 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenTag: Open Attribute Value Extraction from Product Profiles [Deep Learning, Active Learning, Named Entity Recognition]
Oct 06, 2018![Figure 1 for OpenTag: Open Attribute Value Extraction from Product Profiles [Deep Learning, Active Learning, Named Entity Recognition]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fe52efd2dcc4f3148ab4ca604c51f90684558f1fc%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for OpenTag: Open Attribute Value Extraction from Product Profiles [Deep Learning, Active Learning, Named Entity Recognition]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fe52efd2dcc4f3148ab4ca604c51f90684558f1fc%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for OpenTag: Open Attribute Value Extraction from Product Profiles [Deep Learning, Active Learning, Named Entity Recognition]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fe52efd2dcc4f3148ab4ca604c51f90684558f1fc%2F5-Figure2-1.png&w=640&q=75)
![Figure 4 for OpenTag: Open Attribute Value Extraction from Product Profiles [Deep Learning, Active Learning, Named Entity Recognition]](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fe52efd2dcc4f3148ab4ca604c51f90684558f1fc%2F6-Table2-1.png&w=640&q=75)
Extraction of missing attribute values is to find values describing an attribute of interest from a free text input. Most past related work on extraction of missing attribute values work with a closed world assumption with the possible set of values known beforehand, or use dictionaries of values and hand-crafted features. How can we discover new attribute values that we have never seen before? Can we do this with limited human annotation or supervision? We study this problem in the context of product catalogs that often have missing values for many attributes of interest. In this work, we leverage product profile information such as titles and descriptions to discover missing values of product attributes. We develop a novel deep tagging model OpenTag for this extraction problem with the following contributions: (1) we formalize the problem as a sequence tagging task, and propose a joint model exploiting recurrent neural networks (specifically, bidirectional LSTM) to capture context and semantics, and Conditional Random Fields (CRF) to enforce tagging consistency, (2) we develop a novel attention mechanism to provide interpretable explanation for our model's decisions, (3) we propose a novel sampling strategy exploring active learning to reduce the burden of human annotation. OpenTag does not use any dictionary or hand-crafted features as in prior works. Extensive experiments in real-life datasets in different domains show that OpenTag with our active learning strategy discovers new attribute values from as few as 150 annotated samples (reduction in 3.3x amount of annotation effort) with a high F-score of 83%, outperforming state-of-the-art models.
DeClarE: Debunking Fake News and False Claims using Evidence-Aware Deep Learning
Sep 17, 2018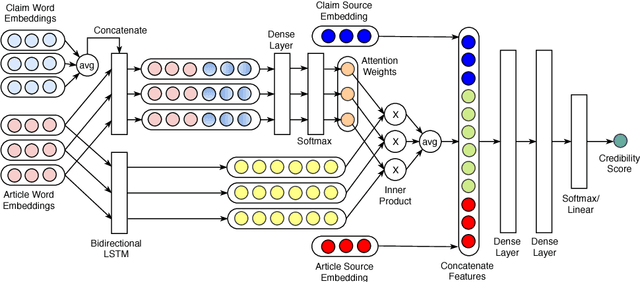
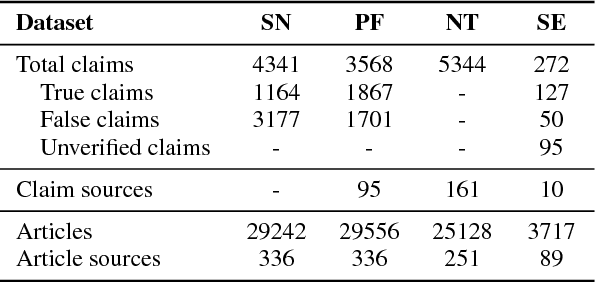

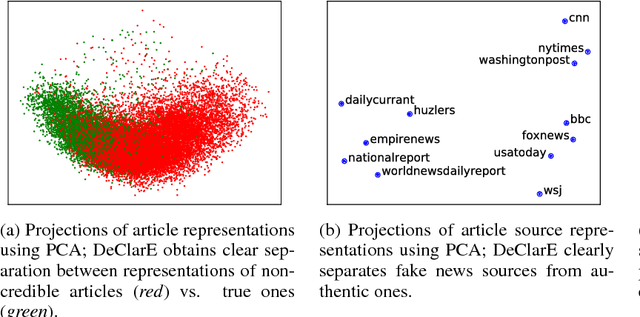
Misinformation such as fake news is one of the big challenges of our society. Research on automated fact-checking has proposed methods based on supervised learning, but these approaches do not consider external evidence apart from labeled training instances. Recent approaches counter this deficit by considering external sources related to a claim. However, these methods require substantial feature modeling and rich lexicons. This paper overcomes these limitations of prior work with an end-to-end model for evidence-aware credibility assessment of arbitrary textual claims, without any human intervention. It presents a neural network model that judiciously aggregates signals from external evidence articles, the language of these articles and the trustworthiness of their sources. It also derives informative features for generating user-comprehensible explanations that makes the neural network predictions transparent to the end-user. Experiments with four datasets and ablation studies show the strength of our method.
