 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Misleading Assistants in Conversation
Jul 16, 2024Large Language Models (LLMs) are able to provide assistance on a wide range of information-seeking tasks. However, model outputs may be misleading, whether unintentionally or in cases of intentional deception. We investigate the ability of LLMs to be deceptive in the context of providing assistance on a reading comprehension task, using LLMs as proxies for human users. We compare outcomes of (1) when the model is prompted to provide truthful assistance, (2) when it is prompted to be subtly misleading, and (3) when it is prompted to argue for an incorrect answer. Our experiments show that GPT-4 can effectively mislead both GPT-3.5-Turbo and GPT-4, with deceptive assistants resulting in up to a 23% drop in accuracy on the task compared to when a truthful assistant is used. We also find that providing the user model with additional context from the passage partially mitigates the influence of the deceptive model. This work highlights the ability of LLMs to produce misleading information and the effects this may have in real-world situations.
A Holistic Approach to Undesired Content Detection in the Real World
Aug 05, 2022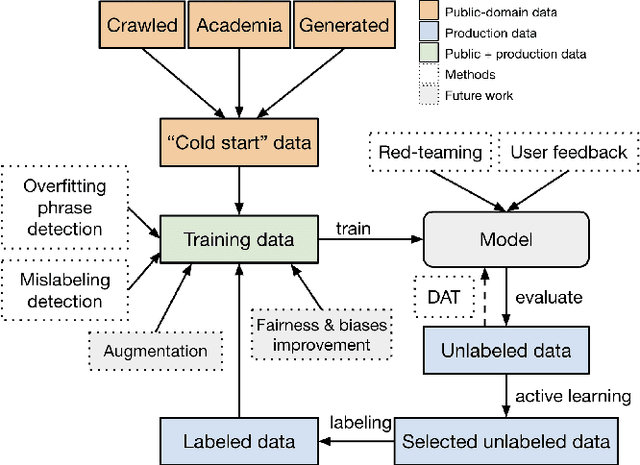


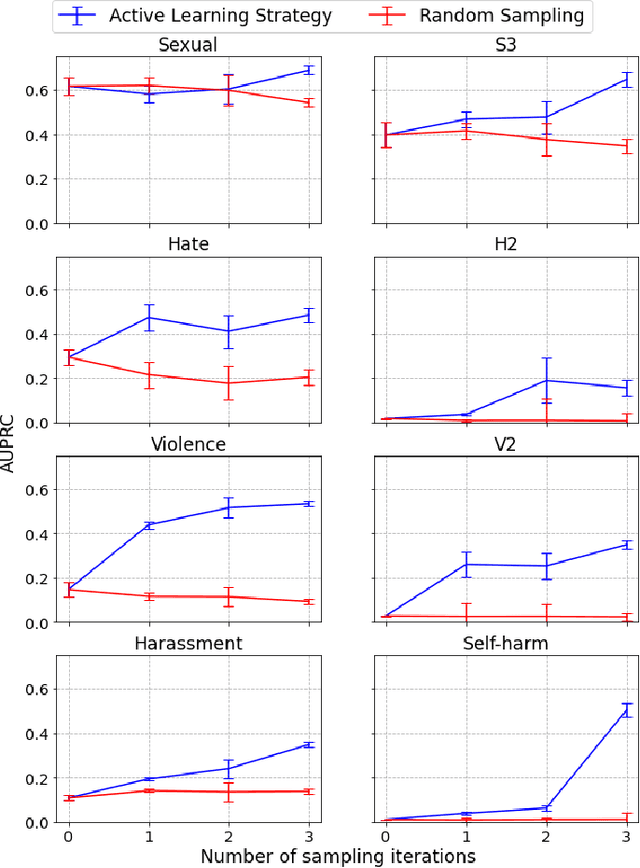
We present a holistic approach to building a robust and useful natural language classification system for real-world content moderation. The success of such a system relies on a chain of carefully designed and executed steps, including the design of content taxonomies and labeling instructions, data quality control, an active learning pipeline to capture rare events, and a variety of methods to make the model robust and to avoid overfitting. Our moderation system is trained to detect a broad set of categories of undesired content, including sexual content, hateful content, violence, self-harm, and harassment. This approach generalizes to a wide range of different content taxonomies and can be used to create high-quality content classifiers that outperform off-the-shelf models.
What are you optimizing for? Aligning Recommender Systems with Human Values
Jul 22, 2021We describe cases where real recommender systems were modified in the service of various human values such as diversity, fairness, well-being, time well spent, and factual accuracy. From this we identify the current practice of values engineering: the creation of classifiers from human-created data with value-based labels. This has worked in practice for a variety of issues, but problems are addressed one at a time, and users and other stakeholders have seldom been involved. Instead, we look to AI alignment work for approaches that could learn complex values directly from stakeholders, and identify four major directions: useful measures of alignment, participatory design and operation, interactive value learning, and informed deliberative judgments.