 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Approach to Forecasting Financial Volatility with Gaussian Process Envelopes
May 02, 2017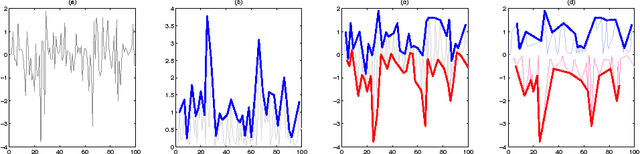
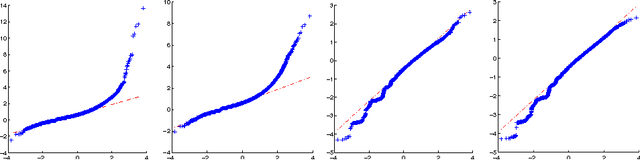
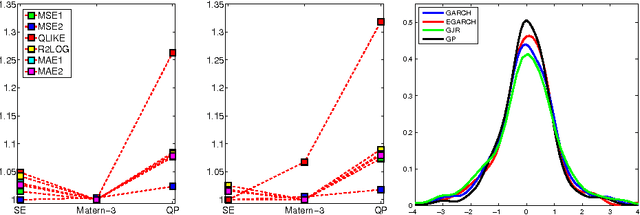
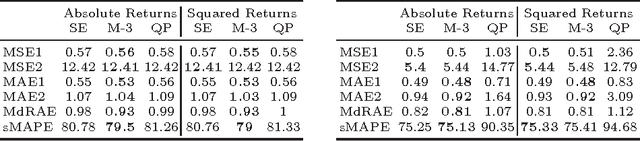
In this paper we use Gaussian Process (GP) regression to propose a novel approach for predicting volatility of financial returns by forecasting the envelopes of the time series. We provide a direct comparison of their performance to traditional approaches such as GARCH. We compare the forecasting power of three approaches: GP regression on the absolute and squared returns; regression on the envelope of the returns and the absolute returns; and regression on the envelope of the negative and positive returns separately. We use a maximum a posteriori estimate with a Gaussian prior to determine our hyperparameters. We also test the effect of hyperparameter updating at each forecasting step. We use our approaches to forecast out-of-sample volatility of four currency pairs over a 2 year period, at half-hourly intervals. From three kernels, we select the kernel giving the best performance for our data. We use two published accuracy measures and four statistical loss functions to evaluate the forecasting ability of GARCH vs GPs. In mean squared error the GP's perform 20% better than a random walk model, and 50% better than GARCH for the same data.
Optimal client recommendation for market makers in illiquid financial products
Apr 27, 2017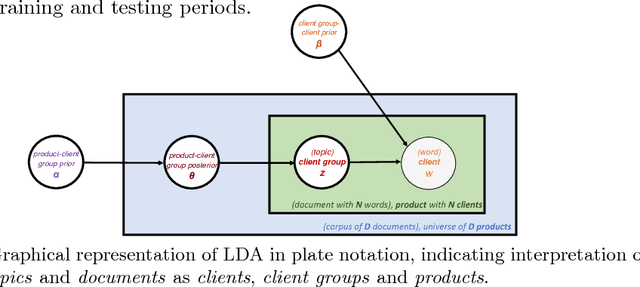
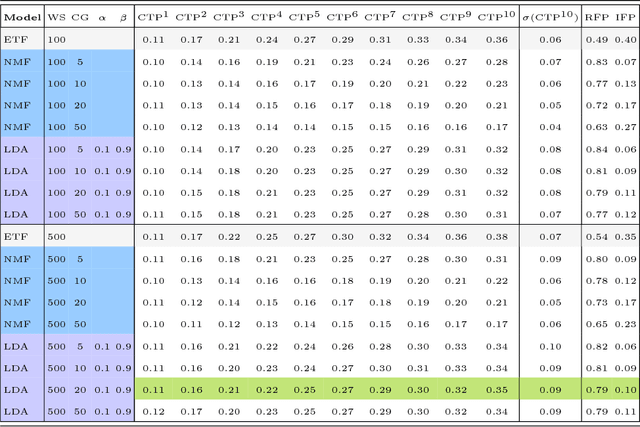
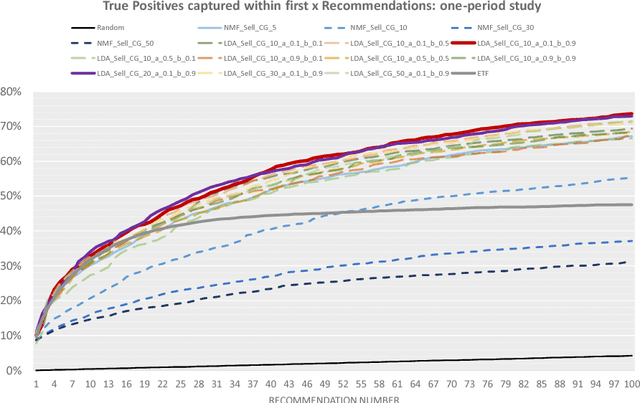
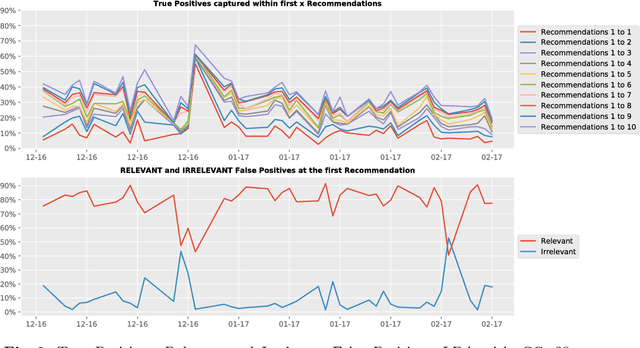
