 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Strategies and Data Augmentations in CNN-based DeepFake Video Detection
Nov 16, 2020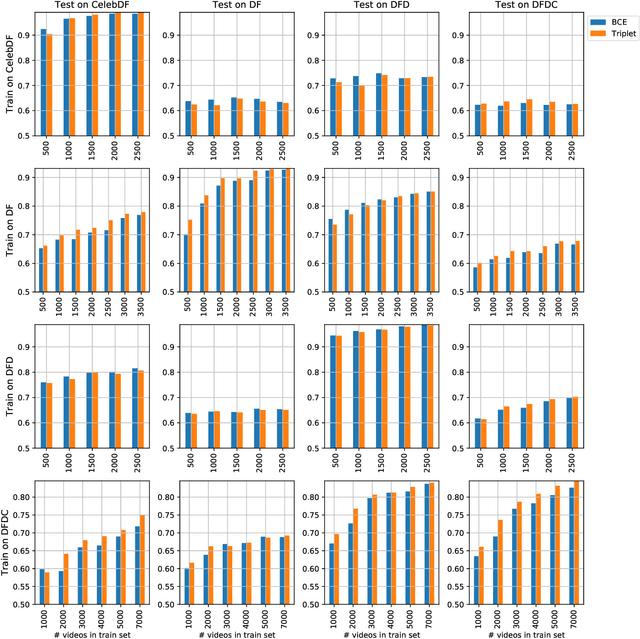
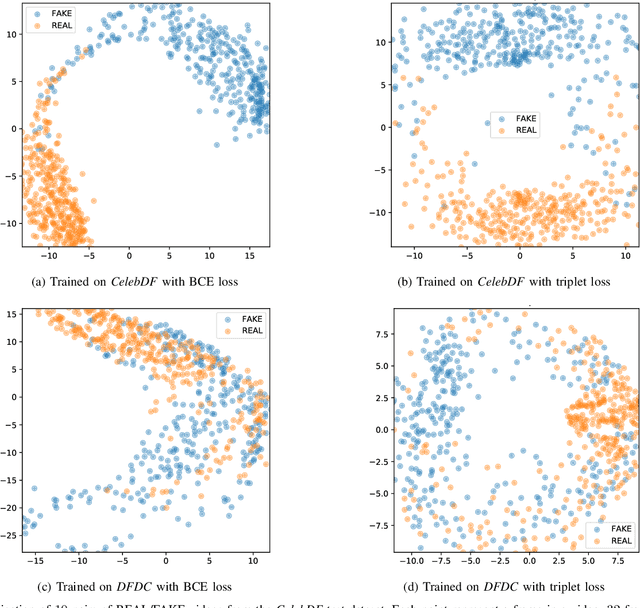
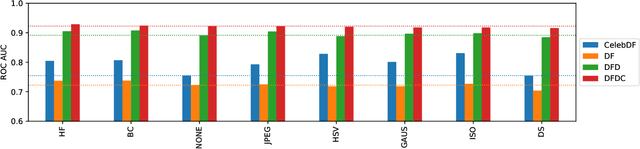
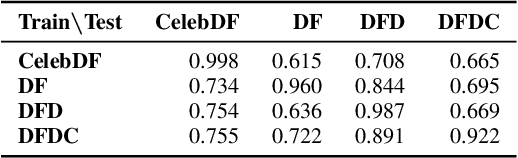
The fast and continuous growth in number and quality of deepfake videos calls for the development of reliable detection systems capable of automatically warning users on social media and on the Internet about the potential untruthfulness of such contents. While algorithms, software, and smartphone apps are getting better every day in generating manipulated videos and swapping faces, the accuracy of automated systems for face forgery detection in videos is still quite limited and generally biased toward the dataset used to design and train a specific detection system. In this paper we analyze how different training strategies and data augmentation techniques affect CNN-based deepfake detectors when training and testing on the same dataset or across different datasets.
