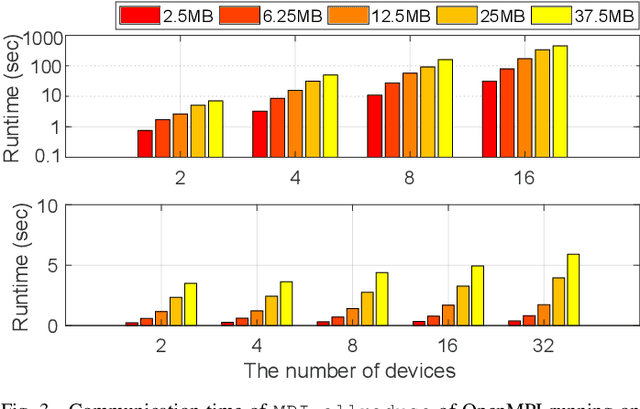
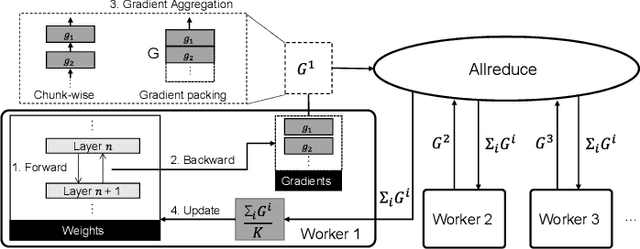
Various deep learning applications on smartphones have been rapidly rising, but training deep neural networks (DNNs) has too large computational burden to be executed on a single smartphone. A portable cluster, which connects smartphones with a wireless network and supports parallel computation using them, can be a potential approach to resolve the issue. However, by our findings, the limitations of wireless communication restrict the cluster size to up to 30 smartphones. Such small-scale clusters have insufficient computational power to train DNNs from scratch. In this paper, we propose a scalable smartphone cluster enabling deep learning training by removing the portability to increase its computational efficiency. The cluster connects 138 Galaxy S10+ devices with a wired network using Ethernet. We implemented large-batch synchronous training of DNNs based on Caffe, a deep learning library. The smartphone cluster yielded 90% of the speed of a P100 when training ResNet-50, and approximately 43x speed-up of a V100 when training MobileNet-v1.
Reducing Information Bottleneck for Weakly Supervised Semantic Segmentation
Oct 13, 2021
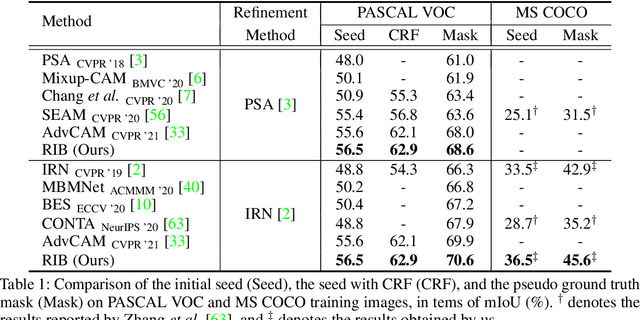
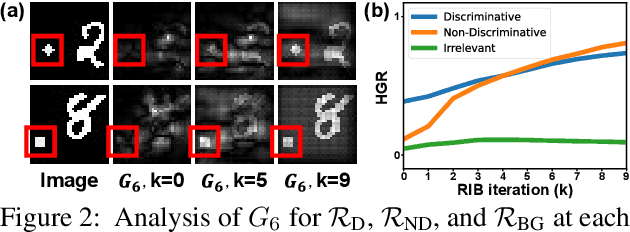
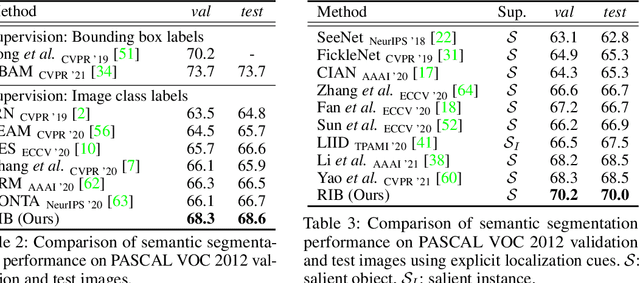
Weakly supervised semantic segmentation produces pixel-level localization from class labels; however, a classifier trained on such labels is likely to focus on a small discriminative region of the target object. We interpret this phenomenon using the information bottleneck principle: the final layer of a deep neural network, activated by the sigmoid or softmax activation functions, causes an information bottleneck, and as a result, only a subset of the task-relevant information is passed on to the output. We first support this argument through a simulated toy experiment and then propose a method to reduce the information bottleneck by removing the last activation function. In addition, we introduce a new pooling method that further encourages the transmission of information from non-discriminative regions to the classification. Our experimental evaluations demonstrate that this simple modification significantly improves the quality of localization maps on both the PASCAL VOC 2012 and MS COCO 2014 datasets, exhibiting a new state-of-the-art performance for weakly supervised semantic segmentation. The code is available at: https://github.com/jbeomlee93/RIB.
