 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Future: GNN-based NO$_2$ Forecasting via Future Covariates
Apr 08, 2024Due to the latest environmental concerns in keeping at bay contaminants emissions in urban areas, air pollution forecasting has been rising the forefront of all researchers around the world. When predicting pollutant concentrations, it is common to include the effects of environmental factors that influence these concentrations within an extended period, like traffic, meteorological conditions and geographical information. Most of the existing approaches exploit this information as past covariates, i.e., past exogenous variables that affected the pollutant but were not affected by it. In this paper, we present a novel forecasting methodology to predict NO$_2$ concentration via both past and future covariates. Future covariates are represented by weather forecasts and future calendar events, which are already known at prediction time. In particular, we deal with air quality observations in a city-wide network of ground monitoring stations, modeling the data structure and estimating the predictions with a Spatiotemporal Graph Neural Network (STGNN). We propose a conditioning block that embeds past and future covariates into the current observations. After extracting meaningful spatiotemporal representations, these are fused together and projected into the forecasting horizon to generate the final prediction. To the best of our knowledge, it is the first time that future covariates are included in time series predictions in a structured way. Remarkably, we find that conditioning on future weather information has a greater impact than considering past traffic conditions. We release our code implementation at https://github.com/polimi-ispl/MAGCRN.
Compression Robust Synthetic Speech Detection Using Patched Spectrogram Transformer
Feb 22, 2024



Many deep learning synthetic speech generation tools are readily available. The use of synthetic speech has caused financial fraud, impersonation of people, and misinformation to spread. For this reason forensic methods that can detect synthetic speech have been proposed. Existing methods often overfit on one dataset and their performance reduces substantially in practical scenarios such as detecting synthetic speech shared on social platforms. In this paper we propose, Patched Spectrogram Synthetic Speech Detection Transformer (PS3DT), a synthetic speech detector that converts a time domain speech signal to a mel-spectrogram and processes it in patches using a transformer neural network. We evaluate the detection performance of PS3DT on ASVspoof2019 dataset. Our experiments show that PS3DT performs well on ASVspoof2019 dataset compared to other approaches using spectrogram for synthetic speech detection. We also investigate generalization performance of PS3DT on In-the-Wild dataset. PS3DT generalizes well than several existing methods on detecting synthetic speech from an out-of-distribution dataset. We also evaluate robustness of PS3DT to detect telephone quality synthetic speech and synthetic speech shared on social platforms (compressed speech). PS3DT is robust to compression and can detect telephone quality synthetic speech better than several existing methods.
Listening Between the Lines: Synthetic Speech Detection Disregarding Verbal Content
Feb 08, 2024Recent advancements in synthetic speech generation have led to the creation of forged audio data that are almost indistinguishable from real speech. This phenomenon poses a new challenge for the multimedia forensics community, as the misuse of synthetic media can potentially cause adverse consequences. Several methods have been proposed in the literature to mitigate potential risks and detect synthetic speech, mainly focusing on the analysis of the speech itself. However, recent studies have revealed that the most crucial frequency bands for detection lie in the highest ranges (above 6000 Hz), which do not include any speech content. In this work, we extensively explore this aspect and investigate whether synthetic speech detection can be performed by focusing only on the background component of the signal while disregarding its verbal content. Our findings indicate that the speech component is not the predominant factor in performing synthetic speech detection. These insights provide valuable guidance for the development of new synthetic speech detectors and their interpretability, together with some considerations on the existing work in the audio forensics field.
Super-Resolution of BVOC Emission Maps Via Domain Adaptation
Jun 22, 2023



Enhancing the resolution of Biogenic Volatile Organic Compound (BVOC) emission maps is a critical task in remote sensing. Recently, some Super-Resolution (SR) methods based on Deep Learning (DL) have been proposed, leveraging data from numerical simulations for their training process. However, when dealing with data derived from satellite observations, the reconstruction is particularly challenging due to the scarcity of measurements to train SR algorithms with. In our work, we aim at super-resolving low resolution emission maps derived from satellite observations by leveraging the information of emission maps obtained through numerical simulations. To do this, we combine a SR method based on DL with Domain Adaptation (DA) techniques, harmonizing the different aggregation strategies and spatial information used in simulated and observed domains to ensure compatibility. We investigate the effectiveness of DA strategies at different stages by systematically varying the number of simulated and observed emissions used, exploring the implications of data scarcity on the adaptation strategies. To the best of our knowledge, there are no prior investigations of DA in satellite-derived BVOC maps enhancement. Our work represents a first step toward the development of robust strategies for the reconstruction of observed BVOC emissions.