Training CNNs in Presence of JPEG Compression: Multimedia Forensics vs Computer Vision
Sep 25, 2020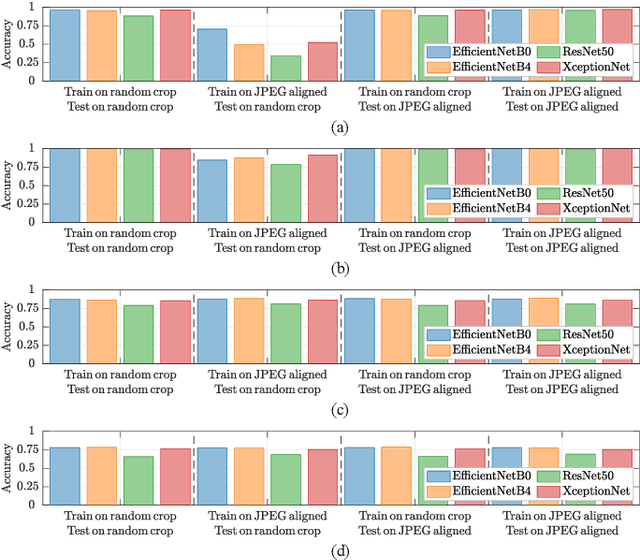
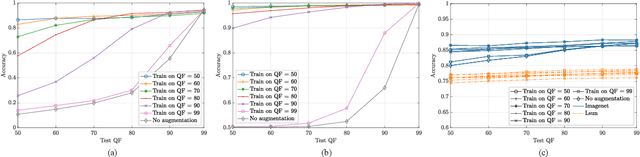
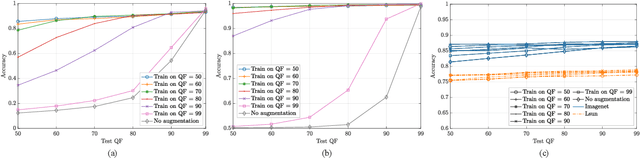
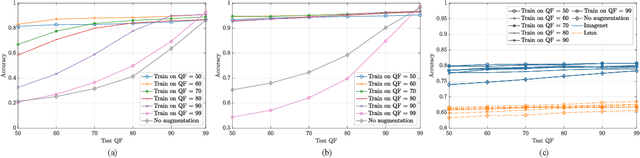
Convolutional Neural Networks (CNNs) have proved very accurate in multiple computer vision image classification tasks that required visual inspection in the past (e.g., object recognition, face detection, etc.). Motivated by these astonishing results, researchers have also started using CNNs to cope with image forensic problems (e.g., camera model identification, tampering detection, etc.). However, in computer vision, image classification methods typically rely on visual cues easily detectable by human eyes. Conversely, forensic solutions rely on almost invisible traces that are often very subtle and lie in the fine details of the image under analysis. For this reason, training a CNN to solve a forensic task requires some special care, as common processing operations (e.g., resampling, compression, etc.) can strongly hinder forensic traces. In this work, we focus on the effect that JPEG has on CNN training considering different computer vision and forensic image classification problems. Specifically, we consider the issues that rise from JPEG compression and misalignment of the JPEG grid. We show that it is necessary to consider these effects when generating a training dataset in order to properly train a forensic detector not losing generalization capability, whereas it is almost possible to ignore these effects for computer vision tasks.