FICGAN: Facial Identity Controllable GAN for De-identification
Oct 02, 2021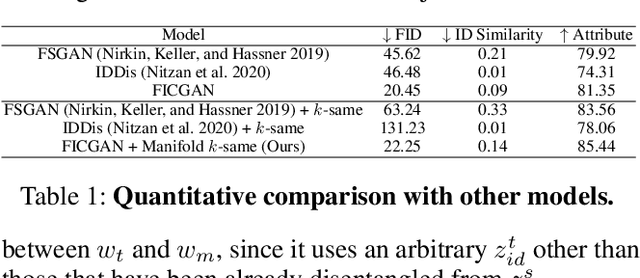
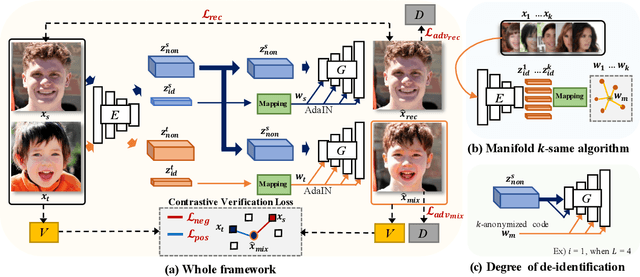


In this work, we present Facial Identity Controllable GAN (FICGAN) for not only generating high-quality de-identified face images with ensured privacy protection, but also detailed controllability on attribute preservation for enhanced data utility. We tackle the less-explored yet desired functionality in face de-identification based on the two factors. First, we focus on the challenging issue to obtain a high level of privacy protection in the de-identification task while uncompromising the image quality. Second, we analyze the facial attributes related to identity and non-identity and explore the trade-off between the degree of face de-identification and preservation of the source attributes for enhanced data utility. Based on the analysis, we develop Facial Identity Controllable GAN (FICGAN), an autoencoder-based conditional generative model that learns to disentangle the identity attributes from non-identity attributes on a face image. By applying the manifold k-same algorithm to satisfy k-anonymity for strengthened security, our method achieves enhanced privacy protection in de-identified face images. Numerous experiments demonstrate that our model outperforms others in various scenarios of face de-identification.
AligNART: Non-autoregressive Neural Machine Translation by Jointly Learning to Estimate Alignment and Translate
