 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Estimation of Isotropic Covariance Function
Apr 24, 2026A nonparametric model using a sequence of Bernstein polynomials is constructed to approximate arbitrary isotropic covariance functions valid in $\mathbb{R}^\infty$ and related approximation properties are investigated using the popular $L_{\infty}$ norm and $L_2$ norms. A computationally efficient sieve maximum likelihood (sML) estimation is then developed to nonparametrically estimate the unknown isotropic covaraince function valid in $\mathbb{R}^\infty$. Consistency of the proposed sieve ML estimator is established under increasing domain regime. The proposed methodology is compared numerically with couple of existing nonparametric as well as with commonly used parametric methods. Numerical results based on simulated data show that our approach outperforms the parametric methods in reducing bias due to model misspecification and also the nonparametric methods in terms of having significantly lower values of expected $L_{\infty}$ and $L_2$ norms. Application to precipitation data is illustrated to showcase a real case study. Additional technical details and numerical illustrations are also made available.
* 39 pages, 7 figures. Published in Journal of Nonparametric Statistics (2023)
EMFlow: Data Imputation in Latent Space via EM and Deep Flow Models
Jun 09, 2021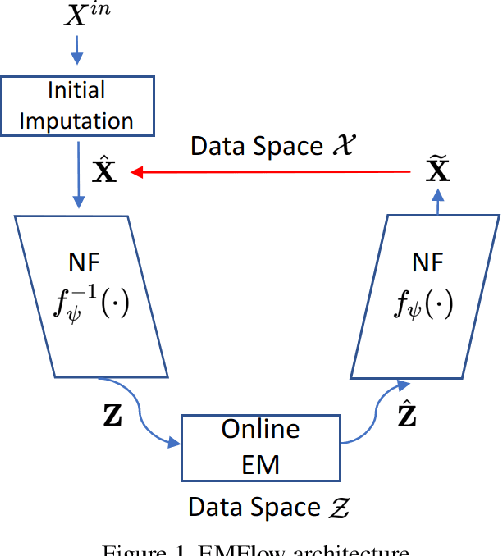
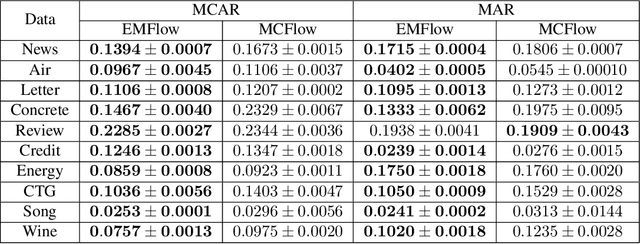
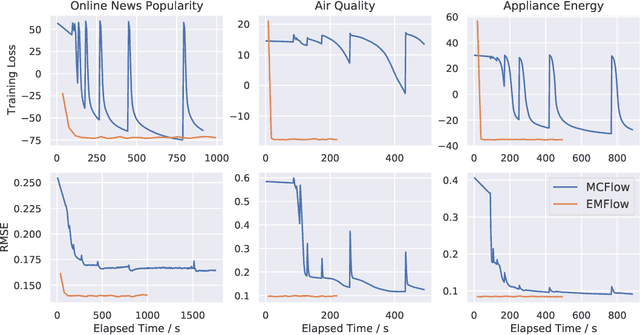

High dimensional incomplete data can be found in a wide range of systems. Due to the fact that most of the data mining techniques and machine learning algorithms require complete observations, data imputation is vital for down-stream analysis. In this work, we introduce an imputation approach, called EMFlow, that performs imputation in an latent space via an online version of Expectation-Maximization (EM) algorithm and connects the latent space and the data space via the normalizing flow (NF). The inference of EMFlow is iterative, involving updating the parameters of online EM and NF alternatively. Extensive experimental results on multivariate and image datasets show that the proposed EMFlow has superior performance to competing methods in terms of both imputation quality and convergence speed.