FOCAL: A Forgery Localization Framework based on Video Coding Self-Consistency
Sep 04, 2020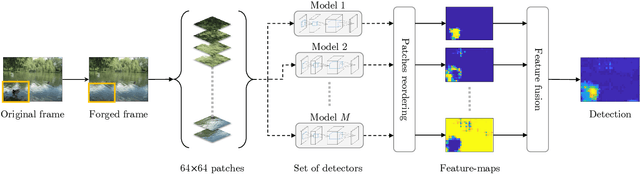
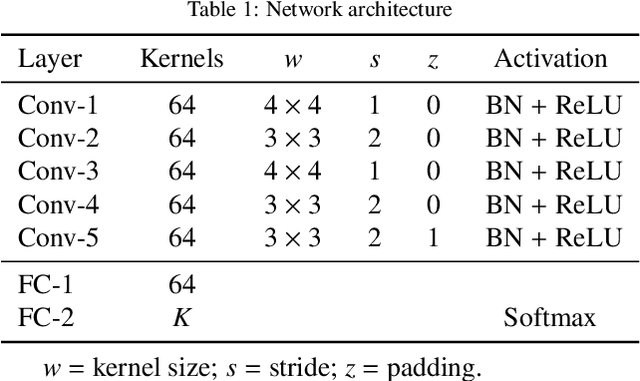
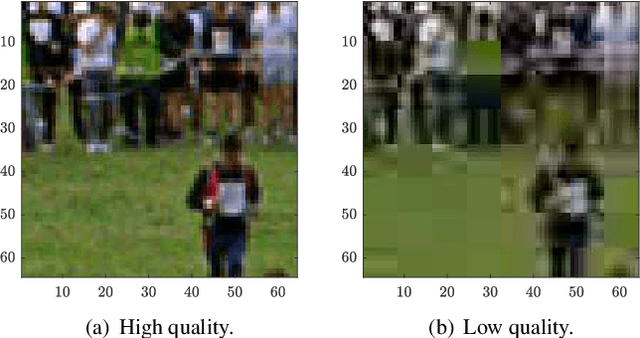
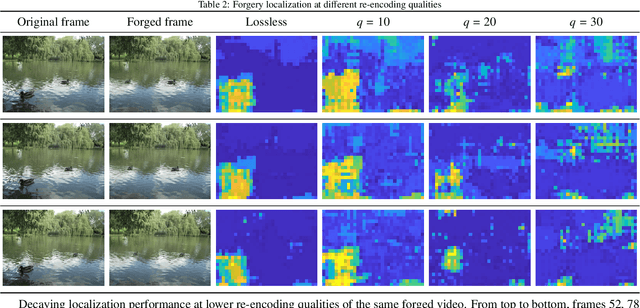
Forgery operations on video contents are nowadays within the reach of anyone, thanks to the availability of powerful and user-friendly editing software. Integrity verification and authentication of videos represent a major interest in both journalism (e.g., fake news debunking) and legal environments dealing with digital evidence (e.g., a court of law). While several strategies and different forensics traces have been proposed in recent years, latest solutions aim at increasing the accuracy by combining multiple detectors and features. This paper presents a video forgery localization framework that verifies the self-consistency of coding traces between and within video frames, by fusing the information derived from a set of independent feature descriptors. The feature extraction step is carried out by means of an explainable convolutional neural network architecture, specifically designed to look for and classify coding artifacts. The overall framework was validated in two typical forgery scenarios: temporal and spatial splicing. Experimental results show an improvement to the state-of-the-art on temporal splicing localization and also promising performance in the newly tackled case of spatial splicing, on both synthetic and real-world videos.