Item Recommendation with Continuous Experience Evolution of Users using Brownian Motion
Aug 09, 2017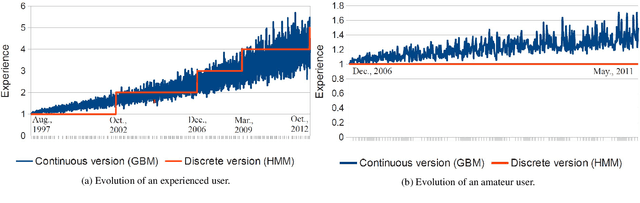
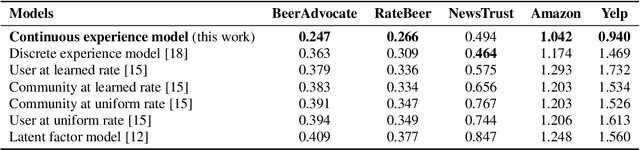
Online review communities are dynamic as users join and leave, adopt new vocabulary, and adapt to evolving trends. Recent work has shown that recommender systems benefit from explicit consideration of user experience. However, prior work assumes a fixed number of discrete experience levels, whereas in reality users gain experience and mature continuously over time. This paper presents a new model that captures the continuous evolution of user experience, and the resulting language model in reviews and other posts. Our model is unsupervised and combines principles of Geometric Brownian Motion, Brownian Motion, and Latent Dirichlet Allocation to trace a smooth temporal progression of user experience and language model respectively. We develop practical algorithms for estimating the model parameters from data and for inference with our model (e.g., to recommend items). Extensive experiments with five real-world datasets show that our model not only fits data better than discrete-model baselines, but also outperforms state-of-the-art methods for predicting item ratings.
Probabilistic Graphical Models for Credibility Analysis in Evolving Online Communities
Jul 26, 2017One of the major hurdles preventing the full exploitation of information from online communities is the widespread concern regarding the quality and credibility of user-contributed content. Prior works in this domain operate on a static snapshot of the community, making strong assumptions about the structure of the data (e.g., relational tables), or consider only shallow features for text classification. To address the above limitations, we propose probabilistic graphical models that can leverage the joint interplay between multiple factors in online communities --- like user interactions, community dynamics, and textual content --- to automatically assess the credibility of user-contributed online content, and the expertise of users and their evolution with user-interpretable explanation. To this end, we devise new models based on Conditional Random Fields for different settings like incorporating partial expert knowledge for semi-supervised learning, and handling discrete labels as well as numeric ratings for fine-grained analysis. This enables applications such as extracting reliable side-effects of drugs from user-contributed posts in healthforums, and identifying credible content in news communities. Online communities are dynamic, as users join and leave, adapt to evolving trends, and mature over time. To capture this dynamics, we propose generative models based on Hidden Markov Model, Latent Dirichlet Allocation, and Brownian Motion to trace the continuous evolution of user expertise and their language model over time. This allows us to identify expert users and credible content jointly over time, improving state-of-the-art recommender systems by explicitly considering the maturity of users. This also enables applications such as identifying helpful product reviews, and detecting fake and anomalous reviews with limited information.