A Non-Iterative Quantile Change Detection Method in Mixture Model with Heavy-Tailed Components
Jun 19, 2020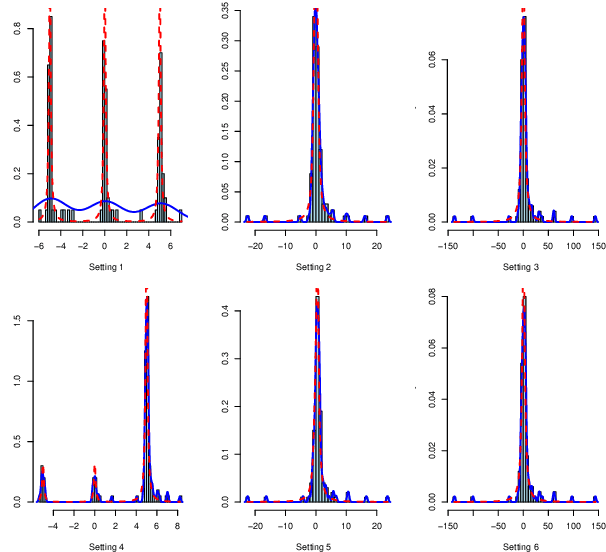
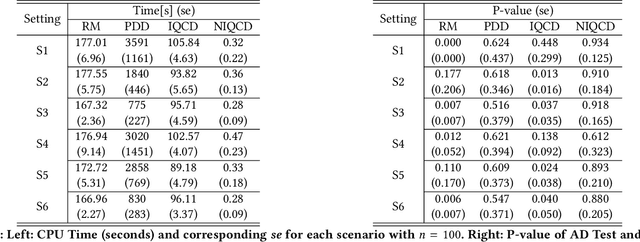
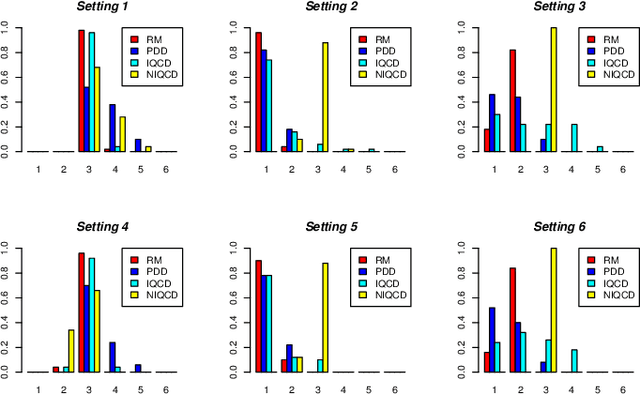
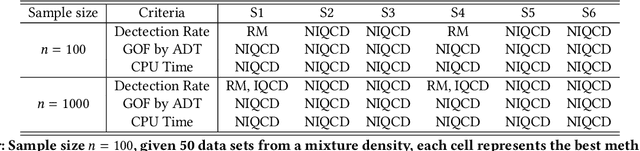
Estimating parameters of mixture model has wide applications ranging from classification problems to estimating of complex distributions. Most of the current literature on estimating the parameters of the mixture densities are based on iterative Expectation Maximization (EM) type algorithms which require the use of either taking expectations over the latent label variables or generating samples from the conditional distribution of such latent labels using the Bayes rule. Moreover, when the number of components is unknown, the problem becomes computationally more demanding due to well-known label switching issues \cite{richardson1997bayesian}. In this paper, we propose a robust and quick approach based on change-point methods to determine the number of mixture components that works for almost any location-scale families even when the components are heavy tailed (e.g., Cauchy). We present several numerical illustrations by comparing our method with some of popular methods available in the literature using simulated data and real case studies. The proposed method is shown be as much as 500 times faster than some of the competing methods and are also shown to be more accurate in estimating the mixture distributions by goodness-of-fit tests.