A Modified Fourier-Mellin Approach for Source Device Identification on Stabilized Videos
May 20, 2020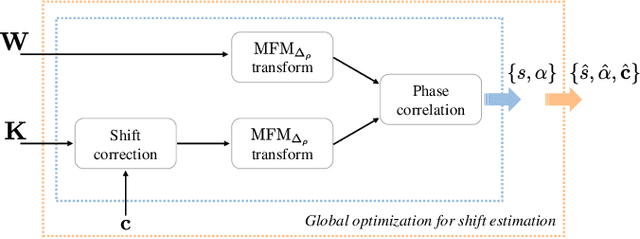
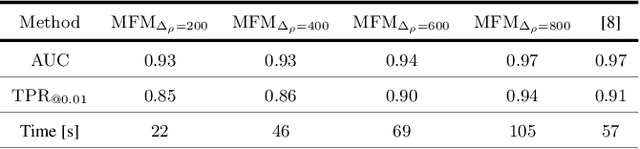
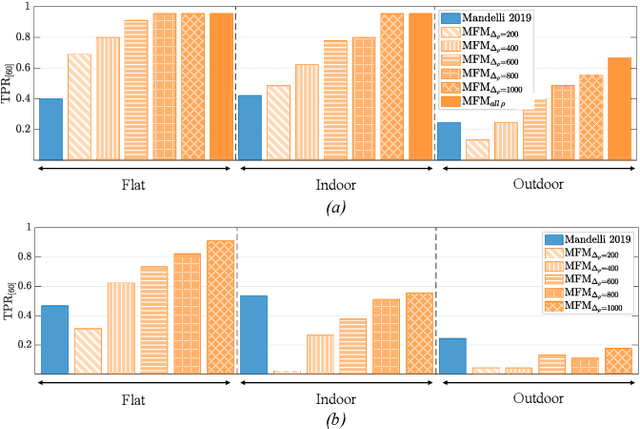
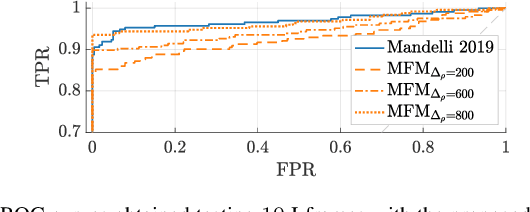
To decide whether a digital video has been captured by a given device, multimedia forensic tools usually exploit characteristic noise traces left by the camera sensor on the acquired frames. This analysis requires that the noise pattern characterizing the camera and the noise pattern extracted from video frames under analysis are geometrically aligned. However, in many practical scenarios this does not occur, thus a re-alignment or synchronization has to be performed. Current solutions often require time consuming search of the realignment transformation parameters. In this paper, we propose to overcome this limitation by searching scaling and rotation parameters in the frequency domain. The proposed algorithm tested on real videos from a well-known state-of-the-art dataset shows promising results.
On the use of Benford's law to detect GAN-generated images
Apr 16, 2020
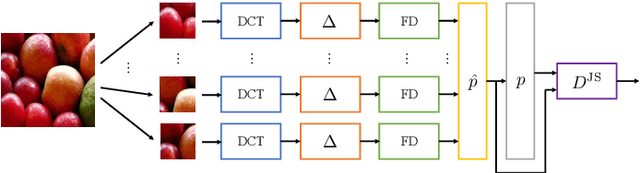
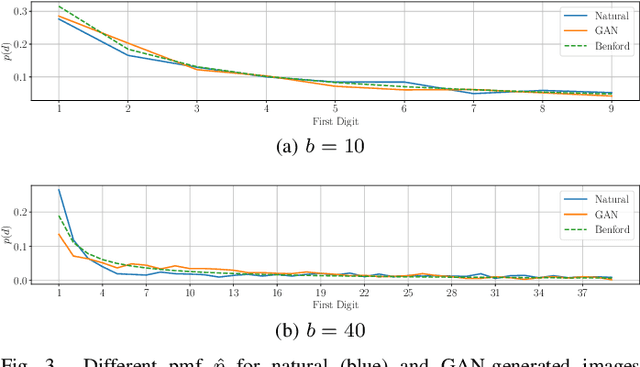

The advent of Generative Adversarial Network (GAN) architectures has given anyone the ability of generating incredibly realistic synthetic imagery. The malicious diffusion of GAN-generated images may lead to serious social and political consequences (e.g., fake news spreading, opinion formation, etc.). It is therefore important to regulate the widespread distribution of synthetic imagery by developing solutions able to detect them. In this paper, we study the possibility of using Benford's law to discriminate GAN-generated images from natural photographs. Benford's law describes the distribution of the most significant digit for quantized Discrete Cosine Transform (DCT) coefficients. Extending and generalizing this property, we show that it is possible to extract a compact feature vector from an image. This feature vector can be fed to an extremely simple classifier for GAN-generated image detection purpose.