People on Media: Jointly Identifying Credible News and Trustworthy Citizen Journalists in Online Communities
May 09, 2017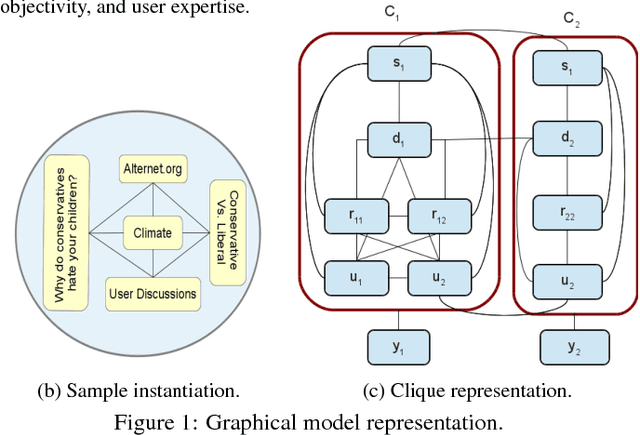


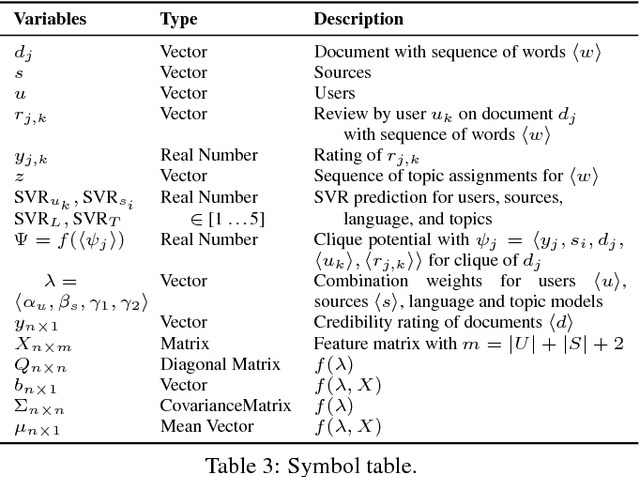
Media seems to have become more partisan, often providing a biased coverage of news catering to the interest of specific groups. It is therefore essential to identify credible information content that provides an objective narrative of an event. News communities such as digg, reddit, or newstrust offer recommendations, reviews, quality ratings, and further insights on journalistic works. However, there is a complex interaction between different factors in such online communities: fairness and style of reporting, language clarity and objectivity, topical perspectives (like political viewpoint), expertise and bias of community members, and more. This paper presents a model to systematically analyze the different interactions in a news community between users, news, and sources. We develop a probabilistic graphical model that leverages this joint interaction to identify 1) highly credible news articles, 2) trustworthy news sources, and 3) expert users who perform the role of "citizen journalists" in the community. Our method extends CRF models to incorporate real-valued ratings, as some communities have very fine-grained scales that cannot be easily discretized without losing information. To the best of our knowledge, this paper is the first full-fledged analysis of credibility, trust, and expertise in news communities.
