 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Grounded Language Learning Agents
Oct 26, 2017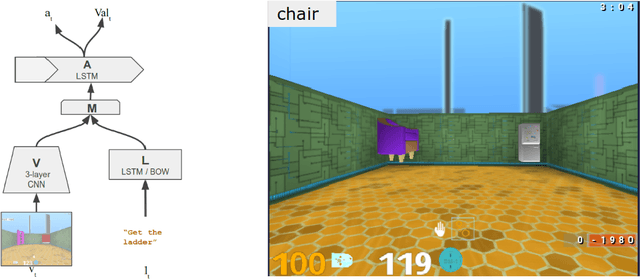

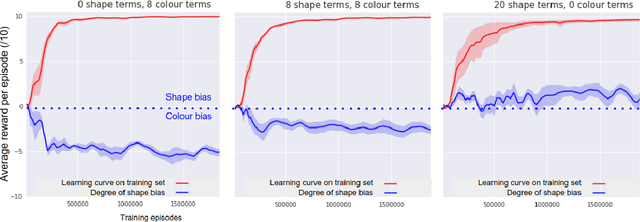

Neural network-based systems can now learn to locate the referents of words and phrases in images, answer questions about visual scenes, and even execute symbolic instructions as first-person actors in partially-observable worlds. To achieve this so-called grounded language learning, models must overcome certain well-studied learning challenges that are also fundamental to infants learning their first words. While it is notable that models with no meaningful prior knowledge overcome these learning obstacles, AI researchers and practitioners currently lack a clear understanding of exactly how they do so. Here we address this question as a way of achieving a clearer general understanding of grounded language learning, both to inform future research and to improve confidence in model predictions. For maximum control and generality, we focus on a simple neural network-based language learning agent trained via policy-gradient methods to interpret synthetic linguistic instructions in a simulated 3D world. We apply experimental paradigms from developmental psychology to this agent, exploring the conditions under which established human biases and learning effects emerge. We further propose a novel way to visualise and analyse semantic representation in grounded language learning agents that yields a plausible computational account of the observed effects.
Jointly Learning Sentence Embeddings and Syntax with Unsupervised Tree-LSTMs
May 25, 2017
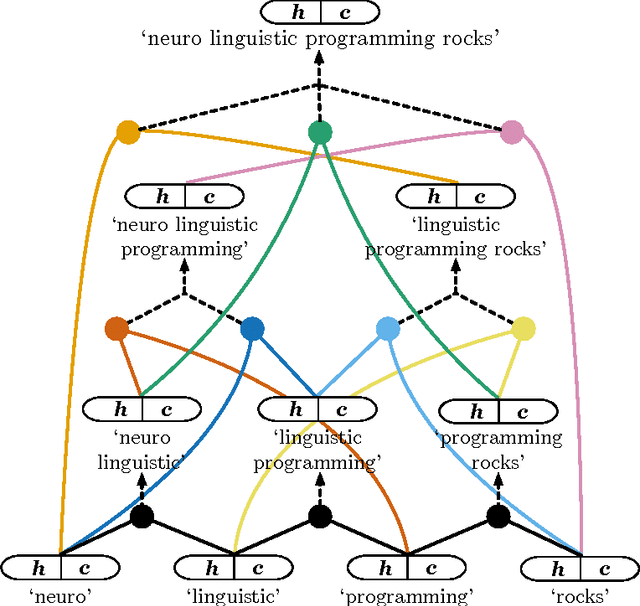
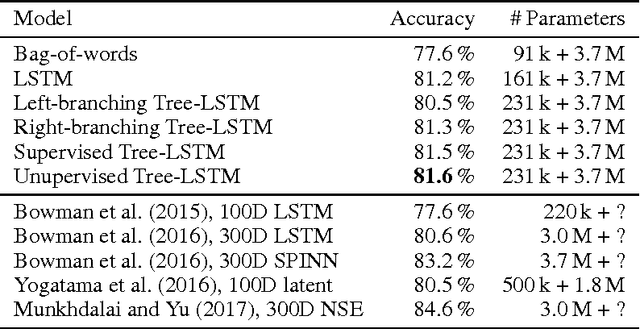
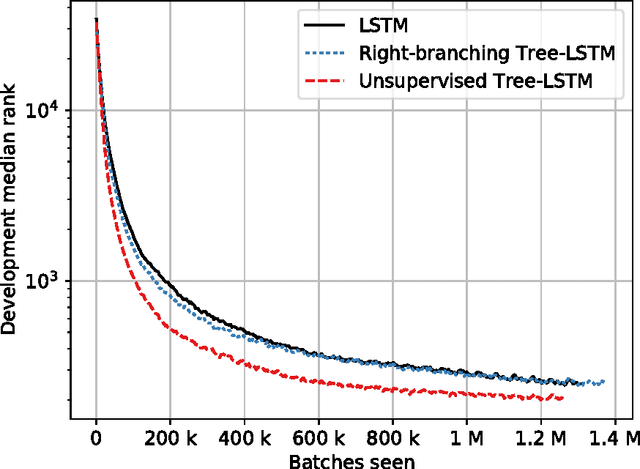
We introduce a neural network that represents sentences by composing their words according to induced binary parse trees. We use Tree-LSTM as our composition function, applied along a tree structure found by a fully differentiable natural language chart parser. Our model simultaneously optimises both the composition function and the parser, thus eliminating the need for externally-provided parse trees which are normally required for Tree-LSTM. It can therefore be seen as a tree-based RNN that is unsupervised with respect to the parse trees. As it is fully differentiable, our model is easily trained with an off-the-shelf gradient descent method and backpropagation. We demonstrate that it achieves better performance compared to various supervised Tree-LSTM architectures on a textual entailment task and a reverse dictionary task.