Video Face Manipulation Detection Through Ensemble of CNNs
Apr 16, 2020
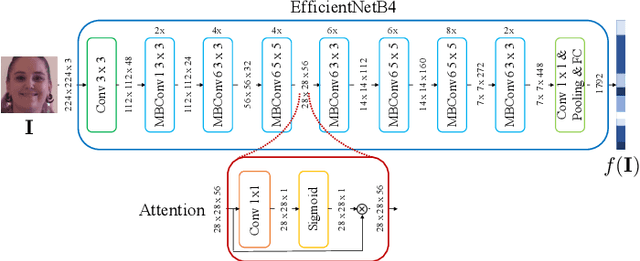
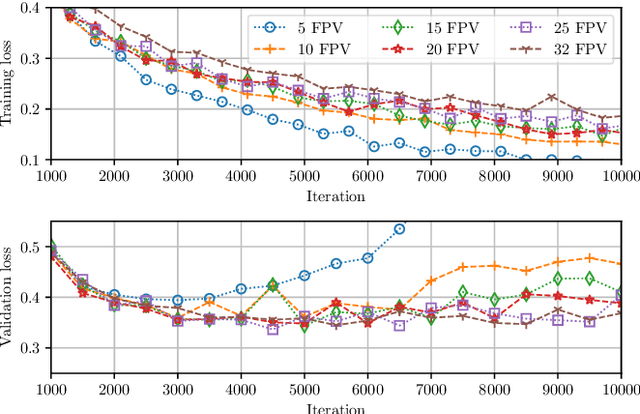

In the last few years, several techniques for facial manipulation in videos have been successfully developed and made available to the masses (i.e., FaceSwap, deepfake, etc.). These methods enable anyone to easily edit faces in video sequences with incredibly realistic results and a very little effort. Despite the usefulness of these tools in many fields, if used maliciously, they can have a significantly bad impact on society (e.g., fake news spreading, cyber bullying through fake revenge porn). The ability of objectively detecting whether a face has been manipulated in a video sequence is then a task of utmost importance. In this paper, we tackle the problem of face manipulation detection in video sequences targeting modern facial manipulation techniques. In particular, we study the ensembling of different trained Convolutional Neural Network (CNN) models. In the proposed solution, different models are obtained starting from a base network (i.e., EfficientNetB4) making use of two different concepts: (i) attention layers; (ii) siamese training. We show that combining these networks leads to promising face manipulation detection results on two publicly available datasets with more than 119000 videos.
CNN-based fast source device identification
Jan 31, 2020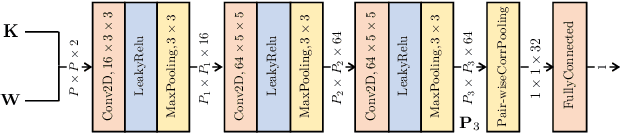
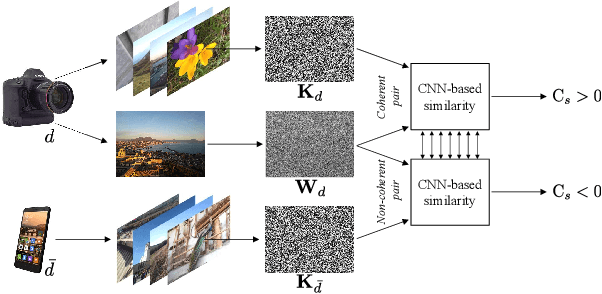
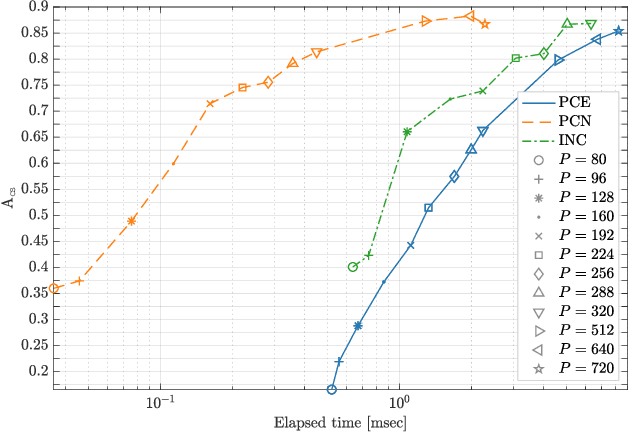
Source identification is an important topic in image forensics, since it allows to trace back the origin of an image. This represents a precious information to claim intellectual property but also to reveal the authors of illicit materials. In this paper we address the problem of device identification based on sensor noise and propose a fast and accurate solution using convolutional neural networks (CNNs). Specifically, we propose a 2-channel-based CNN that learns a way of comparing camera fingerprint and image noise at patch level. The proposed solution turns out to be much faster than the conventional approach and to ensure an increased accuracy. This makes the approach particularly suitable in scenarios where large databases of images are analyzed, like over social networks. In this vein, since images uploaded on social media usually undergo at least two compression stages, we include investigations on double JPEG compressed images, always reporting higher accuracy than standard approaches.
