 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Training of Tensors for Compositional Distributional Semantics
May 05, 2017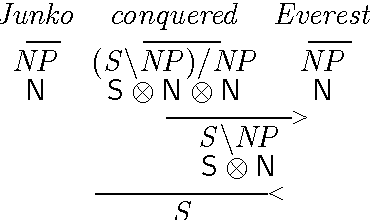
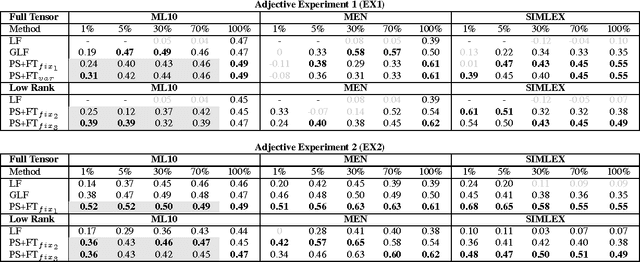

Type-based compositional distributional semantic models present an interesting line of research into functional representations of linguistic meaning. One of the drawbacks of such models, however, is the lack of training data required to train each word-type combination. In this paper we address this by introducing training methods that share parameters between similar words. We show that these methods enable zero-shot learning for words that have no training data at all, as well as enabling construction of high-quality tensors from very few training examples per word.
Using Sentence Plausibility to Learn the Semantics of Transitive Verbs
Dec 12, 2014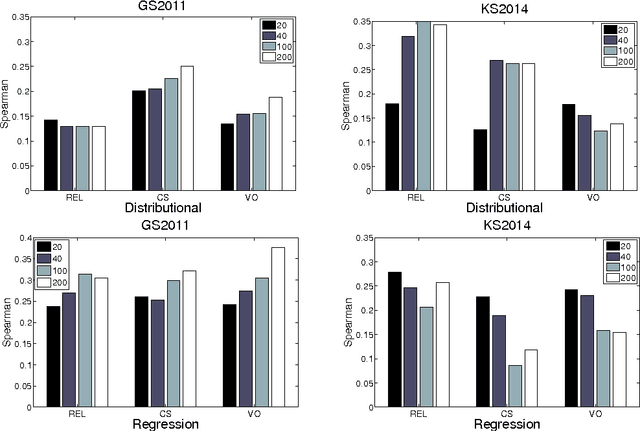
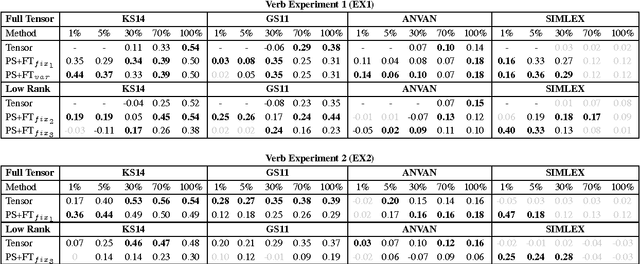
The functional approach to compositional distributional semantics considers transitive verbs to be linear maps that transform the distributional vectors representing nouns into a vector representing a sentence. We conduct an initial investigation that uses a matrix consisting of the parameters of a logistic regression classifier trained on a plausibility task as a transitive verb function. We compare our method to a commonly used corpus-based method for constructing a verb matrix and find that the plausibility training may be more effective for disambiguation tasks.
Learning Type-Driven Tensor-Based Meaning Representations
Feb 18, 2014
This paper investigates the learning of 3rd-order tensors representing the semantics of transitive verbs. The meaning representations are part of a type-driven tensor-based semantic framework, from the newly emerging field of compositional distributional semantics. Standard techniques from the neural networks literature are used to learn the tensors, which are tested on a selectional preference-style task with a simple 2-dimensional sentence space. Promising results are obtained against a competitive corpus-based baseline. We argue that extending this work beyond transitive verbs, and to higher-dimensional sentence spaces, is an interesting and challenging problem for the machine learning community to consider.