The process of liquidity provision in financial markets can result in prolonged exposure to illiquid instruments for market makers. In this case, where a proprietary position is not desired, pro-actively targeting the right client who is likely to be interested can be an effective means to offset this position, rather than relying on commensurate interest arising through natural demand. In this paper, we consider the inference of a client profile for the purpose of corporate bond recommendation, based on typical recorded information available to the market maker. Given a historical record of corporate bond transactions and bond meta-data, we use a topic-modelling analogy to develop a probabilistic technique for compiling a curated list of client recommendations for a particular bond that needs to be traded, ranked by probability of interest. We show that a model based on Latent Dirichlet Allocation offers promising performance to deliver relevant recommendations for sales traders.
Distribution of Gaussian Process Arc Lengths
Mar 23, 2017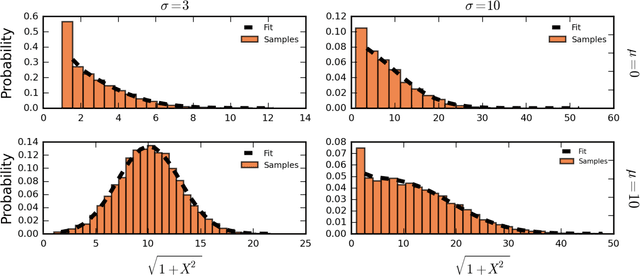
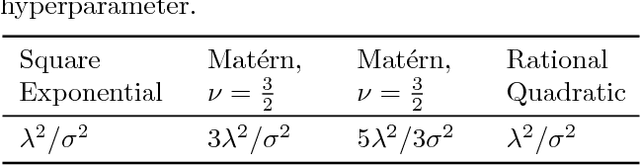
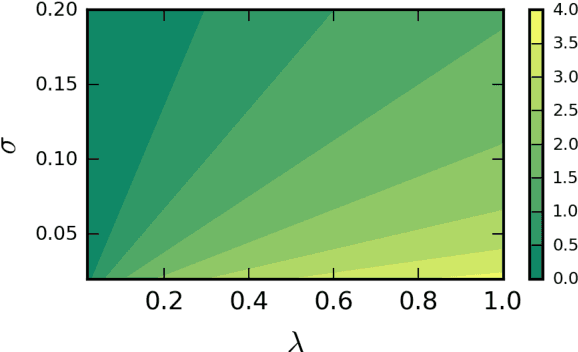
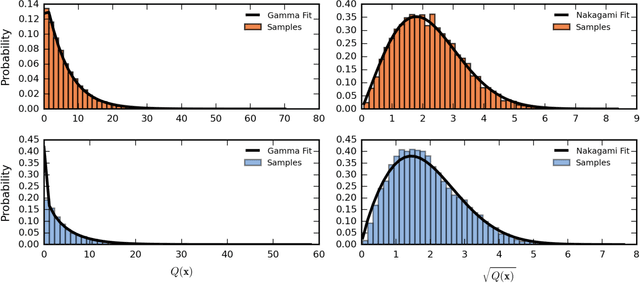
We present the first treatment of the arc length of the Gaussian Process (GP) with more than a single output dimension. GPs are commonly used for tasks such as trajectory modelling, where path length is a crucial quantity of interest. Previously, only paths in one dimension have been considered, with no theoretical consideration of higher dimensional problems. We fill the gap in the existing literature by deriving the moments of the arc length for a stationary GP with multiple output dimensions. A new method is used to derive the mean of a one-dimensional GP over a finite interval, by considering the distribution of the arc length integrand. This technique is used to derive an approximate distribution over the arc length of a vector valued GP in $\mathbb{R}^n$ by moment matching the distribution. Numerical simulations confirm our theoretical derivations.