We Need No Pixels: Video Manipulation Detection Using Stream Descriptors
Jun 20, 2019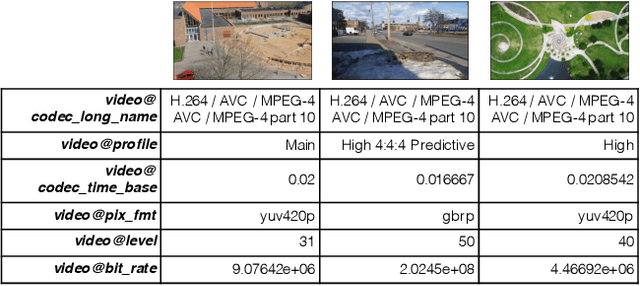
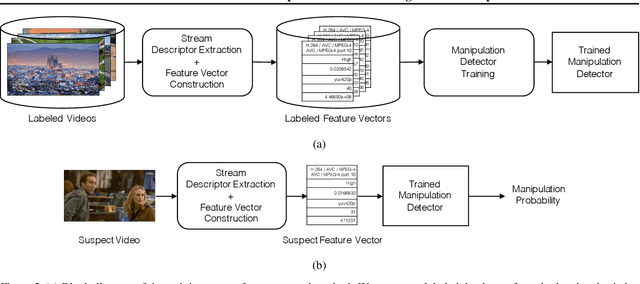
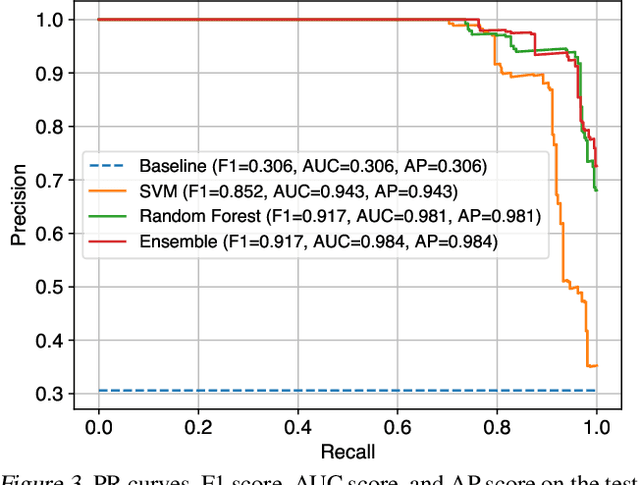
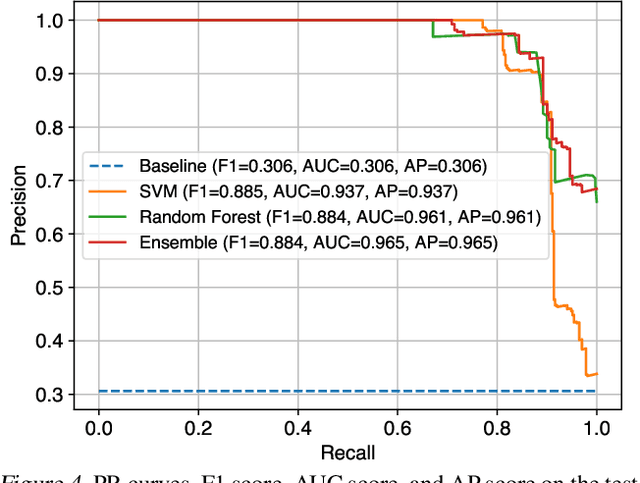
Manipulating video content is easier than ever. Due to the misuse potential of manipulated content, multiple detection techniques that analyze the pixel data from the videos have been proposed. However, clever manipulators should also carefully forge the metadata and auxiliary header information, which is harder to do for videos than images. In this paper, we propose to identify forged videos by analyzing their multimedia stream descriptors with simple binary classifiers, completely avoiding the pixel space. Using well-known datasets, our results show that this scalable approach can achieve a high manipulation detection score if the manipulators have not done a careful data sanitization of the multimedia stream descriptors.