Sep 14, 2021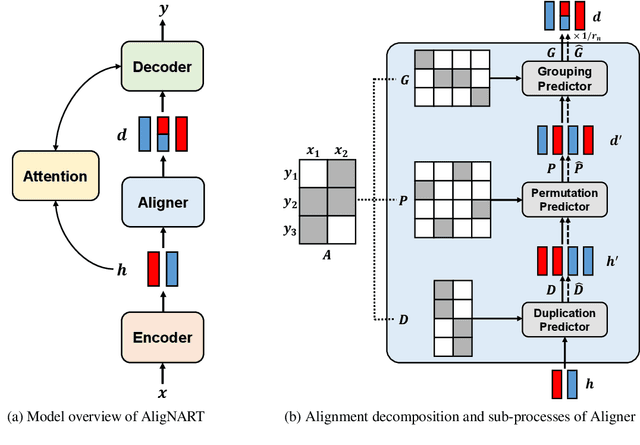
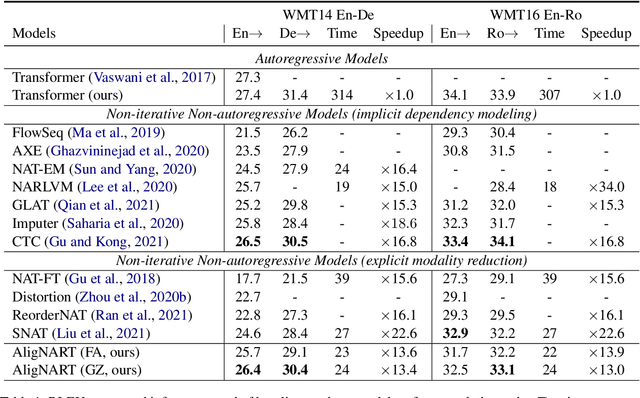
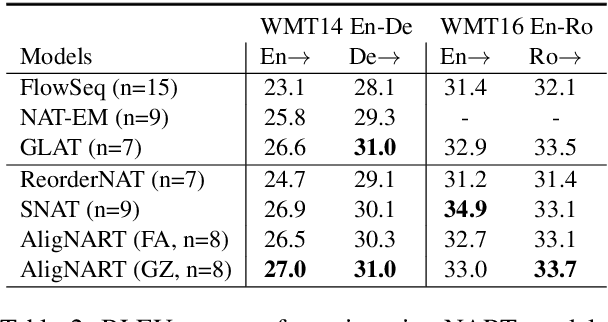
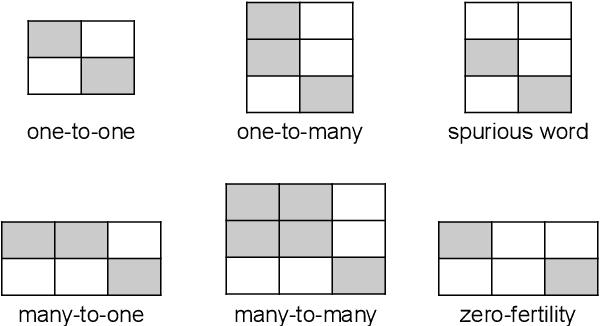
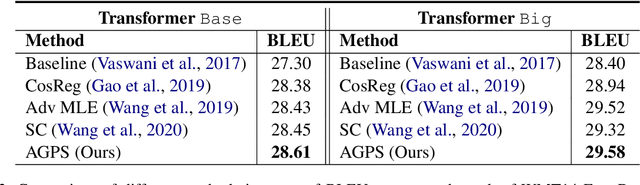
Non-autoregressive neural machine translation (NART) models suffer from the multi-modality problem which causes translation inconsistency such as token repetition. Most recent approaches have attempted to solve this problem by implicitly modeling dependencies between outputs. In this paper, we introduce AligNART, which leverages full alignment information to explicitly reduce the modality of the target distribution. AligNART divides the machine translation task into $(i)$ alignment estimation and $(ii)$ translation with aligned decoder inputs, guiding the decoder to focus on simplified one-to-one translation. To alleviate the alignment estimation problem, we further propose a novel alignment decomposition method. Our experiments show that AligNART outperforms previous non-iterative NART models that focus on explicit modality reduction on WMT14 En$\leftrightarrow$De and WMT16 Ro$\rightarrow$En. Furthermore, AligNART achieves BLEU scores comparable to those of the state-of-the-art connectionist temporal classification based models on WMT14 En$\leftrightarrow$De. We also observe that AligNART effectively addresses the token repetition problem even without sequence-level knowledge distillation.
