 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodbye Drift: Anchored Tree Sampling for Long-Horizon Video-to-Video Generation
May 19, 2026Long-horizon video generation suffers from two intertwined issues. First, there is drift, where video quality degrades over time. Second, there are continuity issues which manifest as object permanence issues, or improperly rendering transient content (e.g., an object that appears in non-consecutive frames changing color/style). Recent work has focused on autoregressive distillation techniques that attack both problems simultaneously. We instead choose to focus on drift directly and introduce \textbf{Anchored Tree Sampling (ATS)}: a training-free inference-time scheduler that replaces left-to-right rollout with sparse-to-dense, anchor-bounded imputation organized as a tree. A root call produces sparse anchors over the full horizon, recursive refinement generates intermediate anchors, and final leaf spans are synthesized between neighboring anchors. This reduces the critical path from $K$ sequential rollout steps to $L+1$ tree-hierarchical steps and converts horizon-compounding drift into anchor-bounded drift. We focus on V2V generation in the \emph{static-camera} regime, where sparse anchors over the horizon are well approximated by the dense conditioning signal, and the base model can produce them without retraining. We evaluate ATS against two contemporary autoregressive baselines on Wan $2.1$ $+$ VACE, across five conditioning modalities (inpainting, outpainting, edge, pose, depth). We show that ATS outperforms both competitors in overall quality, as well as in drift prevention. We additionally demonstrate stable $\geq 40$-minute generation on LTX-$2.3$ across the same five modalities. We conclude by proposing a path forward to extend ATS to arbitrarily long T2V generation, as well as the dynamic-camera and multi-shot regimes.
PoDAR: Power-Disentangled Audio Representation for Generative Modeling
May 11, 2026The performance of audio latent diffusion models is primarily governed by generator expressivity and the modelability of the underlying latent space. While recent research has focused primarily on the former, as well as improving the reconstruction fidelity of audio codecs, we demonstrate that latent modelability can be significantly improved through explicit factor disentanglement. We present PoDAR (Power-Disentangled Audio Representation), a framework that utilizes a randomized power augmentation and latent consistency objective to decouple signal power from invariant semantic content. This factorization makes the latent space easier to model, which both accelerates the convergence of downstream generative models and improves final overall performance. When applied to a Stable Audio 1.0 VAE with an F5-TTS generator, PoDAR achieves about a $2\times$ acceleration in convergence to match baseline performance, while increasing final speaker similarity by 0.055 and UTMOS by 0.22 on the LibriSpeech-PC dataset. Furthermore, isolating power into dedicated channels enables the application of CFG exclusively to power-invariant content, effectively extending the stable guidance regime to higher scales.
Non-native English lexicon creation for bilingual speech synthesis
Jun 21, 2021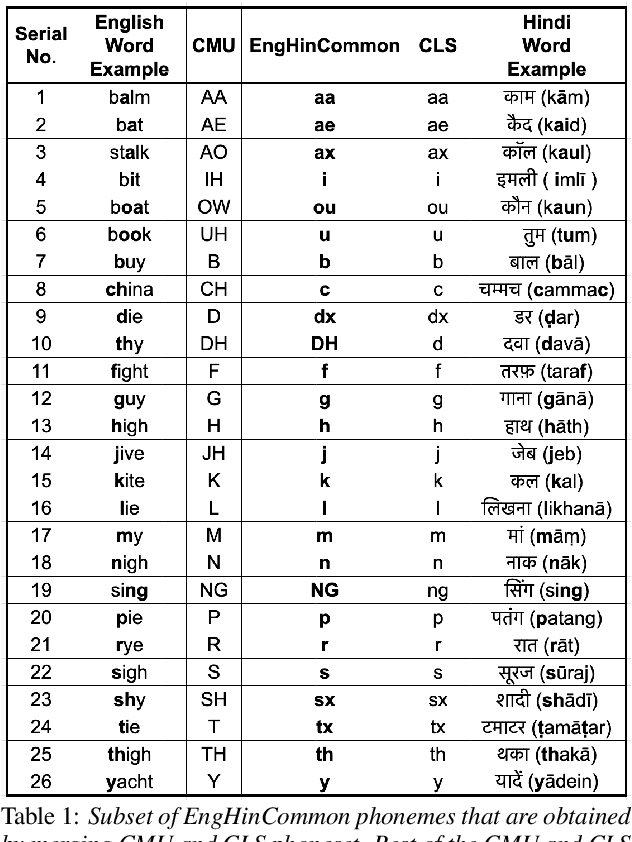
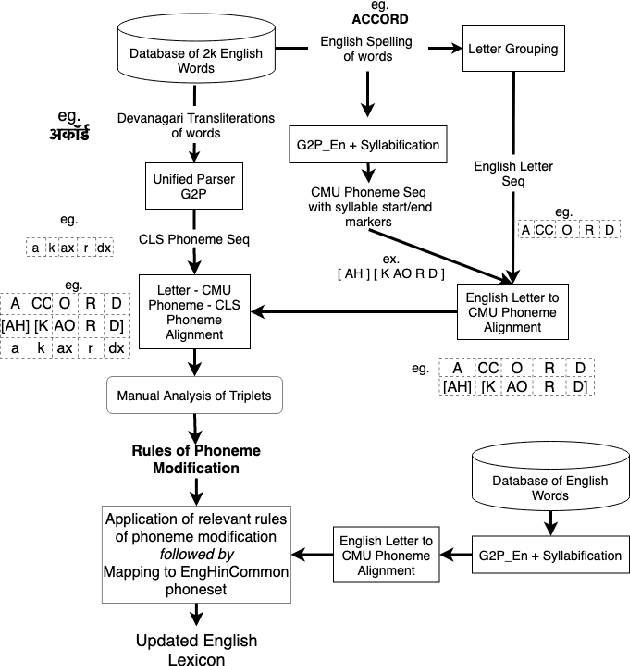
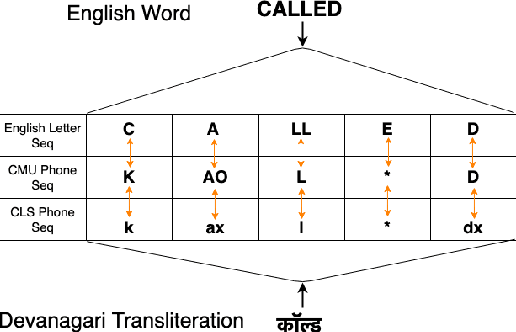
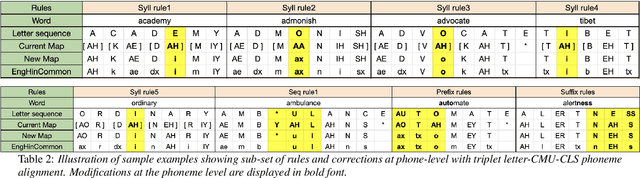
Bilingual English speakers speak English as one of their languages. Their English is of a non-native kind, and their conversations are of a code-mixed fashion. The intelligibility of a bilingual text-to-speech (TTS) system for such non-native English speakers depends on a lexicon that captures the phoneme sequence used by non-native speakers. However, due to the lack of non-native English lexicon, existing bilingual TTS systems employ native English lexicons that are widely available, in addition to their native language lexicon. Due to the inconsistency between the non-native English pronunciation in the audio and native English lexicon in the text, the intelligibility of synthesized speech in such TTS systems is significantly reduced. This paper is motivated by the knowledge that the native language of the speaker highly influences non-native English pronunciation. We propose a generic approach to obtain rules based on letter to phoneme alignment to map native English lexicon to their non-native version. The effectiveness of such mapping is studied by comparing bilingual (Indian English and Hindi) TTS systems trained with and without the proposed rules. The subjective evaluation shows that the bilingual TTS system trained with the proposed non-native English lexicon rules obtains a 6% absolute improvement in preference.