Latent Variable Dialogue Models and their Diversity
Feb 20, 2017
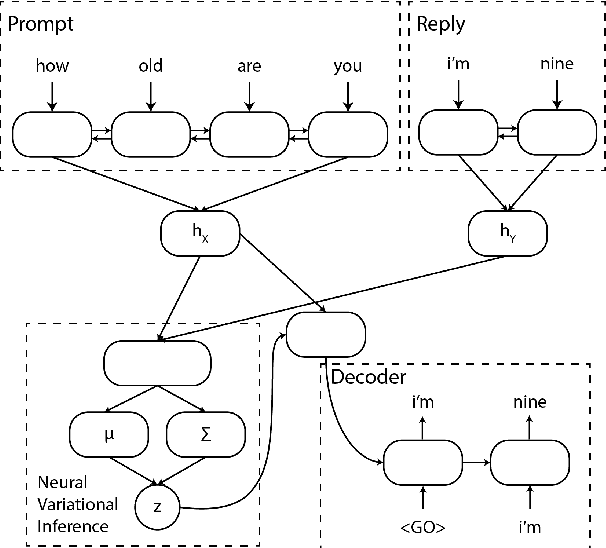
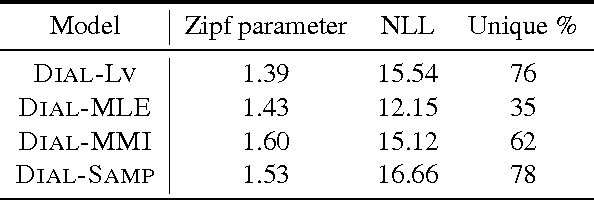

We present a dialogue generation model that directly captures the variability in possible responses to a given input, which reduces the `boring output' issue of deterministic dialogue models. Experiments show that our model generates more diverse outputs than baseline models, and also generates more consistently acceptable output than sampling from a deterministic encoder-decoder model.
Virtual Embodiment: A Scalable Long-Term Strategy for Artificial Intelligence Research
Oct 24, 2016Meaning has been called the "holy grail" of a variety of scientific disciplines, ranging from linguistics to philosophy, psychology and the neurosciences. The field of Artifical Intelligence (AI) is very much a part of that list: the development of sophisticated natural language semantics is a sine qua non for achieving a level of intelligence comparable to humans. Embodiment theories in cognitive science hold that human semantic representation depends on sensori-motor experience; the abundant evidence that human meaning representation is grounded in the perception of physical reality leads to the conclusion that meaning must depend on a fusion of multiple (perceptual) modalities. Despite this, AI research in general, and its subdisciplines such as computational linguistics and computer vision in particular, have focused primarily on tasks that involve a single modality. Here, we propose virtual embodiment as an alternative, long-term strategy for AI research that is multi-modal in nature and that allows for the kind of scalability required to develop the field coherently and incrementally, in an ethically responsible fashion.
Using Sentence Plausibility to Learn the Semantics of Transitive Verbs
Dec 12, 2014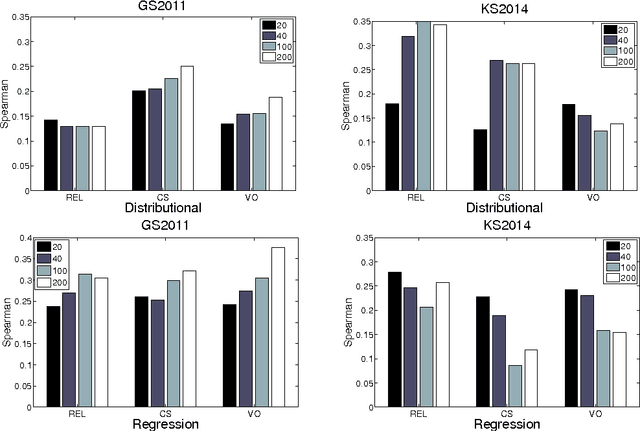
The functional approach to compositional distributional semantics considers transitive verbs to be linear maps that transform the distributional vectors representing nouns into a vector representing a sentence. We conduct an initial investigation that uses a matrix consisting of the parameters of a logistic regression classifier trained on a plausibility task as a transitive verb function. We compare our method to a commonly used corpus-based method for constructing a verb matrix and find that the plausibility training may be more effective for disambiguation tasks.
