 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCKNN: Cleansed k-Nearest Neighbor for Unsupervised Video Anomaly Detection
Aug 06, 2024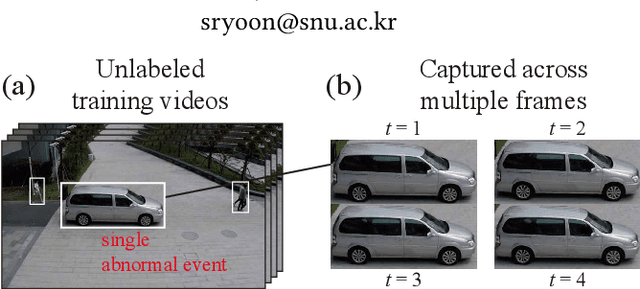
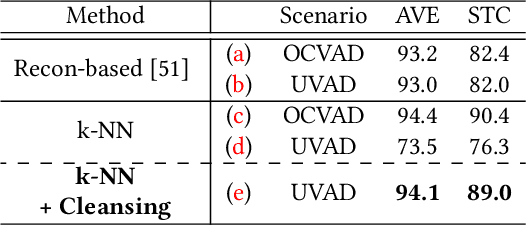
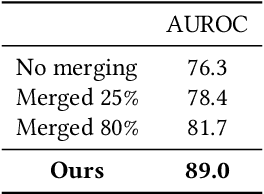
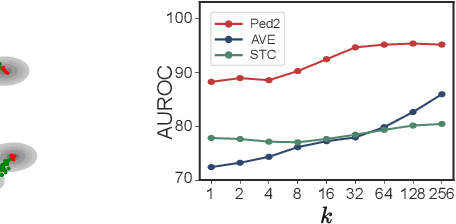
In this paper, we address the problem of unsupervised video anomaly detection (UVAD). The task aims to detect abnormal events in test video using unlabeled videos as training data. The presence of anomalies in the training data poses a significant challenge in this task, particularly because they form clusters in the feature space. We refer to this property as the "Anomaly Cluster" issue. The condensed nature of these anomalies makes it difficult to distinguish between normal and abnormal data in the training set. Consequently, training conventional anomaly detection techniques using an unlabeled dataset often leads to sub-optimal results. To tackle this difficulty, we propose a new method called Cleansed k-Nearest Neighbor (CKNN), which explicitly filters out the Anomaly Clusters by cleansing the training dataset. Following the k-nearest neighbor algorithm in the feature space provides powerful anomaly detection capability. Although the identified Anomaly Cluster issue presents a significant challenge to applying k-nearest neighbor in UVAD, our proposed cleansing scheme effectively addresses this problem. We evaluate the proposed method on various benchmark datasets and demonstrate that CKNN outperforms the previous state-of-the-art UVAD method by up to 8.5% (from 82.0 to 89.0) in terms of AUROC. Moreover, we emphasize that the performance of the proposed method is comparable to that of the state-of-the-art method trained using anomaly-free data.
Correcting Negative Bias in Large Language Models through Negative Attention Score Alignment
Jul 31, 2024



A binary decision task, like yes-no questions or answer verification, reflects a significant real-world scenario such as where users look for confirmation about the correctness of their decisions on specific issues. In this work, we observe that language models exhibit a negative bias in the binary decisions of complex reasoning tasks. Based on our observations and the rationale about attention-based model dynamics, we propose a negative attention score (NAS) to systematically and quantitatively formulate negative bias. Based on NAS, we identify attention heads that attend to negative tokens provided in the instructions as answer candidate of binary decisions, regardless of the question in the prompt, and validate their association with the negative bias. Additionally, we propose the negative attention score alignment (NASA) method, which is a parameter-efficient fine-tuning technique to address the extracted negatively biased attention heads. Experimental results from various domains of reasoning tasks and large model search space demonstrate that NASA significantly reduces the gap between precision and recall caused by negative bias while preserving their generalization abilities. Our codes are available at \url{https://github.com/ysw1021/NASA}.
Normality Addition via Normality Detection in Industrial Image Anomaly Detection Models
Jul 29, 2024