A Sparse Gaussian Process Framework for Photometric Redshift Estimation
Oct 19, 2015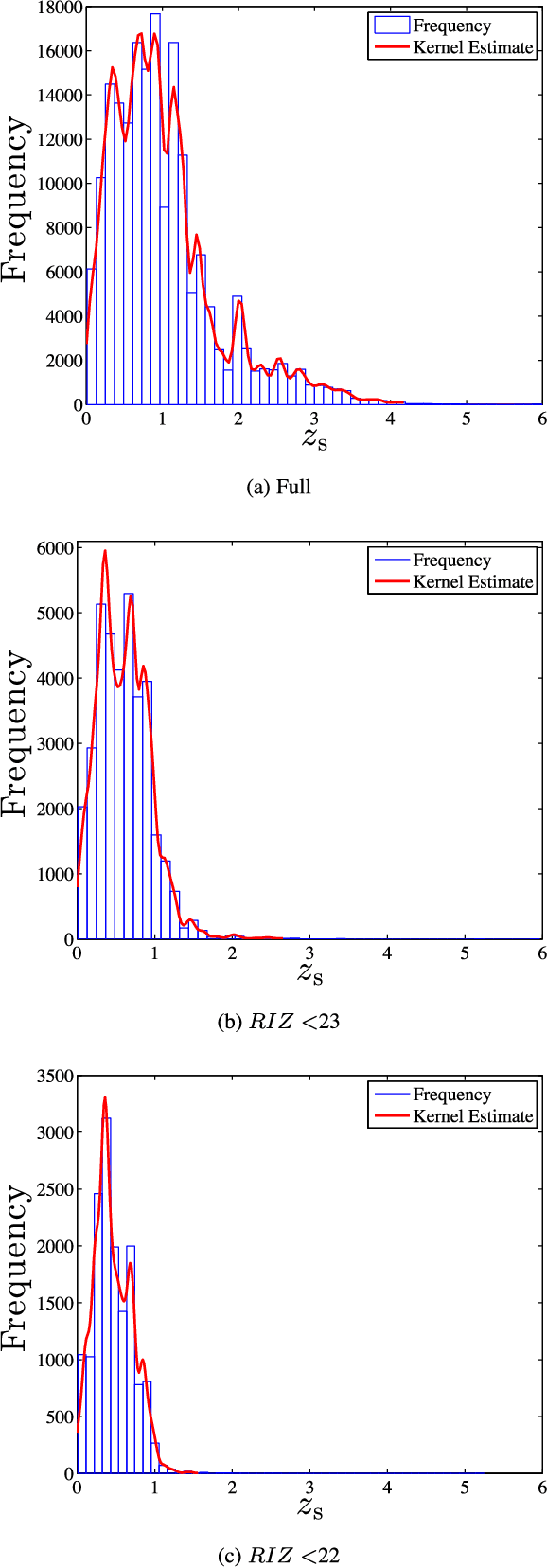
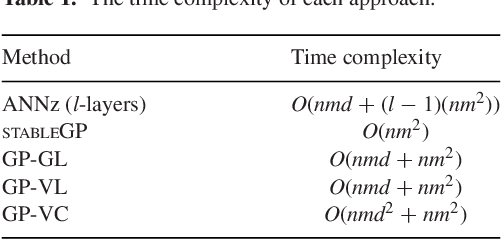

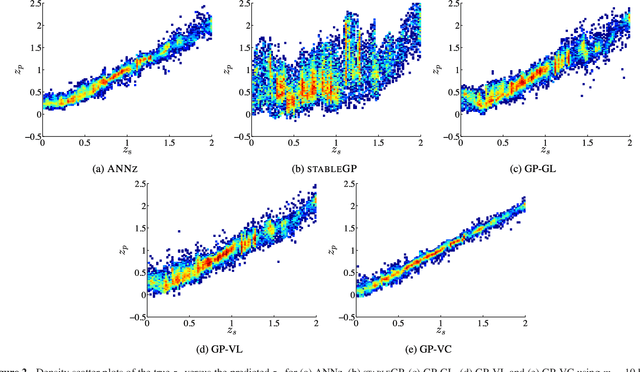
Accurate photometric redshifts are a lynchpin for many future experiments to pin down the cosmological model and for studies of galaxy evolution. In this study, a novel sparse regression framework for photometric redshift estimation is presented. Simulated and real data from SDSS DR12 were used to train and test the proposed models. We show that approaches which include careful data preparation and model design offer a significant improvement in comparison with several competing machine learning algorithms. Standard implementations of most regression algorithms have as the objective the minimization of the sum of squared errors. For redshift inference, however, this induces a bias in the posterior mean of the output distribution, which can be problematic. In this paper we directly target minimizing $\Delta z = (z_\textrm{s} - z_\textrm{p})/(1+z_\textrm{s})$ and address the bias problem via a distribution-based weighting scheme, incorporated as part of the optimization objective. The results are compared with other machine learning algorithms in the field such as Artificial Neural Networks (ANN), Gaussian Processes (GPs) and sparse GPs. The proposed framework reaches a mean absolute $\Delta z = 0.0026(1+z_\textrm{s})$, over the redshift range of $0 \le z_\textrm{s} \le 2$ on the simulated data, and $\Delta z = 0.0178(1+z_\textrm{s})$ over the entire redshift range on the SDSS DR12 survey, outperforming the standard ANNz used in the literature. We also investigate how the relative size of the training set affects the photometric redshift accuracy. We find that a training set of \textgreater 30 per cent of total sample size, provides little additional constraint on the photometric redshifts, and note that our GP formalism strongly outperforms ANNz in the sparse data regime for the simulated data set.
p-Markov Gaussian Processes for Scalable and Expressive Online Bayesian Nonparametric Time Series Forecasting
Oct 09, 2015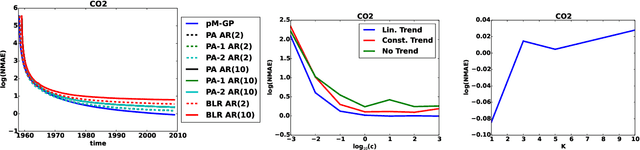
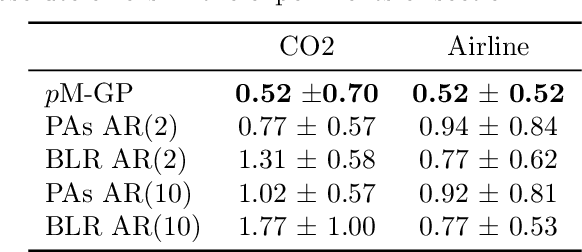
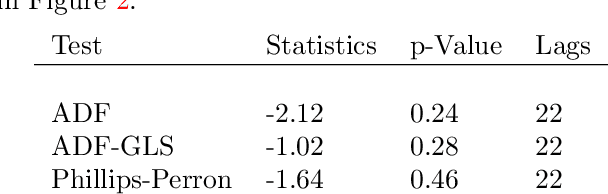
In this paper we introduce a novel online time series forecasting model we refer to as the pM-GP filter. We show that our model is equivalent to Gaussian process regression, with the advantage that both online forecasting and online learning of the hyper-parameters have a constant (rather than cubic) time complexity and a constant (rather than squared) memory requirement in the number of observations, without resorting to approximations. Moreover, the proposed model is expressive in that the family of covariance functions of the implied latent process, namely the spectral Matern kernels, have recently been proven to be capable of approximating arbitrarily well any translation-invariant covariance function. The benefit of our approach compared to competing models is demonstrated using experiments on several real-life datasets.