The Frobenius anatomy of word meanings II: possessive relative pronouns
Jun 18, 2014Within the categorical compositional distributional model of meaning, we provide semantic interpretations for the subject and object roles of the possessive relative pronoun `whose'. This is done in terms of Frobenius algebras over compact closed categories. These algebras and their diagrammatic language expose how meanings of words in relative clauses interact with each other. We show how our interpretation is related to Montague-style semantics and provide a truth-theoretic interpretation. We also show how vector spaces provide a concrete interpretation and provide preliminary corpus-based experimental evidence. In a prequel to this paper, we used similar methods and dealt with the case of subject and object relative pronouns.
The Frobenius anatomy of word meanings I: subject and object relative pronouns
Apr 21, 2014This paper develops a compositional vector-based semantics of subject and object relative pronouns within a categorical framework. Frobenius algebras are used to formalise the operations required to model the semantics of relative pronouns, including passing information between the relative clause and the modified noun phrase, as well as copying, combining, and discarding parts of the relative clause. We develop two instantiations of the abstract semantics, one based on a truth-theoretic approach and one based on corpus statistics.
* 31 pages
Learning Type-Driven Tensor-Based Meaning Representations
Feb 18, 2014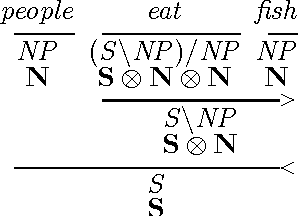
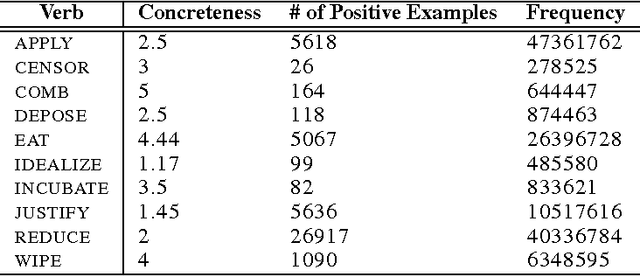
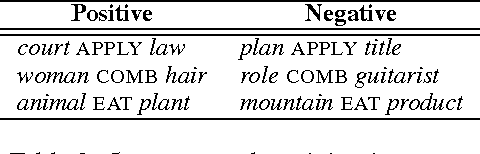
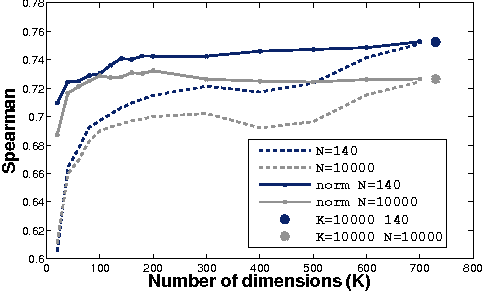
This paper investigates the learning of 3rd-order tensors representing the semantics of transitive verbs. The meaning representations are part of a type-driven tensor-based semantic framework, from the newly emerging field of compositional distributional semantics. Standard techniques from the neural networks literature are used to learn the tensors, which are tested on a selectional preference-style task with a simple 2-dimensional sentence space. Promising results are obtained against a competitive corpus-based baseline. We argue that extending this work beyond transitive verbs, and to higher-dimensional sentence spaces, is an interesting and challenging problem for the machine learning community to consider.
A quantum teleportation inspired algorithm produces sentence meaning from word meaning and grammatical structure
Oct 11, 2013We discuss an algorithm which produces the meaning of a sentence given meanings of its words, and its resemblance to quantum teleportation. In fact, this protocol was the main source of inspiration for this algorithm which has many applications in the area of Natural Language Processing.
Concrete Sentence Spaces for Compositional Distributional Models of Meaning
Dec 31, 2010Coecke, Sadrzadeh, and Clark (arXiv:1003.4394v1 [cs.CL]) developed a compositional model of meaning for distributional semantics, in which each word in a sentence has a meaning vector and the distributional meaning of the sentence is a function of the tensor products of the word vectors. Abstractly speaking, this function is the morphism corresponding to the grammatical structure of the sentence in the category of finite dimensional vector spaces. In this paper, we provide a concrete method for implementing this linear meaning map, by constructing a corpus-based vector space for the type of sentence. Our construction method is based on structured vector spaces whereby meaning vectors of all sentences, regardless of their grammatical structure, live in the same vector space. Our proposed sentence space is the tensor product of two noun spaces, in which the basis vectors are pairs of words each augmented with a grammatical role. This enables us to compare meanings of sentences by simply taking the inner product of their vectors.
* 10 pages, presented at the International Conference on Computational Semantics 2011 (IWCS'11), to be published in proceedings