Credible Review Detection with Limited Information using Consistency Analysis
May 07, 2017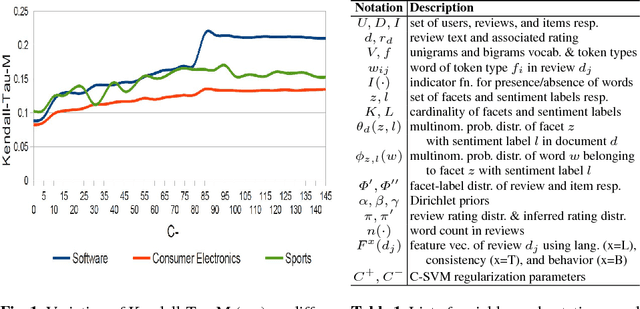

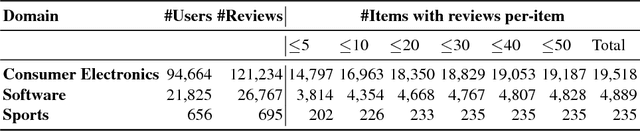
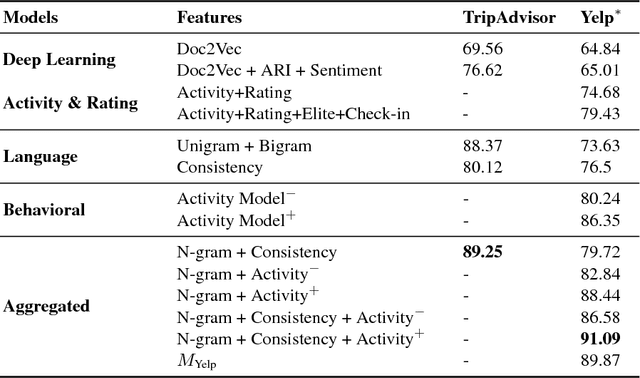
Online reviews provide viewpoints on the strengths and shortcomings of products/services, influencing potential customers' purchasing decisions. However, the proliferation of non-credible reviews -- either fake (promoting/ demoting an item), incompetent (involving irrelevant aspects), or biased -- entails the problem of identifying credible reviews. Prior works involve classifiers harnessing rich information about items/users -- which might not be readily available in several domains -- that provide only limited interpretability as to why a review is deemed non-credible. This paper presents a novel approach to address the above issues. We utilize latent topic models leveraging review texts, item ratings, and timestamps to derive consistency features without relying on item/user histories, unavailable for "long-tail" items/users. We develop models, for computing review credibility scores to provide interpretable evidence for non-credible reviews, that are also transferable to other domains -- addressing the scarcity of labeled data. Experiments on real-world datasets demonstrate improvements over state-of-the-art baselines.
People on Drugs: Credibility of User Statements in Health Communities
May 06, 2017
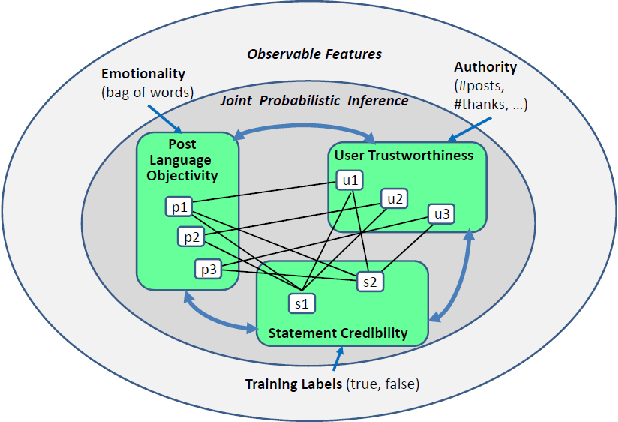

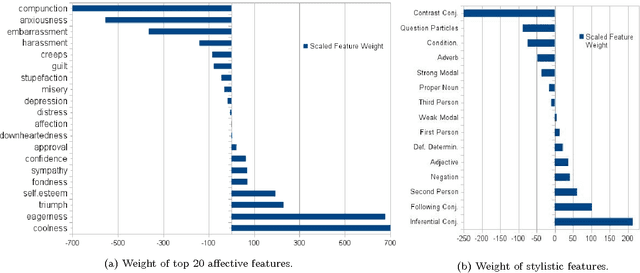
Online health communities are a valuable source of information for patients and physicians. However, such user-generated resources are often plagued by inaccuracies and misinformation. In this work we propose a method for automatically establishing the credibility of user-generated medical statements and the trustworthiness of their authors by exploiting linguistic cues and distant supervision from expert sources. To this end we introduce a probabilistic graphical model that jointly learns user trustworthiness, statement credibility, and language objectivity. We apply this methodology to the task of extracting rare or unknown side-effects of medical drugs --- this being one of the problems where large scale non-expert data has the potential to complement expert medical knowledge. We show that our method can reliably extract side-effects and filter out false statements, while identifying trustworthy users that are likely to contribute valuable medical information.