A Variational Bayesian State-Space Approach to Online Passive-Aggressive Regression
Sep 08, 2015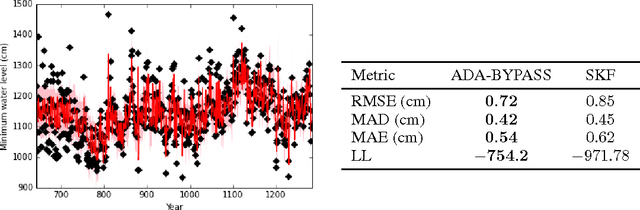


Online Passive-Aggressive (PA) learning is a class of online margin-based algorithms suitable for a wide range of real-time prediction tasks, including classification and regression. PA algorithms are formulated in terms of deterministic point-estimation problems governed by a set of user-defined hyperparameters: the approach fails to capture model/prediction uncertainty and makes their performance highly sensitive to hyperparameter configurations. In this paper, we introduce a novel PA learning framework for regression that overcomes the above limitations. We contribute a Bayesian state-space interpretation of PA regression, along with a novel online variational inference scheme, that not only produces probabilistic predictions, but also offers the benefit of automatic hyperparameter tuning. Experiments with various real-world data sets show that our approach performs significantly better than a more standard, linear Gaussian state-space model.
Variational Inference for Gaussian Process Modulated Poisson Processes
Jul 27, 2015
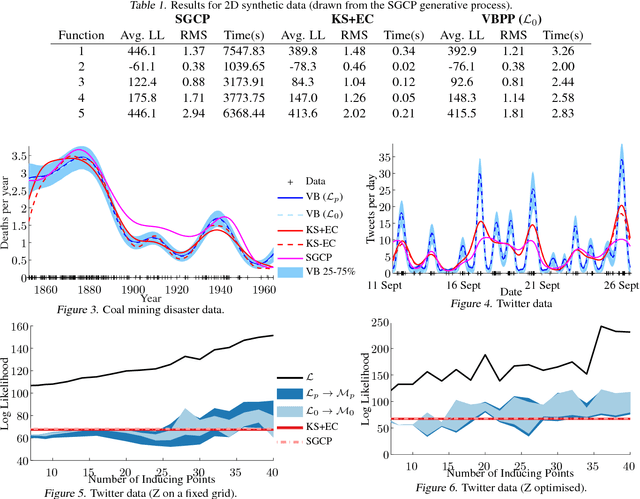

We present the first fully variational Bayesian inference scheme for continuous Gaussian-process-modulated Poisson processes. Such point processes are used in a variety of domains, including neuroscience, geo-statistics and astronomy, but their use is hindered by the computational cost of existing inference schemes. Our scheme: requires no discretisation of the domain; scales linearly in the number of observed events; and is many orders of magnitude faster than previous sampling based approaches. The resulting algorithm is shown to outperform standard methods on synthetic examples, coal mining disaster data and in the prediction of Malaria incidences in Kenya.
Sampling for Inference in Probabilistic Models with Fast Bayesian Quadrature
Nov 03, 2014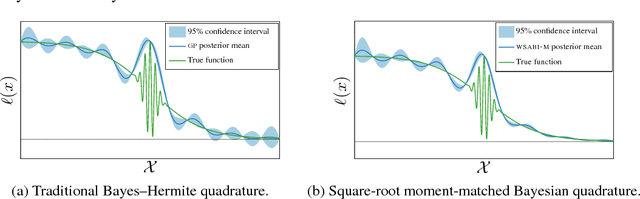
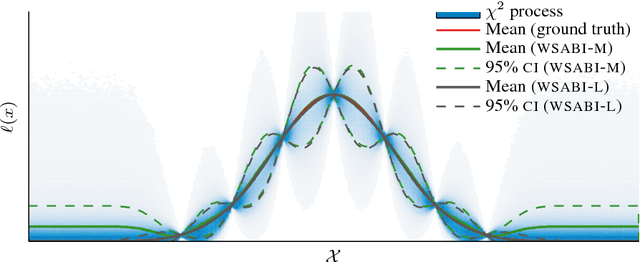
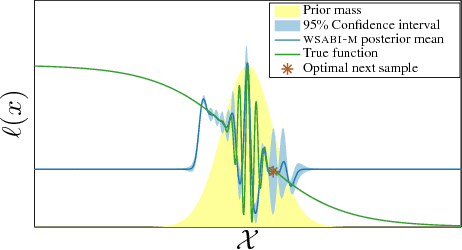
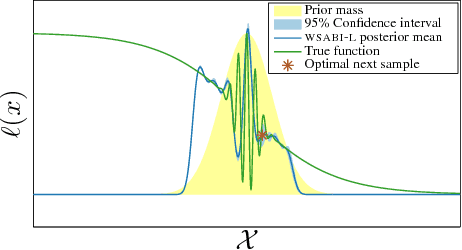
We propose a novel sampling framework for inference in probabilistic models: an active learning approach that converges more quickly (in wall-clock time) than Markov chain Monte Carlo (MCMC) benchmarks. The central challenge in probabilistic inference is numerical integration, to average over ensembles of models or unknown (hyper-)parameters (for example to compute the marginal likelihood or a partition function). MCMC has provided approaches to numerical integration that deliver state-of-the-art inference, but can suffer from sample inefficiency and poor convergence diagnostics. Bayesian quadrature techniques offer a model-based solution to such problems, but their uptake has been hindered by prohibitive computation costs. We introduce a warped model for probabilistic integrands (likelihoods) that are known to be non-negative, permitting a cheap active learning scheme to optimally select sample locations. Our algorithm is demonstrated to offer faster convergence (in seconds) relative to simple Monte Carlo and annealed importance sampling on both synthetic and real-world examples.
