 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Late Collaborative Perception Framework for 3D Multi-Object and Multi-Source Association and Fusion
Jul 03, 2025In autonomous driving, recent research has increasingly focused on collaborative perception based on deep learning to overcome the limitations of individual perception systems. Although these methods achieve high accuracy, they rely on high communication bandwidth and require unrestricted access to each agent's object detection model architecture and parameters. These constraints pose challenges real-world autonomous driving scenarios, where communication limitations and the need to safeguard proprietary models hinder practical implementation. To address this issue, we introduce a novel late collaborative framework for 3D multi-source and multi-object fusion, which operates solely on shared 3D bounding box attributes-category, size, position, and orientation-without necessitating direct access to detection models. Our framework establishes a new state-of-the-art in late fusion, achieving up to five times lower position error compared to existing methods. Additionally, it reduces scale error by a factor of 7.5 and orientation error by half, all while maintaining perfect 100% precision and recall when fusing detections from heterogeneous perception systems. These results highlight the effectiveness of our approach in addressing real-world collaborative perception challenges, setting a new benchmark for efficient and scalable multi-agent fusion.
Assessing Cross-dataset Generalization of Pedestrian Crossing Predictors
Jan 29, 2022
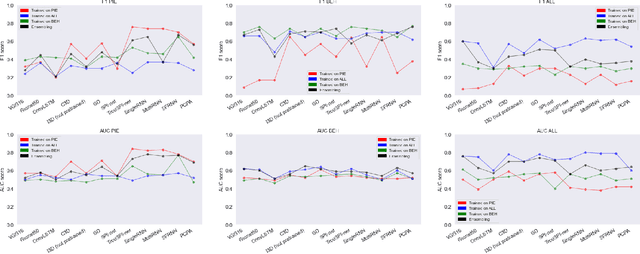
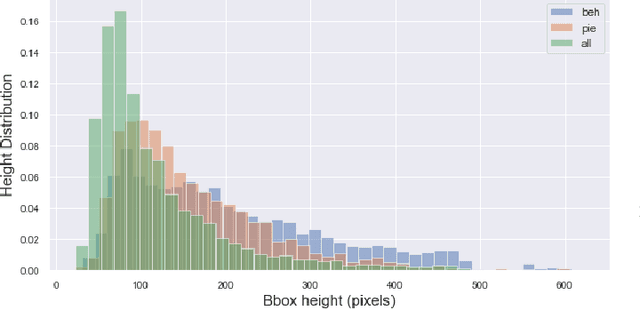
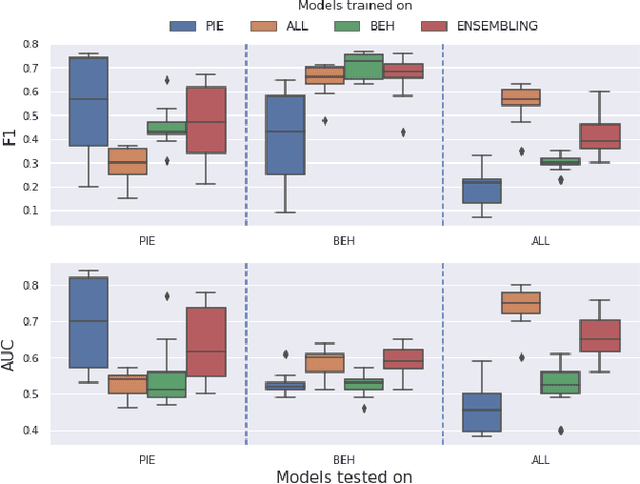
Pedestrian crossing prediction has been a topic of active research, resulting in many new algorithmic solutions. While measuring the overall progress of those solutions over time tends to be more and more established due to the new publicly available benchmark and standardized evaluation procedures, knowing how well existing predictors react to unseen data remains an unanswered question. This evaluation is imperative as serviceable crossing behavior predictors should be set to work in various scenarii without compromising pedestrian safety due to misprediction. To this end, we conduct a study based on direct cross-dataset evaluation. Our experiments show that current state-of-the-art pedestrian behavior predictors generalize poorly in cross-dataset evaluation scenarii, regardless of their robustness during a direct training-test set evaluation setting. In the light of what we observe, we argue that the future of pedestrian crossing prediction, e.g. reliable and generalizable implementations, should not be about tailoring models, trained with very little available data, and tested in a classical train-test scenario with the will to infer anything about their behavior in real life. It should be about evaluating models in a cross-dataset setting while considering their uncertainty estimates under domain shift.
