 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Recurrent Neural Networks for End-to-end Speech Recognition
Jun 20, 2016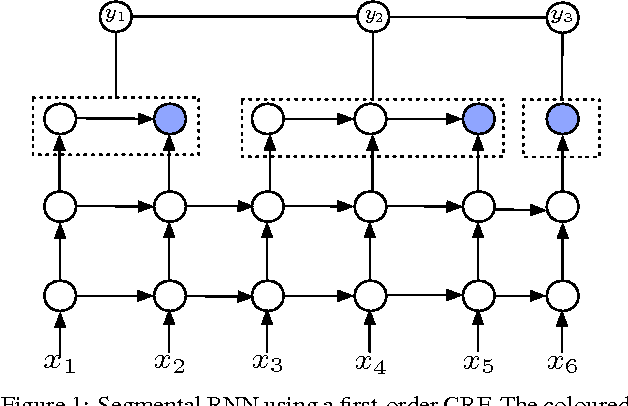

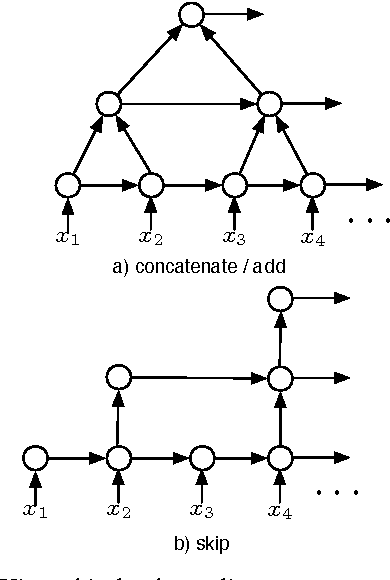
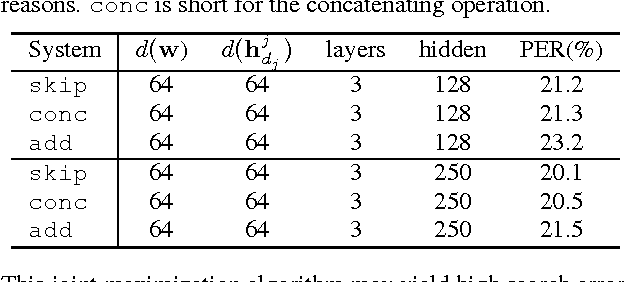
We study the segmental recurrent neural network for end-to-end acoustic modelling. This model connects the segmental conditional random field (CRF) with a recurrent neural network (RNN) used for feature extraction. Compared to most previous CRF-based acoustic models, it does not rely on an external system to provide features or segmentation boundaries. Instead, this model marginalises out all the possible segmentations, and features are extracted from the RNN trained together with the segmental CRF. In essence, this model is self-contained and can be trained end-to-end. In this paper, we discuss practical training and decoding issues as well as the method to speed up the training in the context of speech recognition. We performed experiments on the TIMIT dataset. We achieved 17.3 phone error rate (PER) from the first-pass decoding --- the best reported result using CRFs, despite the fact that we only used a zeroth-order CRF and without using any language model.
Character-Level Neural Translation for Multilingual Media Monitoring in the SUMMA Project
Apr 05, 2016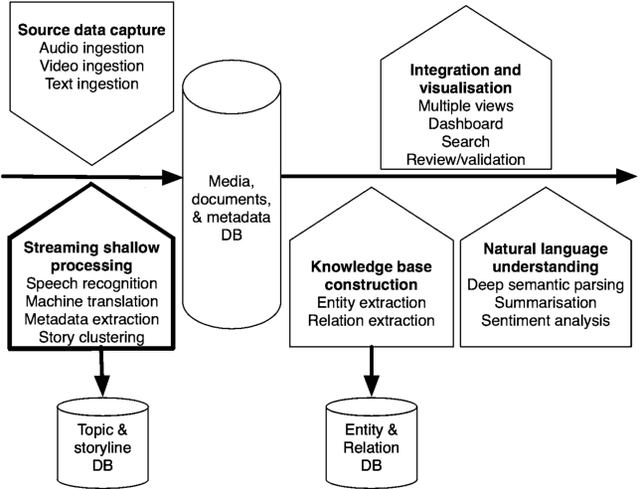


The paper steps outside the comfort-zone of the traditional NLP tasks like automatic speech recognition (ASR) and machine translation (MT) to addresses two novel problems arising in the automated multilingual news monitoring: segmentation of the TV and radio program ASR transcripts into individual stories, and clustering of the individual stories coming from various sources and languages into storylines. Storyline clustering of stories covering the same events is an essential task for inquisitorial media monitoring. We address these two problems jointly by engaging the low-dimensional semantic representation capabilities of the sequence to sequence neural translation models. To enable joint multi-task learning for multilingual neural translation of morphologically rich languages we replace the attention mechanism with the sliding-window mechanism and operate the sequence to sequence neural translation model on the character-level rather than on the word-level. The story segmentation and storyline clustering problem is tackled by examining the low-dimensional vectors produced as a side-product of the neural translation process. The results of this paper describe a novel approach to the automatic story segmentation and storyline clustering problem.