Multi-BVOC Super-Resolution Exploiting Compounds Inter-Connection
May 23, 2023Biogenic Volatile Organic Compounds (BVOCs) emitted from the terrestrial ecosystem into the Earth's atmosphere are an important component of atmospheric chemistry. Due to the scarcity of measurement, a reliable enhancement of BVOCs emission maps can aid in providing denser data for atmospheric chemical, climate, and air quality models. In this work, we propose a strategy to super-resolve coarse BVOC emission maps by simultaneously exploiting the contributions of different compounds. To this purpose, we first accurately investigate the spatial inter-connections between several BVOC species. Then, we exploit the found similarities to build a Multi-Image Super-Resolution (MISR) system, in which a number of emission maps associated with diverse compounds are aggregated to boost Super-Resolution (SR) performance. We compare different configurations regarding the species and the number of joined BVOCs. Our experimental results show that incorporating BVOCs' relationship into the process can substantially improve the accuracy of the super-resolved maps. Interestingly, the best results are achieved when we aggregate the emission maps of strongly uncorrelated compounds. This peculiarity seems to confirm what was already guessed for other data-domains, i.e., joined uncorrelated information are more helpful than correlated ones to boost MISR performance. Nonetheless, the proposed work represents the first attempt in SR of BVOC emissions through the fusion of multiple different compounds.
DSVAE: Interpretable Disentangled Representation for Synthetic Speech Detection
Apr 06, 2023Tools to generate high quality synthetic speech signal that is perceptually indistinguishable from speech recorded from human speakers are easily available. Several approaches have been proposed for detecting synthetic speech. Many of these approaches use deep learning methods as a black box without providing reasoning for the decisions they make. This limits the interpretability of these approaches. In this paper, we propose Disentangled Spectrogram Variational Auto Encoder (DSVAE) which is a two staged trained variational autoencoder that processes spectrograms of speech using disentangled representation learning to generate interpretable representations of a speech signal for detecting synthetic speech. DSVAE also creates an activation map to highlight the spectrogram regions that discriminate synthetic and bona fide human speech signals. We evaluated the representations obtained from DSVAE using the ASVspoof2019 dataset. Our experimental results show high accuracy (>98%) on detecting synthetic speech from 6 known and 10 out of 11 unknown speech synthesizers. We also visualize the representation obtained from DSVAE for 17 different speech synthesizers and verify that they are indeed interpretable and discriminate bona fide and synthetic speech from each of the synthesizers.
Enhancing Biogenic Emission Maps Using Deep Learning
Feb 15, 2023Biogenic Volatile Organic Compounds (BVOCs) play a critical role in biosphere-atmosphere interactions, being a key factor in the physical and chemical properties of the atmosphere and climate. Acquiring large and fine-grained BVOC emission maps is expensive and time-consuming, so most of the available BVOC data are obtained on a loose and sparse sampling grid or on small regions. However, high-resolution BVOC data are desirable in many applications, such as air quality, atmospheric chemistry, and climate monitoring. In this work, we propose to investigate the possibility of enhancing BVOC acquisitions, taking a step forward in explaining the relationships between plants and these compounds. We do so by comparing the performances of several state-of-the-art neural networks proposed for Single-Image Super-Resolution (SISR), showing how to adapt them to correctly handle emission data through preprocessing. Moreover, we also consider realistic scenarios, considering both temporal and geographical constraints. Finally, we present possible future developments in terms of Super-Resolution (SR) generalization, considering the scale-invariance property and super-resolving emissions from unseen compounds.
Combining Automatic Speaker Verification and Prosody Analysis for Synthetic Speech Detection
Oct 31, 2022The rapid spread of media content synthesis technology and the potentially damaging impact of audio and video deepfakes on people's lives have raised the need to implement systems able to detect these forgeries automatically. In this work we present a novel approach for synthetic speech detection, exploiting the combination of two high-level semantic properties of the human voice. On one side, we focus on speaker identity cues and represent them as speaker embeddings extracted using a state-of-the-art method for the automatic speaker verification task. On the other side, voice prosody, intended as variations in rhythm, pitch or accent in speech, is extracted through a specialized encoder. We show that the combination of these two embeddings fed to a supervised binary classifier allows the detection of deepfake speech generated with both Text-to-Speech and Voice Conversion techniques. Our results show improvements over the considered baselines, good generalization properties over multiple datasets and robustness to audio compression.
