 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoodbye Drift: Anchored Tree Sampling for Long-Horizon Video-to-Video Generation
May 19, 2026Long-horizon video generation suffers from two intertwined issues. First, there is drift, where video quality degrades over time. Second, there are continuity issues which manifest as object permanence issues, or improperly rendering transient content (e.g., an object that appears in non-consecutive frames changing color/style). Recent work has focused on autoregressive distillation techniques that attack both problems simultaneously. We instead choose to focus on drift directly and introduce \textbf{Anchored Tree Sampling (ATS)}: a training-free inference-time scheduler that replaces left-to-right rollout with sparse-to-dense, anchor-bounded imputation organized as a tree. A root call produces sparse anchors over the full horizon, recursive refinement generates intermediate anchors, and final leaf spans are synthesized between neighboring anchors. This reduces the critical path from $K$ sequential rollout steps to $L+1$ tree-hierarchical steps and converts horizon-compounding drift into anchor-bounded drift. We focus on V2V generation in the \emph{static-camera} regime, where sparse anchors over the horizon are well approximated by the dense conditioning signal, and the base model can produce them without retraining. We evaluate ATS against two contemporary autoregressive baselines on Wan $2.1$ $+$ VACE, across five conditioning modalities (inpainting, outpainting, edge, pose, depth). We show that ATS outperforms both competitors in overall quality, as well as in drift prevention. We additionally demonstrate stable $\geq 40$-minute generation on LTX-$2.3$ across the same five modalities. We conclude by proposing a path forward to extend ATS to arbitrarily long T2V generation, as well as the dynamic-camera and multi-shot regimes.
PoDAR: Power-Disentangled Audio Representation for Generative Modeling
May 11, 2026The performance of audio latent diffusion models is primarily governed by generator expressivity and the modelability of the underlying latent space. While recent research has focused primarily on the former, as well as improving the reconstruction fidelity of audio codecs, we demonstrate that latent modelability can be significantly improved through explicit factor disentanglement. We present PoDAR (Power-Disentangled Audio Representation), a framework that utilizes a randomized power augmentation and latent consistency objective to decouple signal power from invariant semantic content. This factorization makes the latent space easier to model, which both accelerates the convergence of downstream generative models and improves final overall performance. When applied to a Stable Audio 1.0 VAE with an F5-TTS generator, PoDAR achieves about a $2\times$ acceleration in convergence to match baseline performance, while increasing final speaker similarity by 0.055 and UTMOS by 0.22 on the LibriSpeech-PC dataset. Furthermore, isolating power into dedicated channels enables the application of CFG exclusively to power-invariant content, effectively extending the stable guidance regime to higher scales.
Deep Learning for Assessment of Oral Reading Fluency
Jun 01, 2024Reading fluency assessment is a critical component of literacy programmes, serving to guide and monitor early education interventions. Given the resource intensive nature of the exercise when conducted by teachers, the development of automatic tools that can operate on audio recordings of oral reading is attractive as an objective and highly scalable solution. Multiple complex aspects such as accuracy, rate and expressiveness underlie human judgements of reading fluency. In this work, we investigate end-to-end modeling on a training dataset of children's audio recordings of story texts labeled by human experts. The pre-trained wav2vec2.0 model is adopted due its potential to alleviate the challenges from the limited amount of labeled data. We report the performance of a number of system variations on the relevant measures, and also probe the learned embeddings for lexical and acoustic-prosodic features known to be important to the perception of reading fluency.
Deep Learning For Prominence Detection In Children's Read Speech
Oct 27, 2021
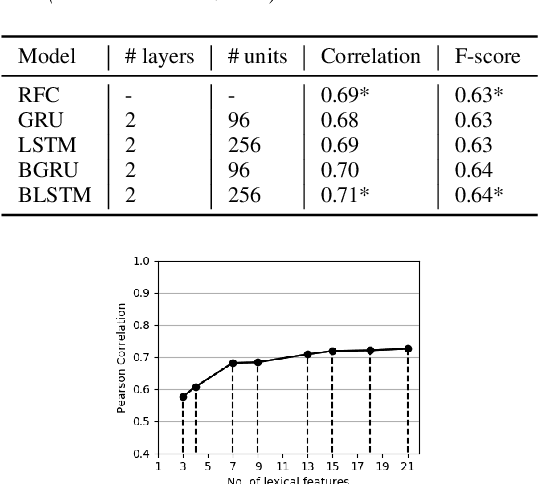
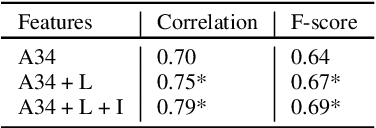
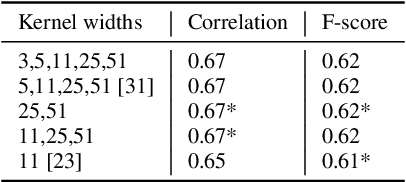
The detection of perceived prominence in speech has attracted approaches ranging from the design of linguistic knowledge-based acoustic features to the automatic feature learning from suprasegmental attributes such as pitch and intensity contours. We present here, in contrast, a system that operates directly on segmented speech waveforms to learn features relevant to prominent word detection for children's oral fluency assessment. The chosen CRNN (convolutional recurrent neural network) framework, incorporating both word-level features and sequence information, is found to benefit from the perceptually motivated SincNet filters as the first convolutional layer. We further explore the benefits of the linguistic association between the prosodic events of phrase boundary and prominence with different multi-task architectures. Matching the previously reported performance on the same dataset of a random forest ensemble predictor trained on carefully chosen hand-crafted acoustic features, we evaluate further the possibly complementary information from hand-crafted acoustic and pre-trained lexical features.