Tied Probabilistic Linear Discriminant Analysis for Speech Recognition
Nov 04, 2014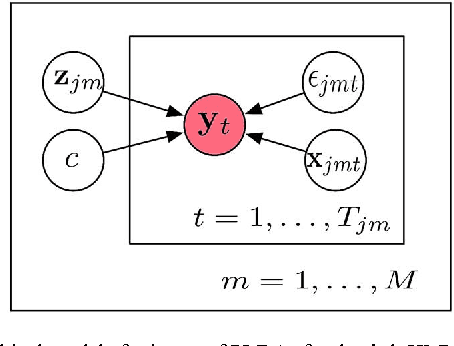
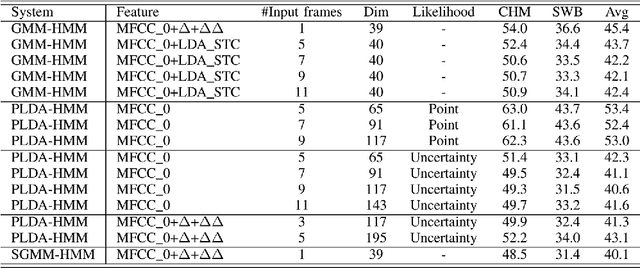
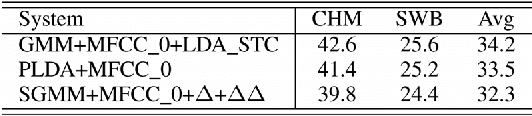
Acoustic models using probabilistic linear discriminant analysis (PLDA) capture the correlations within feature vectors using subspaces which do not vastly expand the model. This allows high dimensional and correlated feature spaces to be used, without requiring the estimation of multiple high dimension covariance matrices. In this letter we extend the recently presented PLDA mixture model for speech recognition through a tied PLDA approach, which is better able to control the model size to avoid overfitting. We carried out experiments using the Switchboard corpus, with both mel frequency cepstral coefficient features and bottleneck feature derived from a deep neural network. Reductions in word error rate were obtained by using tied PLDA, compared with the PLDA mixture model, subspace Gaussian mixture models, and deep neural networks.
Information Extraction from Broadcast News
Mar 30, 2000
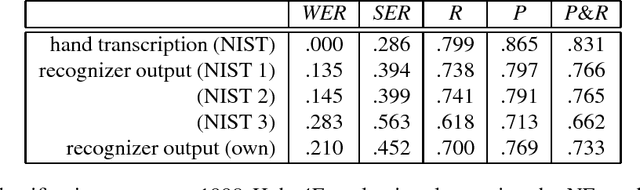
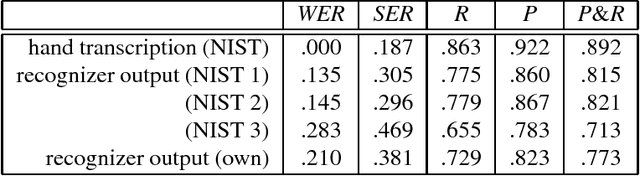
This paper discusses the development of trainable statistical models for extracting content from television and radio news broadcasts. In particular we concentrate on statistical finite state models for identifying proper names and other named entities in broadcast speech. Two models are presented: the first represents name class information as a word attribute; the second represents both word-word and class-class transitions explicitly. A common n-gram based formulation is used for both models. The task of named entity identification is characterized by relatively sparse training data and issues related to smoothing are discussed. Experiments are reported using the DARPA/NIST Hub-4E evaluation for North American Broadcast News.