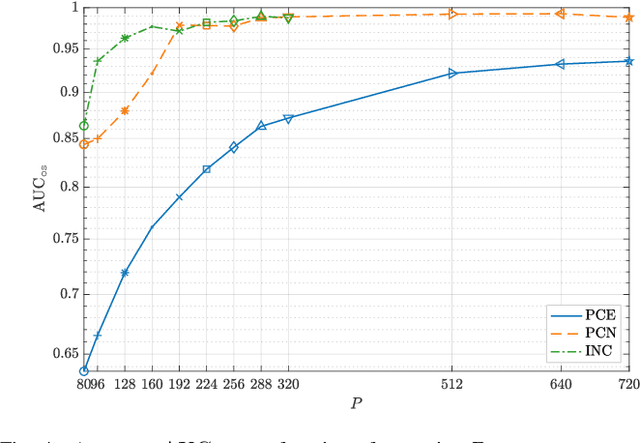
An In-Depth Study on Open-Set Camera Model Identification
Apr 11, 2019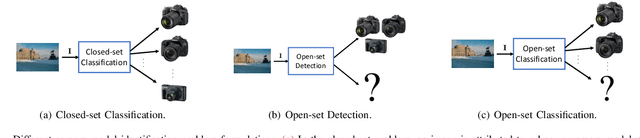
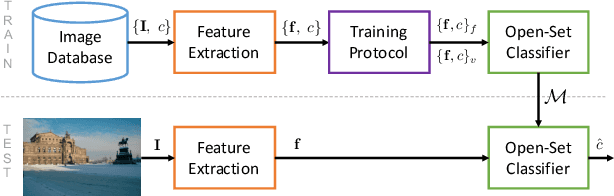
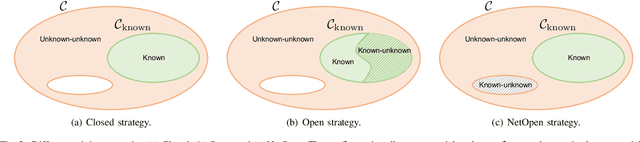
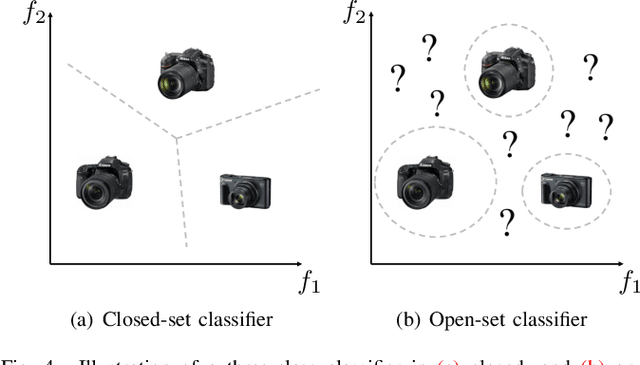
Camera model identification refers to the problem of linking a picture to the camera model used to shoot it. As this might be an enabling factor in different forensic applications to single out possible suspects (e.g., detecting the author of child abuse or terrorist propaganda material), many accurate camera model attribution methods have been developed in the literature. One of their main drawbacks, however, is the typical closed-set assumption of the problem. This means that an investigated photograph is always assigned to one camera model within a set of known ones present during investigation, i.e., training time, and the fact that the picture can come from a completely unrelated camera model during actual testing is usually ignored. Under realistic conditions, it is not possible to assume that every picture under analysis belongs to one of the available camera models. To deal with this issue, in this paper, we present the first in-depth study on the possibility of solving the camera model identification problem in open-set scenarios. Given a photograph, we aim at detecting whether it comes from one of the known camera models of interest or from an unknown device. We compare different feature extraction algorithms and classifiers specially targeting open-set recognition. We also evaluate possible open-set training protocols that can be applied along with any open-set classifier. More specifically, we evaluate one training protocol targeted for open-set classifiers with deep features. We observe that a simpler version of those training protocols works with similar