 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Extraction from Broadcast News
Mar 30, 2000
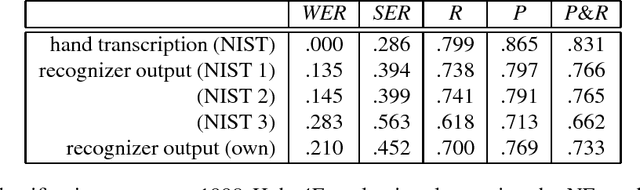
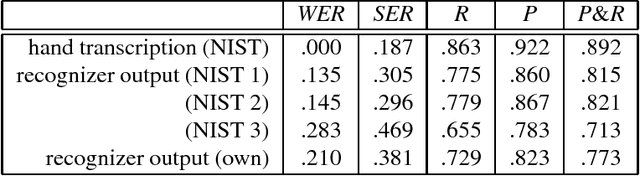
This paper discusses the development of trainable statistical models for extracting content from television and radio news broadcasts. In particular we concentrate on statistical finite state models for identifying proper names and other named entities in broadcast speech. Two models are presented: the first represents name class information as a word attribute; the second represents both word-word and class-class transitions explicitly. A common n-gram based formulation is used for both models. The task of named entity identification is characterized by relatively sparse training data and issues related to smoothing are discussed. Experiments are reported using the DARPA/NIST Hub-4E evaluation for North American Broadcast News.
Variable Word Rate N-grams
Mar 29, 2000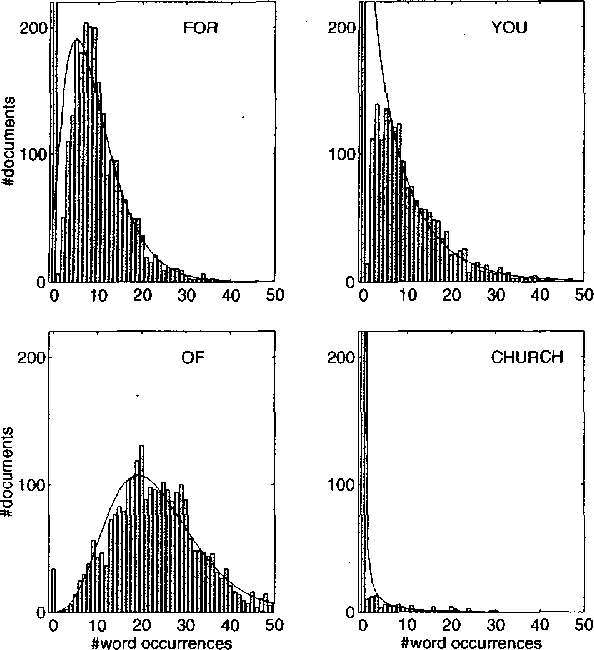
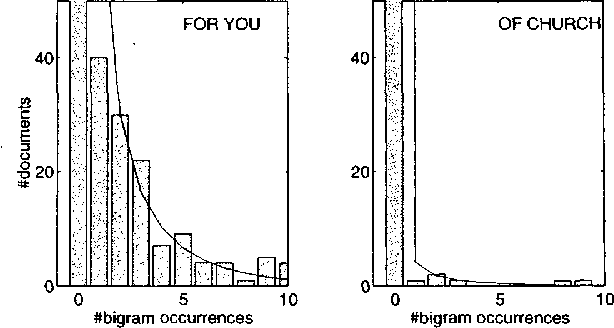
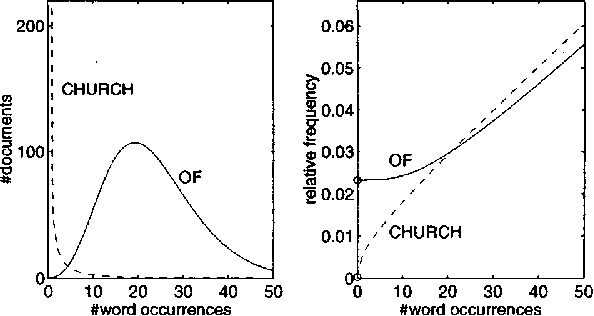
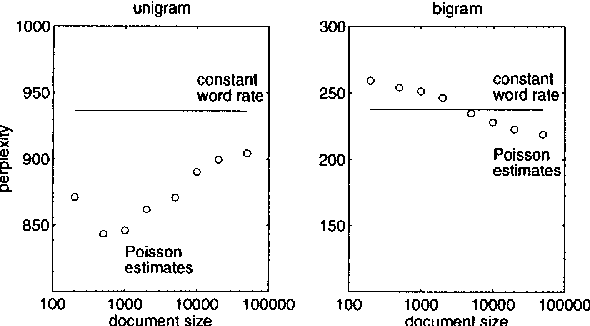
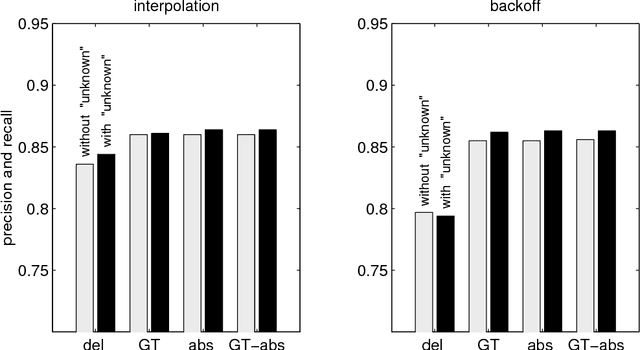
The rate of occurrence of words is not uniform but varies from document to document. Despite this observation, parameters for conventional n-gram language models are usually derived using the assumption of a constant word rate. In this paper we investigate the use of variable word rate assumption, modelled by a Poisson distribution or a continuous mixture of Poissons. We present an approach to estimating the relative frequencies of words or n-grams taking prior information of their occurrences into account. Discounting and smoothing schemes are also considered. Using the Broadcast News task, the approach demonstrates a reduction of perplexity up to 10%.