Towards a Rigorous Evaluation of Time-series Anomaly Detection
Sep 11, 2021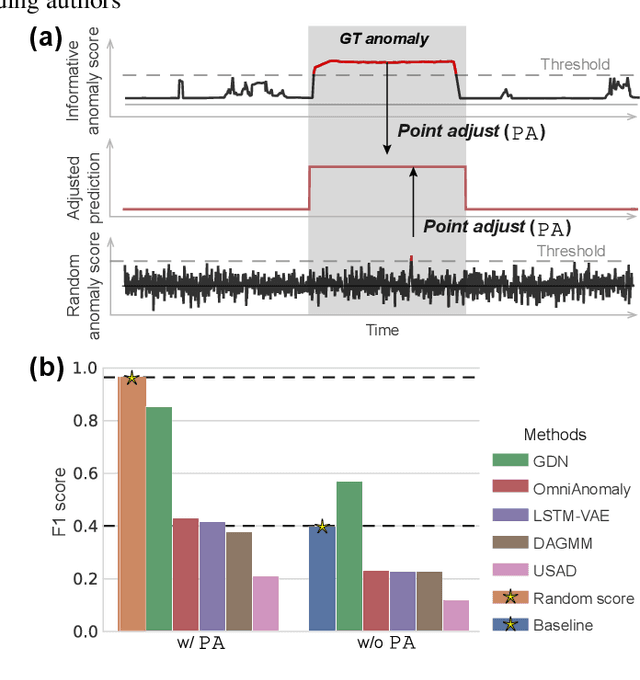
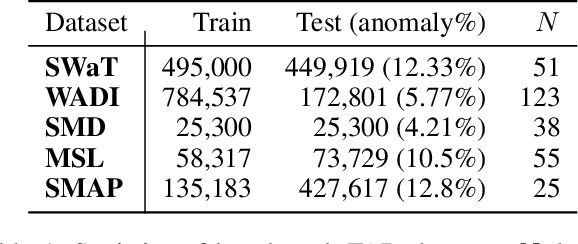
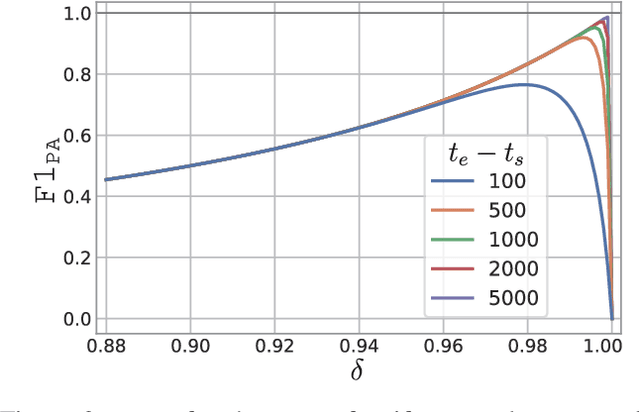
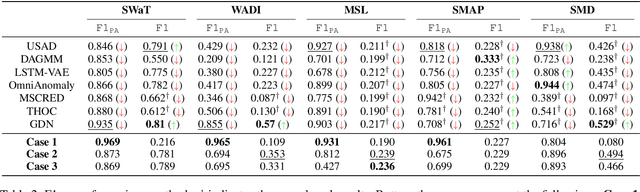
In recent years, proposed studies on time-series anomaly detection (TAD) report high F1 scores on benchmark TAD datasets, giving the impression of clear improvements. However, most studies apply a peculiar evaluation protocol called point adjustment (PA) before scoring. In this paper, we theoretically and experimentally reveal that the PA protocol has a great possibility of overestimating the detection performance; that is, even a random anomaly score can easily turn into a state-of-the-art TAD method. Therefore, the comparison of TAD methods with F1 scores after the PA protocol can lead to misguided rankings. Furthermore, we question the potential of existing TAD methods by showing that an untrained model obtains comparable detection performance to the existing methods even without PA. Based on our findings, we propose a new baseline and an evaluation protocol. We expect that our study will help a rigorous evaluation of TAD and lead to further improvement in future researches.
Rare Words Degenerate All Words
Sep 07, 2021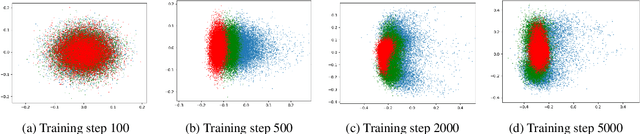

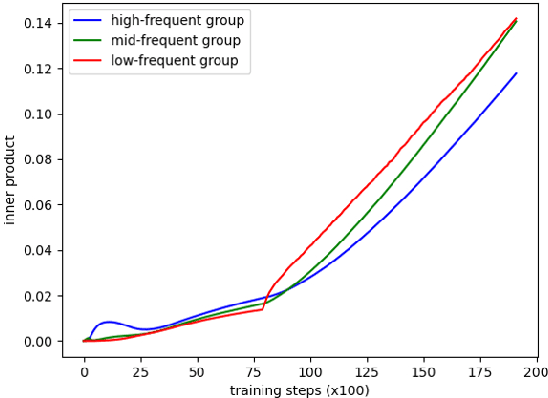
Despite advances in neural network language model, the representation degeneration problem of embeddings is still challenging. Recent studies have found that the learned output embeddings are degenerated into a narrow-cone distribution which makes the similarity between each embeddings positive. They analyzed the cause of the degeneration problem has been demonstrated as common to most embeddings. However, we found that the degeneration problem is especially originated from the training of embeddings of rare words. In this study, we analyze the intrinsic mechanism of the degeneration of rare word embeddings with respect of their gradient about the negative log-likelihood loss function. Furthermore, we theoretically and empirically demonstrate that the degeneration of rare word embeddings causes the degeneration of non-rare word embeddings, and that the overall degeneration problem can be alleviated by preventing the degeneration of rare word embeddings. Based on our analyses, we propose a novel method, Adaptive Gradient Partial Scaling(AGPS), to address the degeneration problem. Experimental results demonstrate the effectiveness of the proposed method qualitatively and quantitatively.