Item Recommendation with Evolving User Preferences and Experience
May 06, 2017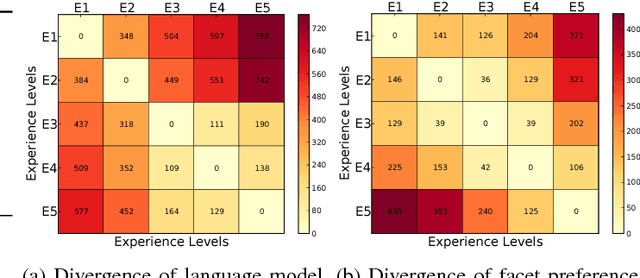
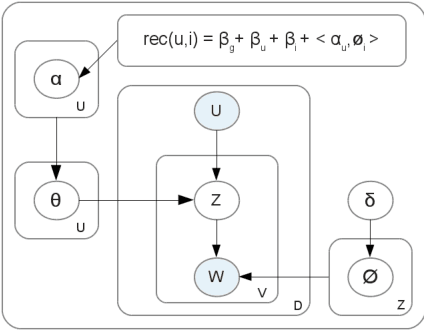
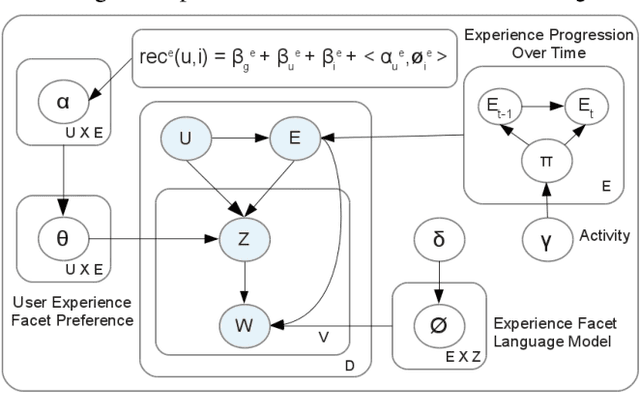
Current recommender systems exploit user and item similarities by collaborative filtering. Some advanced methods also consider the temporal evolution of item ratings as a global background process. However, all prior methods disregard the individual evolution of a user's experience level and how this is expressed in the user's writing in a review community. In this paper, we model the joint evolution of user experience, interest in specific item facets, writing style, and rating behavior. This way we can generate individual recommendations that take into account the user's maturity level (e.g., recommending art movies rather than blockbusters for a cinematography expert). As only item ratings and review texts are observables, we capture the user's experience and interests in a latent model learned from her reviews, vocabulary and writing style. We develop a generative HMM-LDA model to trace user evolution, where the Hidden Markov Model (HMM) traces her latent experience progressing over time -- with solely user reviews and ratings as observables over time. The facets of a user's interest are drawn from a Latent Dirichlet Allocation (LDA) model derived from her reviews, as a function of her (again latent) experience level. In experiments with five real-world datasets, we show that our model improves the rating prediction over state-of-the-art baselines, by a substantial margin. We also show, in a use-case study, that our model performs well in the assessment of user experience levels.