The task of image anomaly detection (IAD) aims to identify deviations from normality in image data. These anomalies are patterns that deviate significantly from what the IAD model has learned from the data during training. However, in real-world scenarios, the criteria for what constitutes normality often change, necessitating the reclassification of previously anomalous instances as normal. To address this challenge, we propose a new scenario termed "normality addition," involving the post-training adjustment of decision boundaries to incorporate new normalities. To address this challenge, we propose a method called Normality Addition via Normality Detection (NAND), leveraging a vision-language model. NAND performs normality detection which detect patterns related to the intended normality within images based on textual descriptions. We then modify the results of a pre-trained IAD model to implement this normality addition. Using the benchmark dataset in IAD, MVTec AD, we establish an evaluation protocol for the normality addition task and empirically demonstrate the effectiveness of the NAND method.
Disentangled Motion Modeling for Video Frame Interpolation
Jun 25, 2024



Video frame interpolation (VFI) aims to synthesize intermediate frames in between existing frames to enhance visual smoothness and quality. Beyond the conventional methods based on the reconstruction loss, recent works employ the high quality generative models for perceptual quality. However, they require complex training and large computational cost for modeling on the pixel space. In this paper, we introduce disentangled Motion Modeling (MoMo), a diffusion-based approach for VFI that enhances visual quality by focusing on intermediate motion modeling. We propose disentangled two-stage training process, initially training a frame synthesis model to generate frames from input pairs and their optical flows. Subsequently, we propose a motion diffusion model, equipped with our novel diffusion U-Net architecture designed for optical flow, to produce bi-directional flows between frames. This method, by leveraging the simpler low-frequency representation of motions, achieves superior perceptual quality with reduced computational demands compared to generative modeling methods on the pixel space. Our method surpasses state-of-the-art methods in perceptual metrics across various benchmarks, demonstrating its efficacy and efficiency in VFI. Our code is available at: https://github.com/JHLew/MoMo
Large Language Models are Skeptics: False Negative Problem of Input-conflicting Hallucination
Jun 20, 2024In this paper, we identify a new category of bias that induces input-conflicting hallucinations, where large language models (LLMs) generate responses inconsistent with the content of the input context. This issue we have termed the false negative problem refers to the phenomenon where LLMs are predisposed to return negative judgments when assessing the correctness of a statement given the context. In experiments involving pairs of statements that contain the same information but have contradictory factual directions, we observe that LLMs exhibit a bias toward false negatives. Specifically, the model presents greater overconfidence when responding with False. Furthermore, we analyze the relationship between the false negative problem and context and query rewriting and observe that both effectively tackle false negatives in LLMs.
Self-Supervised Time-Series Anomaly Detection Using Learnable Data Augmentation
Jun 18, 2024Continuous efforts are being made to advance anomaly detection in various manufacturing processes to increase the productivity and safety of industrial sites. Deep learning replaced rule-based methods and recently emerged as a promising method for anomaly detection in diverse industries. However, in the real world, the scarcity of abnormal data and difficulties in obtaining labeled data create limitations in the training of detection models. In this study, we addressed these shortcomings by proposing a learnable data augmentation-based time-series anomaly detection (LATAD) technique that is trained in a self-supervised manner. LATAD extracts discriminative features from time-series data through contrastive learning. At the same time, learnable data augmentation produces challenging negative samples to enhance learning efficiency. We measured anomaly scores of the proposed technique based on latent feature similarities. As per the results, LATAD exhibited comparable or improved performance to the state-of-the-art anomaly detection assessments on several benchmark datasets and provided a gradient-based diagnosis technique to help identify root causes.
Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach
Jun 05, 2024