AdvRush: Searching for Adversarially Robust Neural Architectures
Aug 10, 2021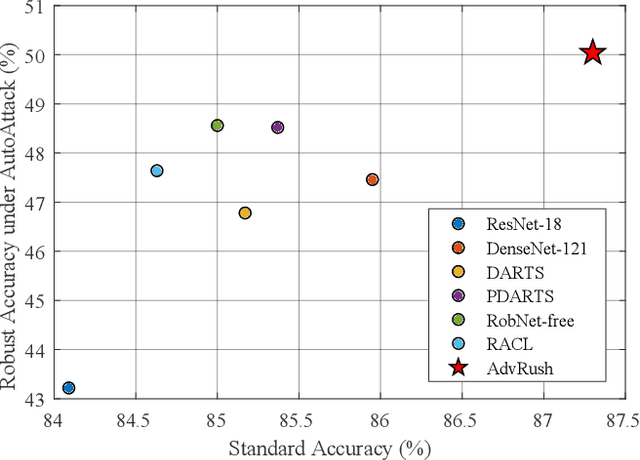
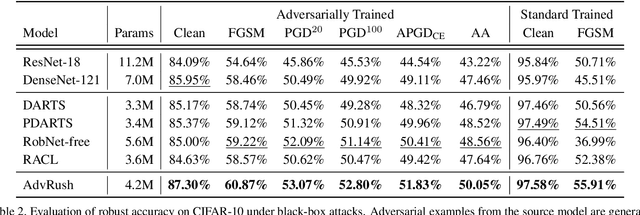
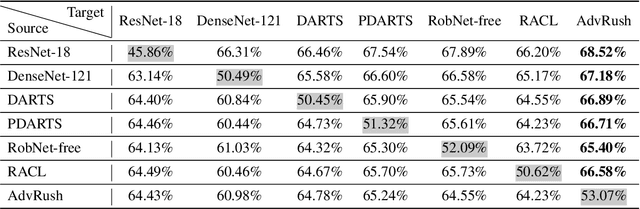
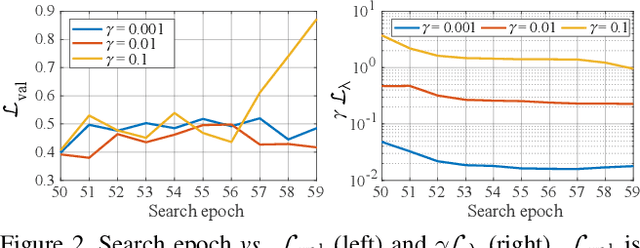
Deep neural networks continue to awe the world with their remarkable performance. Their predictions, however, are prone to be corrupted by adversarial examples that are imperceptible to humans. Current efforts to improve the robustness of neural networks against adversarial examples are focused on developing robust training methods, which update the weights of a neural network in a more robust direction. In this work, we take a step beyond training of the weight parameters and consider the problem of designing an adversarially robust neural architecture with high intrinsic robustness. We propose AdvRush, a novel adversarial robustness-aware neural architecture search algorithm, based upon a finding that independent of the training method, the intrinsic robustness of a neural network can be represented with the smoothness of its input loss landscape. Through a regularizer that favors a candidate architecture with a smoother input loss landscape, AdvRush successfully discovers an adversarially robust neural architecture. Along with a comprehensive theoretical motivation for AdvRush, we conduct an extensive amount of experiments to demonstrate the efficacy of AdvRush on various benchmark datasets. Notably, on CIFAR-10, AdvRush achieves 55.91% robust accuracy under FGSM attack after standard training and 50.04% robust accuracy under AutoAttack after 7-step PGD adversarial training.