Exploring Latent Semantic Factors to Find Useful Product Reviews
May 06, 2017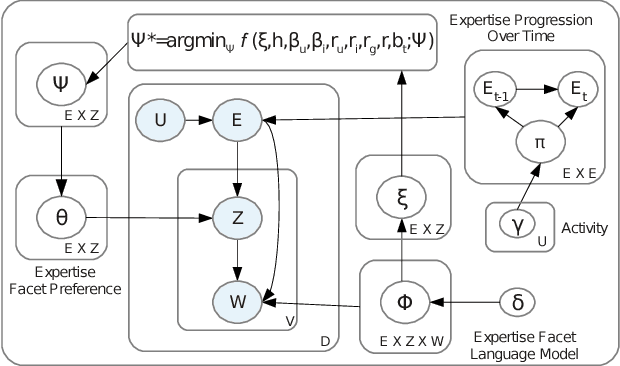
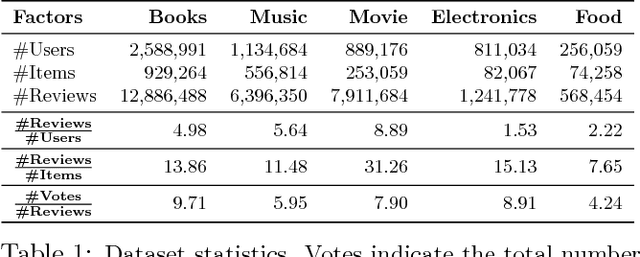

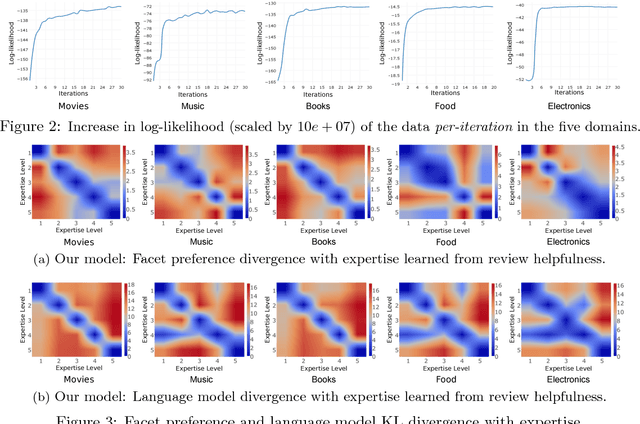
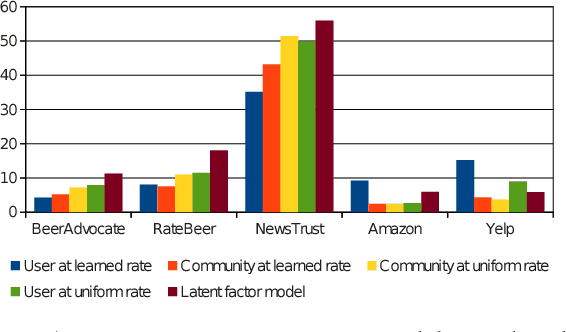
Online reviews provided by consumers are a valuable asset for e-Commerce platforms, influencing potential consumers in making purchasing decisions. However, these reviews are of varying quality, with the useful ones buried deep within a heap of non-informative reviews. In this work, we attempt to automatically identify review quality in terms of its helpfulness to the end consumers. In contrast to previous works in this domain exploiting a variety of syntactic and community-level features, we delve deep into the semantics of reviews as to what makes them useful, providing interpretable explanation for the same. We identify a set of consistency and semantic factors, all from the text, ratings, and timestamps of user-generated reviews, making our approach generalizable across all communities and domains. We explore review semantics in terms of several latent factors like the expertise of its author, his judgment about the fine-grained facets of the underlying product, and his writing style. These are cast into a Hidden Markov Model -- Latent Dirichlet Allocation (HMM-LDA) based model to jointly infer: (i) reviewer expertise, (ii) item facets, and (iii) review helpfulness. Large-scale experiments on five real-world datasets from Amazon show significant improvement over state-of-the-art baselines in predicting and ranking useful reviews.
