 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNAREOR: The Narrative Reordering Problem
Apr 14, 2021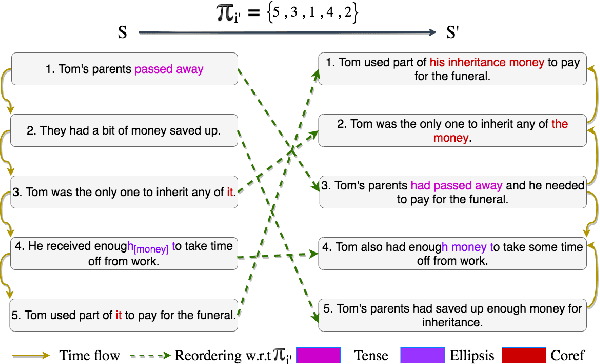

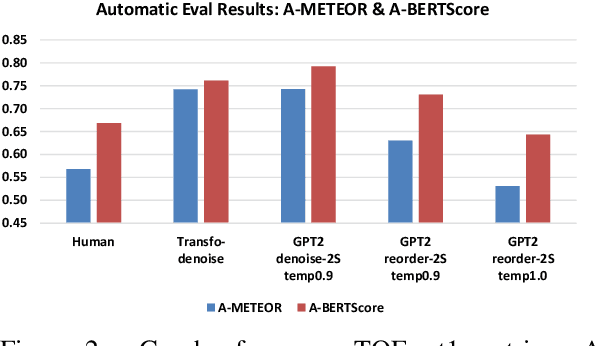
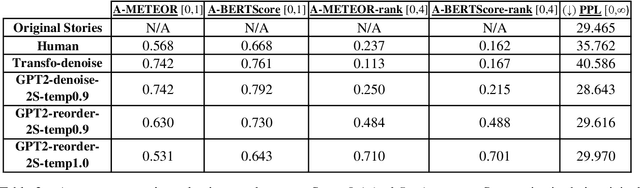
We propose the task of Narrative Reordering(NAREOR) which involves rewriting a given story in a different narrative order while preserving its plot, semantic, and temporal aspects. We present a dataset, NAREORC, with over 1000 human rewritings of stories within ROCStories in non-linear orders, and conduct a detailed analysis of it. Further, we propose novel initial task-specific training methods and evaluation metrics. We perform experiments on NAREORC using GPT-2 and Transformer models and conduct an extensive human evaluation. We demonstrate that NAREOR is a challenging task with potential for further exploration.
GenAug: Data Augmentation for Finetuning Text Generators
Oct 10, 2020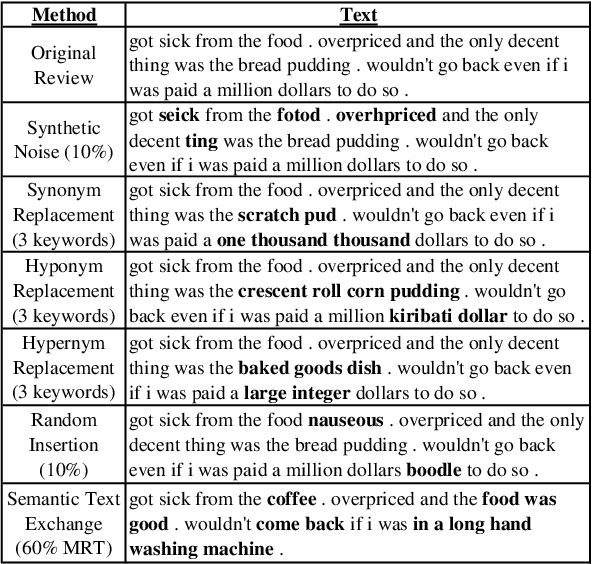
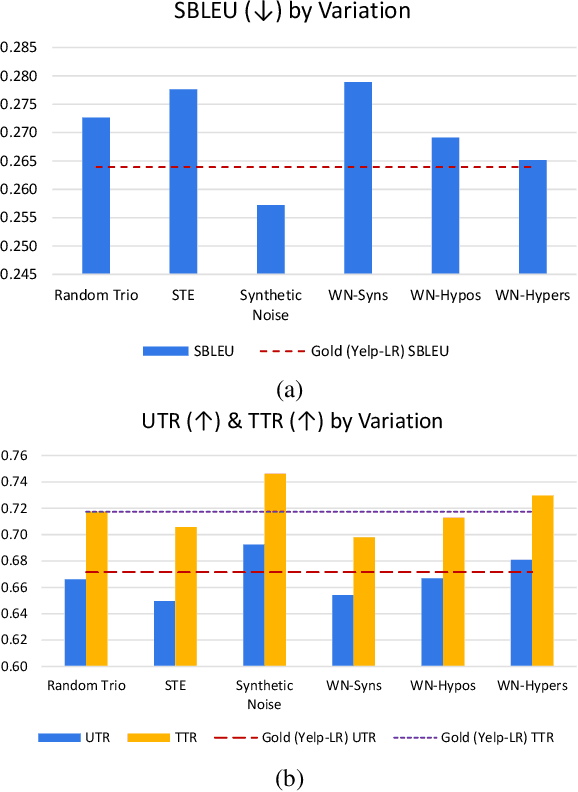
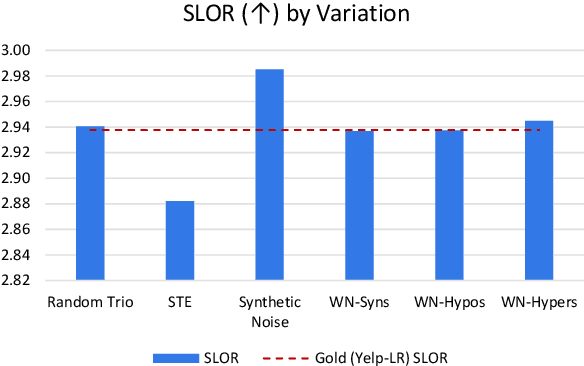
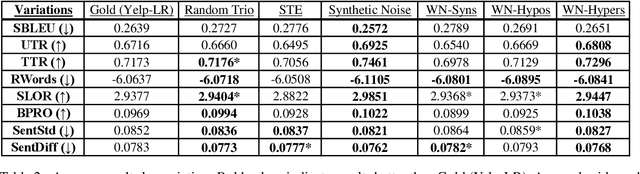
In this paper, we investigate data augmentation for text generation, which we call GenAug. Text generation and language modeling are important tasks within natural language processing, and are especially challenging for low-data regimes. We propose and evaluate various augmentation methods, including some that incorporate external knowledge, for finetuning GPT-2 on a subset of Yelp Reviews. We also examine the relationship between the amount of augmentation and the quality of the generated text. We utilize several metrics that evaluate important aspects of the generated text including its diversity and fluency. Our experiments demonstrate that insertion of character-level synthetic noise and keyword replacement with hypernyms are effective augmentation methods, and that the quality of generations improves to a peak at approximately three times the amount of original data.