ILVR: Conditioning Method for Denoising Diffusion Probabilistic Models
Aug 06, 2021
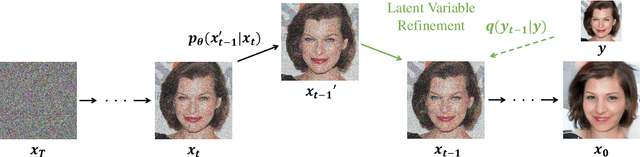

Denoising diffusion probabilistic models (DDPM) have shown remarkable performance in unconditional image generation. However, due to the stochasticity of the generative process in DDPM, it is challenging to generate images with the desired semantics. In this work, we propose Iterative Latent Variable Refinement (ILVR), a method to guide the generative process in DDPM to generate high-quality images based on a given reference image. Here, the refinement of the generative process in DDPM enables a single DDPM to sample images from various sets directed by the reference image. The proposed ILVR method generates high-quality images while controlling the generation. The controllability of our method allows adaptation of a single DDPM without any additional learning in various image generation tasks, such as generation from various downsampling factors, multi-domain image translation, paint-to-image, and editing with scribbles.
Toward Spatially Unbiased Generative Models
Aug 03, 2021
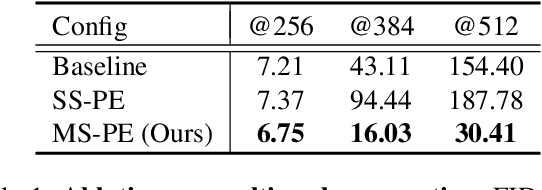
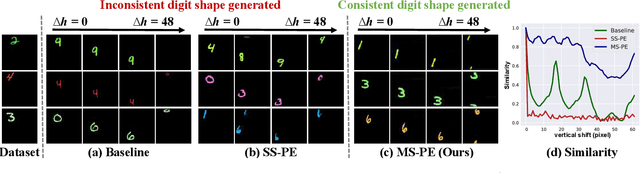
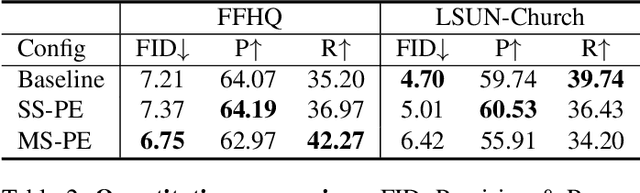
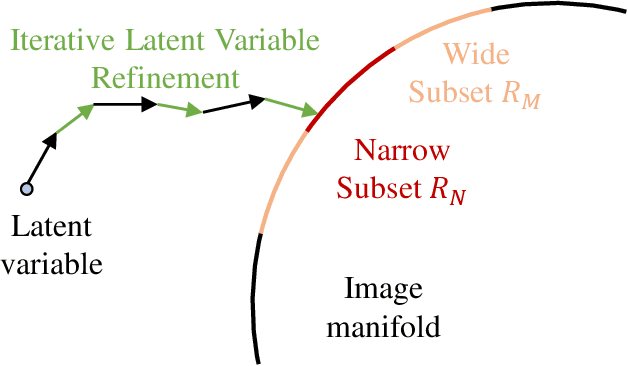
Recent image generation models show remarkable generation performance. However, they mirror strong location preference in datasets, which we call spatial bias. Therefore, generators render poor samples at unseen locations and scales. We argue that the generators rely on their implicit positional encoding to render spatial content. From our observations, the generator's implicit positional encoding is translation-variant, making the generator spatially biased. To address this issue, we propose injecting explicit positional encoding at each scale of the generator. By learning the spatially unbiased generator, we facilitate the robust use of generators in multiple tasks, such as GAN inversion, multi-scale generation, generation of arbitrary sizes and aspect ratios. Furthermore, we show that our method can also be applied to denoising diffusion probabilistic models.