Sentiment Analysis : A Literature Survey
Apr 16, 2013
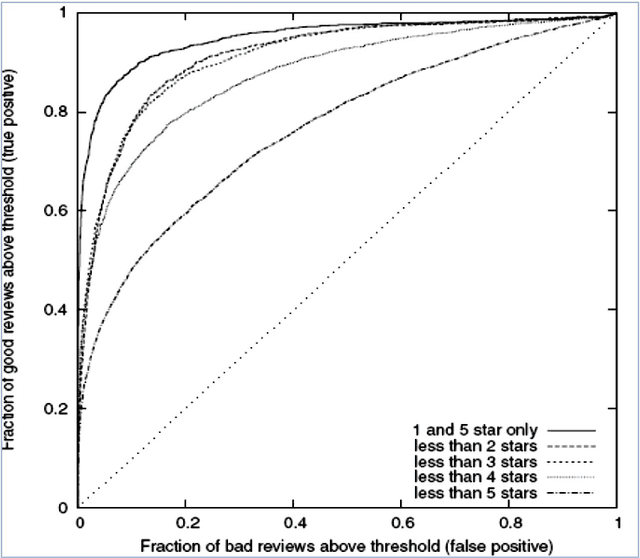
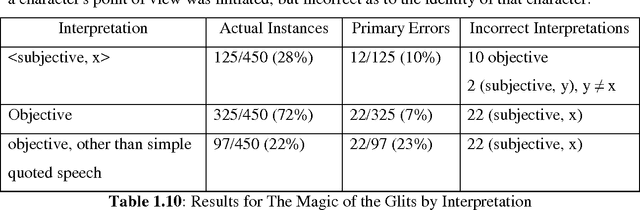
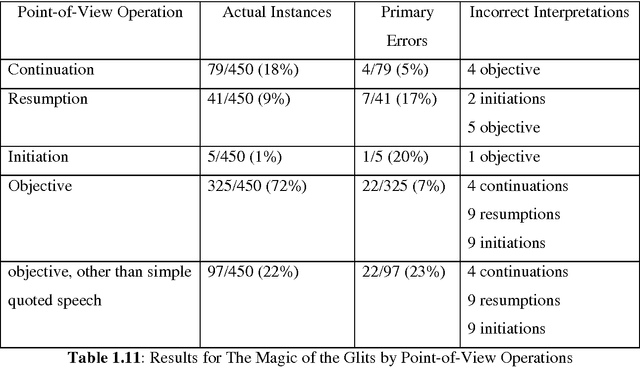
Our day-to-day life has always been influenced by what people think. Ideas and opinions of others have always affected our own opinions. The explosion of Web 2.0 has led to increased activity in Podcasting, Blogging, Tagging, Contributing to RSS, Social Bookmarking, and Social Networking. As a result there has been an eruption of interest in people to mine these vast resources of data for opinions. Sentiment Analysis or Opinion Mining is the computational treatment of opinions, sentiments and subjectivity of text. In this report, we take a look at the various challenges and applications of Sentiment Analysis. We will discuss in details various approaches to perform a computational treatment of sentiments and opinions. Various supervised or data-driven techniques to SA like Na\"ive Byes, Maximum Entropy, SVM, and Voted Perceptrons will be discussed and their strengths and drawbacks will be touched upon. We will also see a new dimension of analyzing sentiments by Cognitive Psychology mainly through the work of Janyce Wiebe, where we will see ways to detect subjectivity, perspective in narrative and understanding the discourse structure. We will also study some specific topics in Sentiment Analysis and the contemporary works in those areas.