TrouSPI-Net: Spatio-temporal attention on parallel atrous convolutions and U-GRUs for skeletal pedestrian crossing prediction
Sep 07, 2021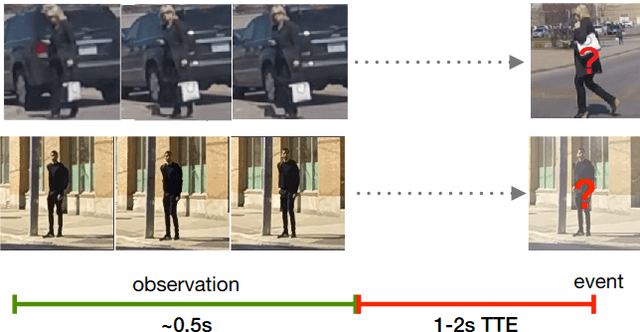
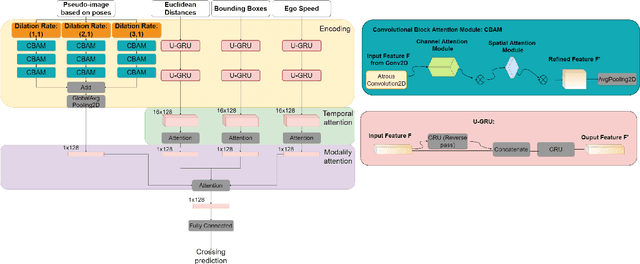
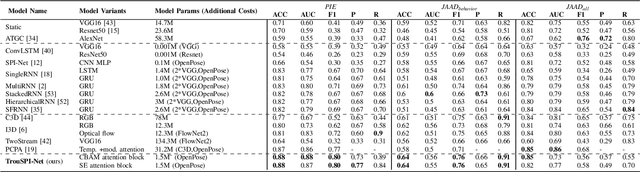
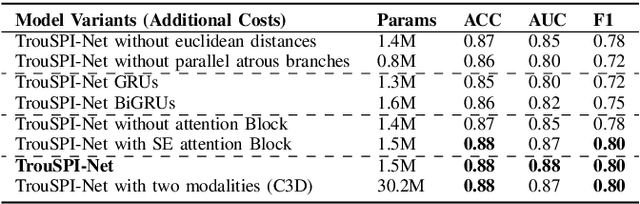
Understanding the behaviors and intentions of pedestrians is still one of the main challenges for vehicle autonomy, as accurate predictions of their intentions can guarantee their safety and driving comfort of vehicles. In this paper, we address pedestrian crossing prediction in urban traffic environments by linking the dynamics of a pedestrian's skeleton to a binary crossing intention. We introduce TrouSPI-Net: a context-free, lightweight, multi-branch predictor. TrouSPI-Net extracts spatio-temporal features for different time resolutions by encoding pseudo-images sequences of skeletal joints' positions and processes them with parallel attention modules and atrous convolutions. The proposed approach is then enhanced by processing features such as relative distances of skeletal joints, bounding box positions, or ego-vehicle speed with U-GRUs. Using the newly proposed evaluation procedures for two large public naturalistic data sets for studying pedestrian behavior in traffic: JAAD and PIE, we evaluate TrouSPI-Net and analyze its performance. Experimental results show that TrouSPI-Net achieved 0.76 F1 score on JAAD and 0.80 F1 score on PIE, therefore outperforming current state-of-the-art while being lightweight and context-free.