results to the one that requires extra data, which can be useful in many applications in which deep features are employed. Thorough testing on independent datasets shows that it is possible to leverage a recently proposed convolutional neural network as feature extractor paired with a properly trained open-set classifier...
Interpolation and Denoising of Seismic Data using Convolutional Neural Networks
Jan 23, 2019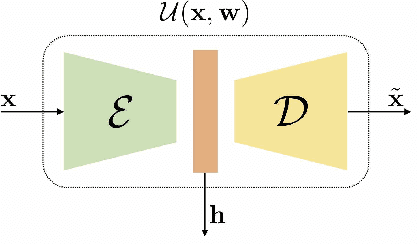


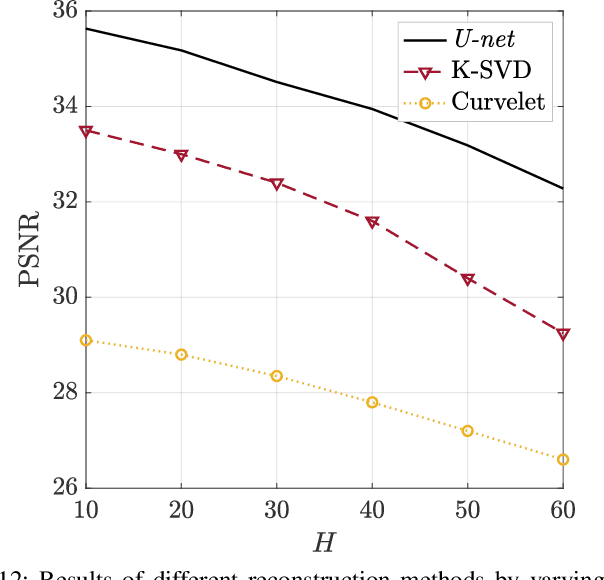
Seismic data processing algorithms greatly benefit, or even require regularly sampled and reliable data. Therefore, interpolation and denoising play a fundamental role as starting steps of most seismic data processing pipelines. In this paper, we exploit convolutional neural networks for the joint tasks of interpolation and random noise attenuation of 2D common shot gathers. Inspired by the great contributions achieved in image processing and computer vision, we investigate a particular architecture of convolutional neural network known as U-net, which implements a convolutional autoencoder able to describe the complex features of clean and regularly sampled data for reconstructing the corrupted ones. In training phase we exploit part of the data for tailoring the network to the specific tasks of interpolation, denoising and joint denoising/interpolation, while during the system deployment we are able to retrieve the remaining corrupted shot gathers in a computationally efficient procedure. In our experimental campaign, we consider a plurality of data corruptions, including different noise models and missing traces' distributions. We illustrate the advantages of the aforementioned strategy through several examples on synthetic and field data. Moreover, we compare the proposed denoising and interpolation technique to a recent state-of-the-art method.