In this paper, we primarily address the issue of dialogue-form context query within the interactive text-to-image retrieval task. Our methodology, PlugIR, actively utilizes the general instruction-following capability of LLMs in two ways. First, by reformulating the dialogue-form context, we eliminate the necessity of fine-tuning a retrieval model on existing visual dialogue data, thereby enabling the use of any arbitrary black-box model. Second, we construct the LLM questioner to generate non-redundant questions about the attributes of the target image, based on the information of retrieval candidate images in the current context. This approach mitigates the issues of noisiness and redundancy in the generated questions. Beyond our methodology, we propose a novel evaluation metric, Best log Rank Integral (BRI), for a comprehensive assessment of the interactive retrieval system. PlugIR demonstrates superior performance compared to both zero-shot and fine-tuned baselines in various benchmarks. Additionally, the two methodologies comprising PlugIR can be flexibly applied together or separately in various situations. Our codes are available at https://github.com/Saehyung-Lee/PlugIR.
Efficient Diffusion-Driven Corruption Editor for Test-Time Adaptation
Mar 19, 2024



Test-time adaptation (TTA) addresses the unforeseen distribution shifts occurring during test time. In TTA, both performance and, memory and time consumption serve as crucial considerations. A recent diffusion-based TTA approach for restoring corrupted images involves image-level updates. However, using pixel space diffusion significantly increases resource requirements compared to conventional model updating TTA approaches, revealing limitations as a TTA method. To address this, we propose a novel TTA method by leveraging a latent diffusion model (LDM) based image editing model and fine-tuning it with our newly introduced corruption modeling scheme. This scheme enhances the robustness of the diffusion model against distribution shifts by creating (clean, corrupted) image pairs and fine-tuning the model to edit corrupted images into clean ones. Moreover, we introduce a distilled variant to accelerate the model for corruption editing using only 4 network function evaluations (NFEs). We extensively validated our method across various architectures and datasets including image and video domains. Our model achieves the best performance with a 100 times faster runtime than that of a diffusion-based baseline. Furthermore, it outpaces the speed of the model updating TTA method based on data augmentation threefold, rendering an image-level updating approach more practical.
SF$^2$: Source-free Domain Adaptation Through the Lens of Data Augmentation
Mar 16, 2024



In the face of the deep learning model's vulnerability to domain shift, source-free domain adaptation (SFDA) methods have been proposed to adapt models to new, unseen target domains without requiring access to source domain data. Although the potential benefits of applying data augmentation to SFDA are attractive, several challenges arise such as the dependence on prior knowledge of class-preserving transformations and the increase in memory and computational requirements. In this paper, we propose Source-free Domain Adaptation Through the Lens of Data Augmentation (SF(DA)$^2$), a novel approach that leverages the benefits of data augmentation without suffering from these challenges. We construct an augmentation graph in the feature space of the pretrained model using the neighbor relationships between target features and propose spectral neighborhood clustering to identify partitions in the prediction space. Furthermore, we propose implicit feature augmentation and feature disentanglement as regularization loss functions that effectively utilize class semantic information within the feature space. These regularizers simulate the inclusion of an unlimited number of augmented target features into the augmentation graph while minimizing computational and memory demands. Our method shows superior adaptation performance in SFDA scenarios, including 2D image and 3D point cloud datasets and a highly imbalanced dataset.
Entropy is not Enough for Test-Time Adaptation: From the Perspective of Disentangled Factors
Mar 12, 2024Test-time adaptation (TTA) fine-tunes pre-trained deep neural networks for unseen test data. The primary challenge of TTA is limited access to the entire test dataset during online updates, causing error accumulation. To mitigate it, TTA methods have utilized the model output's entropy as a confidence metric that aims to determine which samples have a lower likelihood of causing error. Through experimental studies, however, we observed the unreliability of entropy as a confidence metric for TTA under biased scenarios and theoretically revealed that it stems from the neglect of the influence of latent disentangled factors of data on predictions. Building upon these findings, we introduce a novel TTA method named Destroy Your Object (DeYO), which leverages a newly proposed confidence metric named Pseudo-Label Probability Difference (PLPD). PLPD quantifies the influence of the shape of an object on prediction by measuring the difference between predictions before and after applying an object-destructive transformation. DeYO consists of sample selection and sample weighting, which employ entropy and PLPD concurrently. For robust adaptation, DeYO prioritizes samples that dominantly incorporate shape information when making predictions. Our extensive experiments demonstrate the consistent superiority of DeYO over baseline methods across various scenarios, including biased and wild. Project page is publicly available at https://whitesnowdrop.github.io/DeYO/.