TargetNet: Functional microRNA Target Prediction with Deep Neural Networks
Jul 23, 2021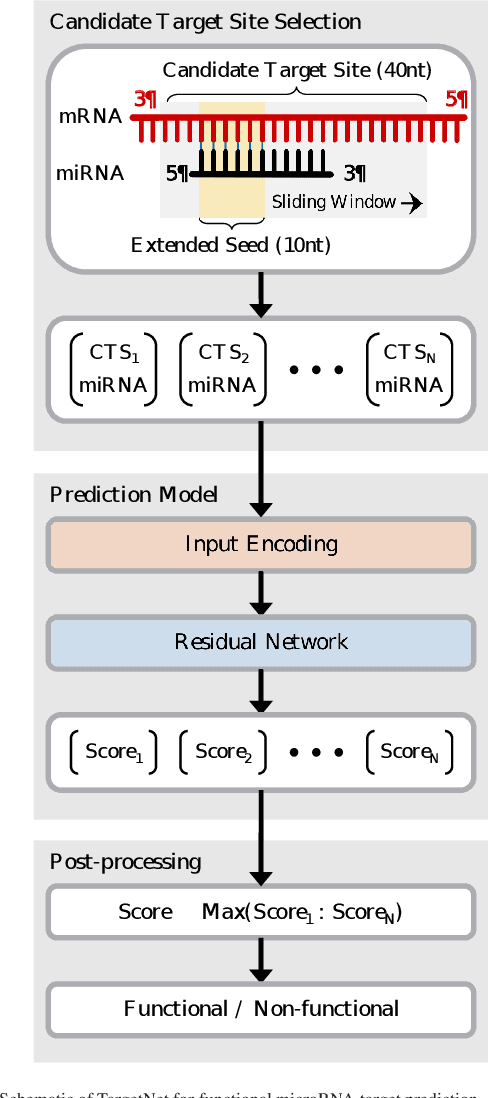
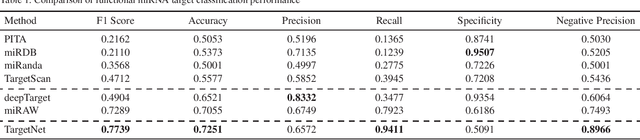
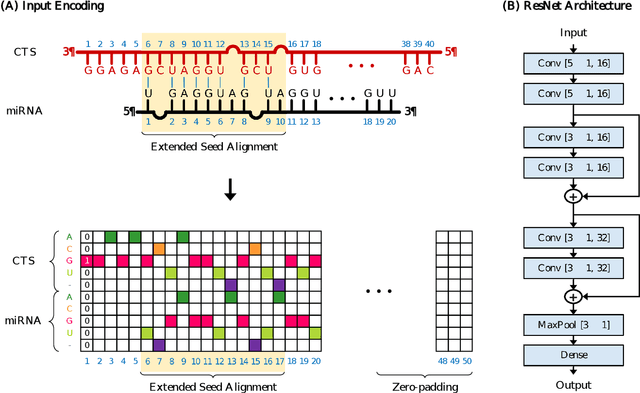
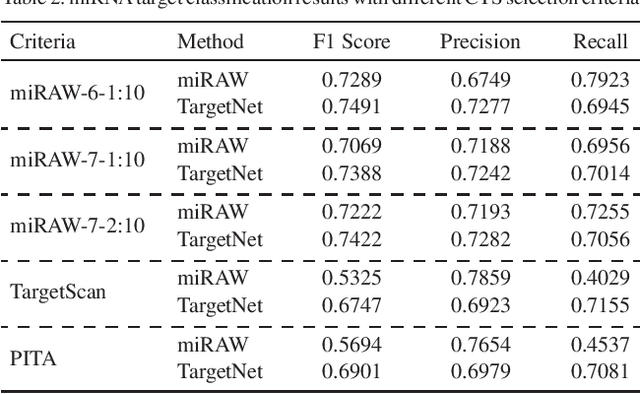
MicroRNAs (miRNAs) play pivotal roles in gene expression regulation by binding to target sites of messenger RNAs (mRNAs). While identifying functional targets of miRNAs is of utmost importance, their prediction remains a great challenge. Previous computational algorithms have major limitations. They use conservative candidate target site (CTS) selection criteria mainly focusing on canonical site types, rely on laborious and time-consuming manual feature extraction, and do not fully capitalize on the information underlying miRNA-CTS interactions. In this paper, we introduce TargetNet, a novel deep learning-based algorithm for functional miRNA target prediction. To address the limitations of previous approaches, TargetNet has three key components: (1) relaxed CTS selection criteria accommodating irregularities in the seed region, (2) a novel miRNA-CTS sequence encoding scheme incorporating extended seed region alignments, and (3) a deep residual network-based prediction model. The proposed model was trained with miRNA-CTS pair datasets and evaluated with miRNA-mRNA pair datasets. TargetNet advances the previous state-of-the-art algorithms used in functional miRNA target classification. Furthermore, it demonstrates great potential for distinguishing high-functional miRNA targets.