Efficient Bayesian Nonparametric Modelling of Structured Point Processes
Jul 25, 2014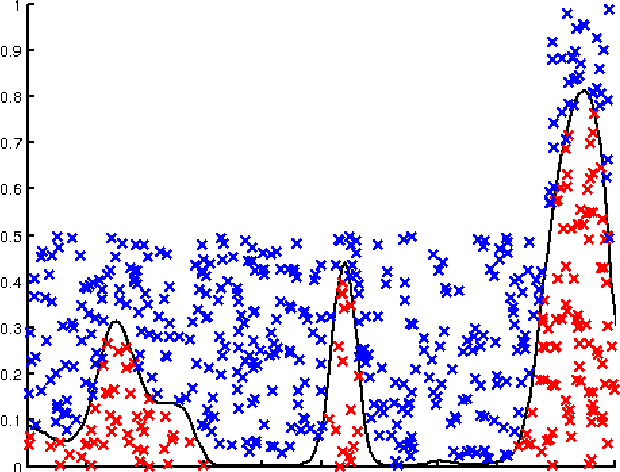
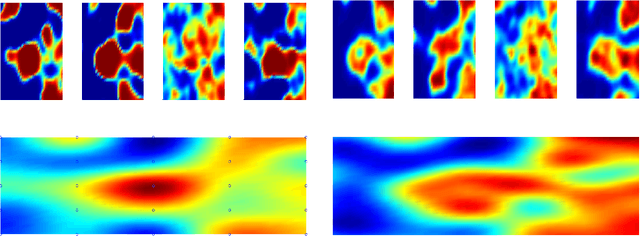
This paper presents a Bayesian generative model for dependent Cox point processes, alongside an efficient inference scheme which scales as if the point processes were modelled independently. We can handle missing data naturally, infer latent structure, and cope with large numbers of observed processes. A further novel contribution enables the model to work effectively in higher dimensional spaces. Using this method, we achieve vastly improved predictive performance on both 2D and 1D real data, validating our structured approach.
* Presented at UAI 2014. Bibtex: @inproceedings{structcoxpp14_UAI, Author = {Tom Gunter and Chris Lloyd and Michael A. Osborne and Stephen J. Roberts}, Title = {Efficient Bayesian Nonparametric Modelling of Structured Point Processes}, Booktitle = {Uncertainty in Artificial Intelligence (UAI)}, Year = {2014}}
Stochastic processes and feedback-linearisation for online identification and Bayesian adaptive control of fully-actuated mechanical systems
Apr 01, 2014



This work proposes a new method for simultaneous probabilistic identification and control of an observable, fully-actuated mechanical system. Identification is achieved by conditioning stochastic process priors on observations of configurations and noisy estimates of configuration derivatives. In contrast to previous work that has used stochastic processes for identification, we leverage the structural knowledge afforded by Lagrangian mechanics and learn the drift and control input matrix functions of the control-affine system separately. We utilise feedback-linearisation to reduce, in expectation, the uncertain nonlinear control problem to one that is easy to regulate in a desired manner. Thereby, our method combines the flexibility of nonparametric Bayesian learning with epistemological guarantees on the expected closed-loop trajectory. We illustrate our method in the context of torque-actuated pendula where the dynamics are learned with a combination of normal and log-normal processes.