ALOHA: Artificial Learning of Human Attributes for Dialogue Agents
Nov 21, 2019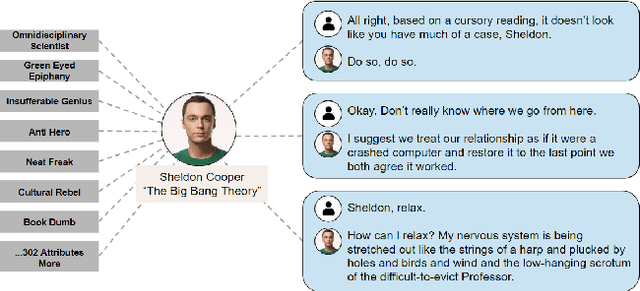

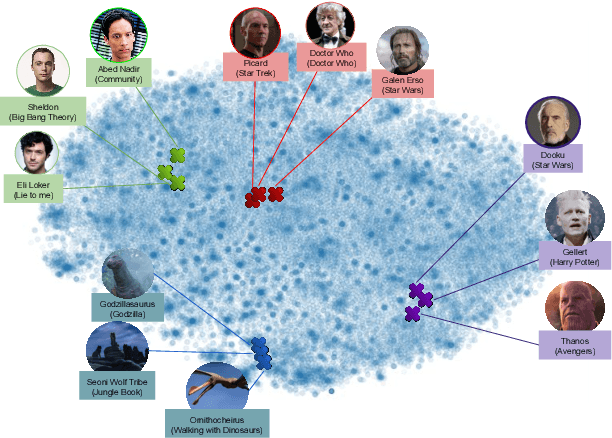
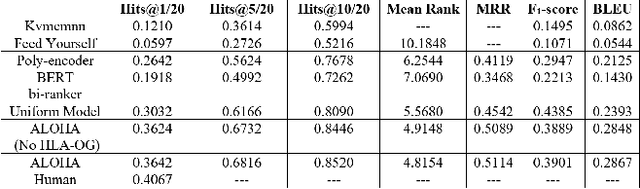
For conversational AI and virtual assistants to communicate with humans in a realistic way, they must exhibit human characteristics such as expression of emotion and personality. Current attempts toward constructing human-like dialogue agents have presented significant difficulties. We propose Human Level Attributes (HLAs) based on tropes as the basis of a method for learning dialogue agents that can imitate the personalities of fictional characters. Tropes are characteristics of fictional personalities that are observed recurrently and determined by viewers' impressions. By combining detailed HLA data with dialogue data for specific characters, we present a dataset, HLA-Chat, that models character profiles and gives dialogue agents the ability to learn characters' language styles through their HLAs. We then introduce a three-component system, ALOHA (which stands for Artificial Learning of Human Attributes), that combines character space mapping, character community detection, and language style retrieval to build a character (or personality) specific language model. Our preliminary experiments demonstrate that two variations of ALOHA, combined with our proposed dataset, can outperform baseline models at identifying the correct dialogue responses of chosen target characters, and are stable regardless of the character's identity, the genre of the show, and the context of the dialogue.