Variable Word Rate N-grams
Mar 29, 2000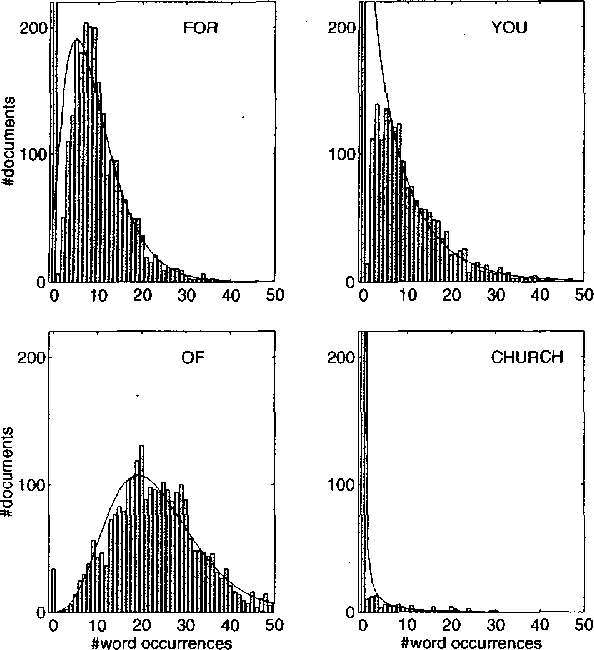
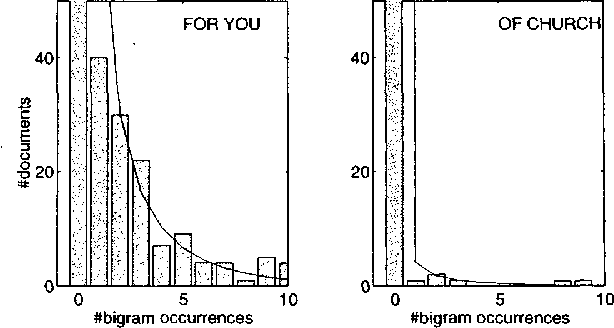
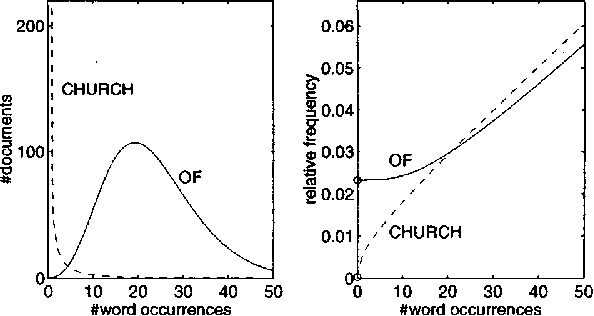
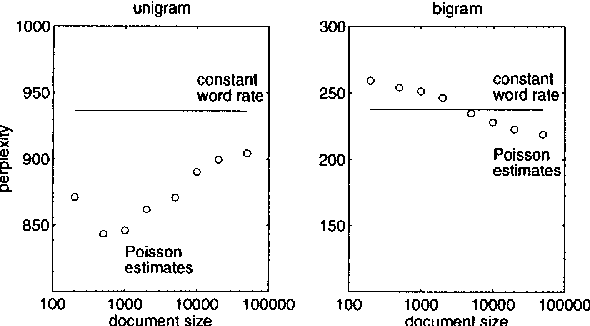
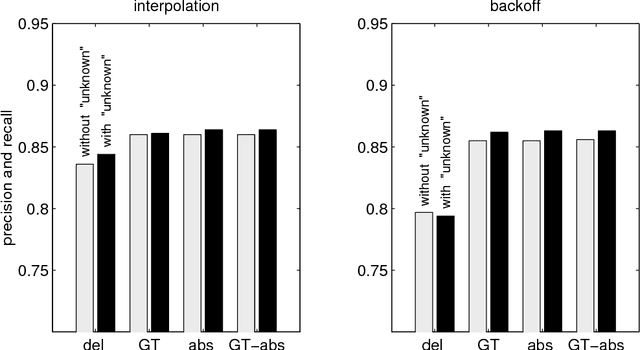
The rate of occurrence of words is not uniform but varies from document to document. Despite this observation, parameters for conventional n-gram language models are usually derived using the assumption of a constant word rate. In this paper we investigate the use of variable word rate assumption, modelled by a Poisson distribution or a continuous mixture of Poissons. We present an approach to estimating the relative frequencies of words or n-grams taking prior information of their occurrences into account. Discounting and smoothing schemes are also considered. Using the Broadcast News task, the approach demonstrates a reduction of perplexity up to 10%.