Keep Calm and Switch On! Preserving Sentiment and Fluency in Semantic Text Exchange
Aug 30, 2019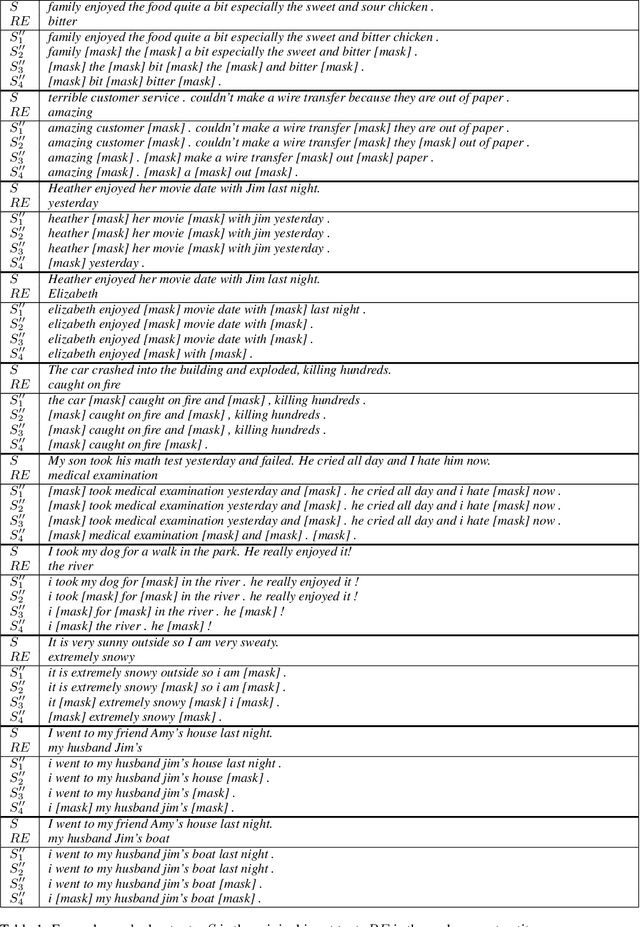
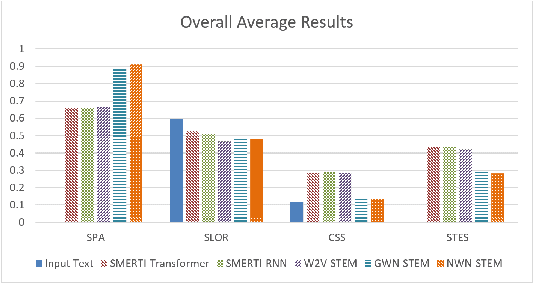
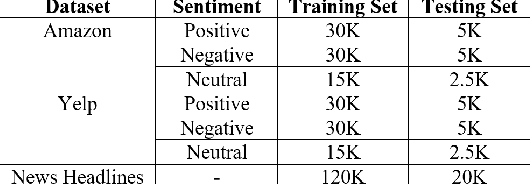
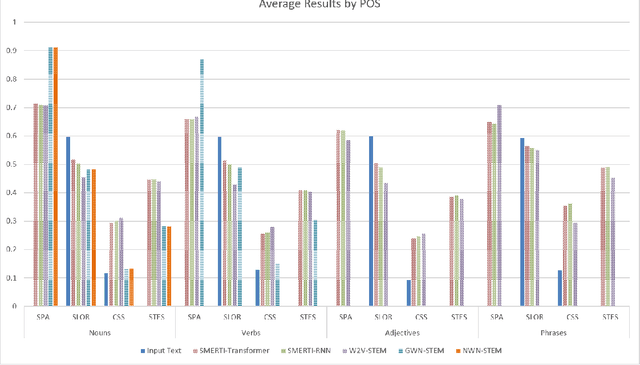
In this paper, we present a novel method for measurably adjusting the semantics of text while preserving its sentiment and fluency, a task we call semantic text exchange. This is useful for text data augmentation and the semantic correction of text generated by chatbots and virtual assistants. We introduce a pipeline called SMERTI that combines entity replacement, similarity masking, and text infilling. We measure our pipeline's success by its Semantic Text Exchange Score (STES): the ability to preserve the original text's sentiment and fluency while adjusting semantic content. We propose to use masking (replacement) rate threshold as an adjustable parameter to control the amount of semantic change in the text. Our experiments demonstrate that SMERTI can outperform baseline models on Yelp reviews, Amazon reviews, and news headlines.