An Overview on the Generation and Detection of Synthetic and Manipulated Satellite Images
Sep 19, 2022
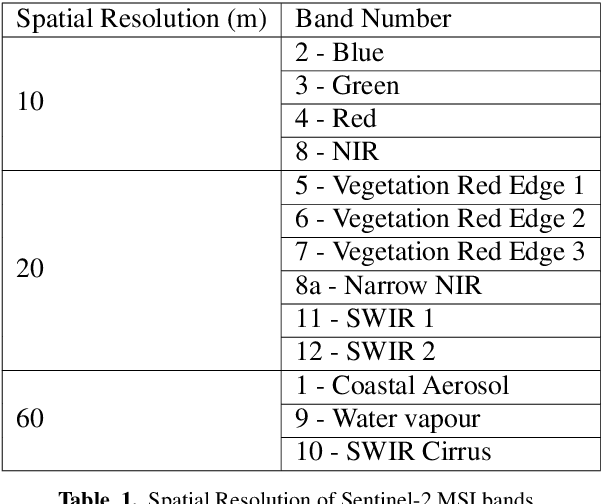
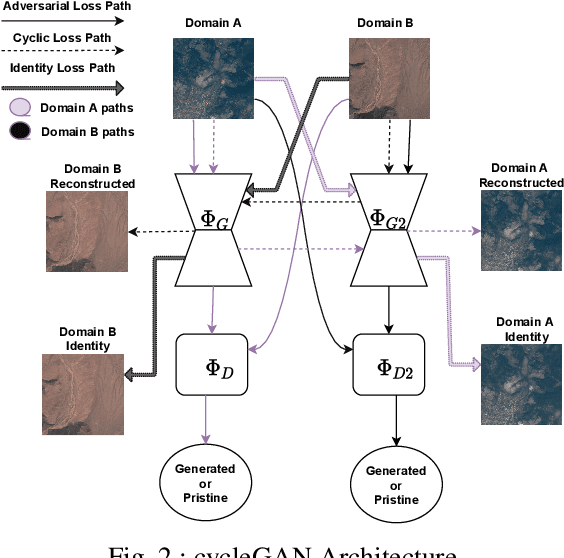
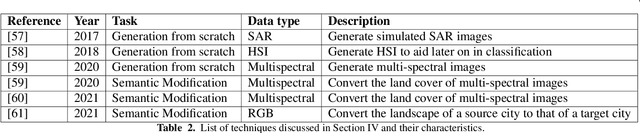
Due to the reduction of technological costs and the increase of satellites launches, satellite images are becoming more popular and easier to obtain. Besides serving benevolent purposes, satellite data can also be used for malicious reasons such as misinformation. As a matter of fact, satellite images can be easily manipulated relying on general image editing tools. Moreover, with the surge of Deep Neural Networks (DNNs) that can generate realistic synthetic imagery belonging to various domains, additional threats related to the diffusion of synthetically generated satellite images are emerging. In this paper, we review the State of the Art (SOTA) on the generation and manipulation of satellite images. In particular, we focus on both the generation of synthetic satellite imagery from scratch, and the semantic manipulation of satellite images by means of image-transfer technologies, including the transformation of images obtained from one type of sensor to another one. We also describe forensic detection techniques that have been researched so far to classify and detect synthetic image forgeries. While we focus mostly on forensic techniques explicitly tailored to the detection of AI-generated synthetic contents, we also review some methods designed for general splicing detection, which can in principle also be used to spot AI manipulate images
Speaker-Independent Microphone Identification in Noisy Conditions
Jun 23, 2022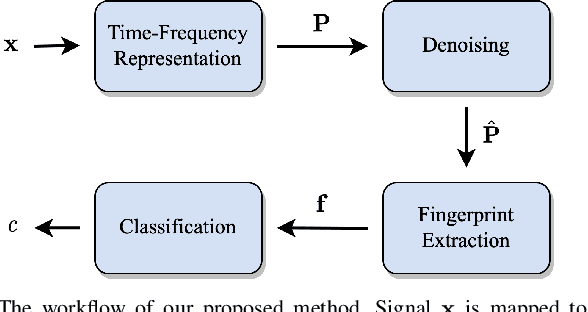
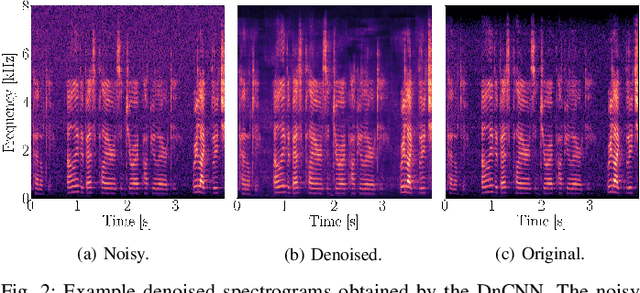
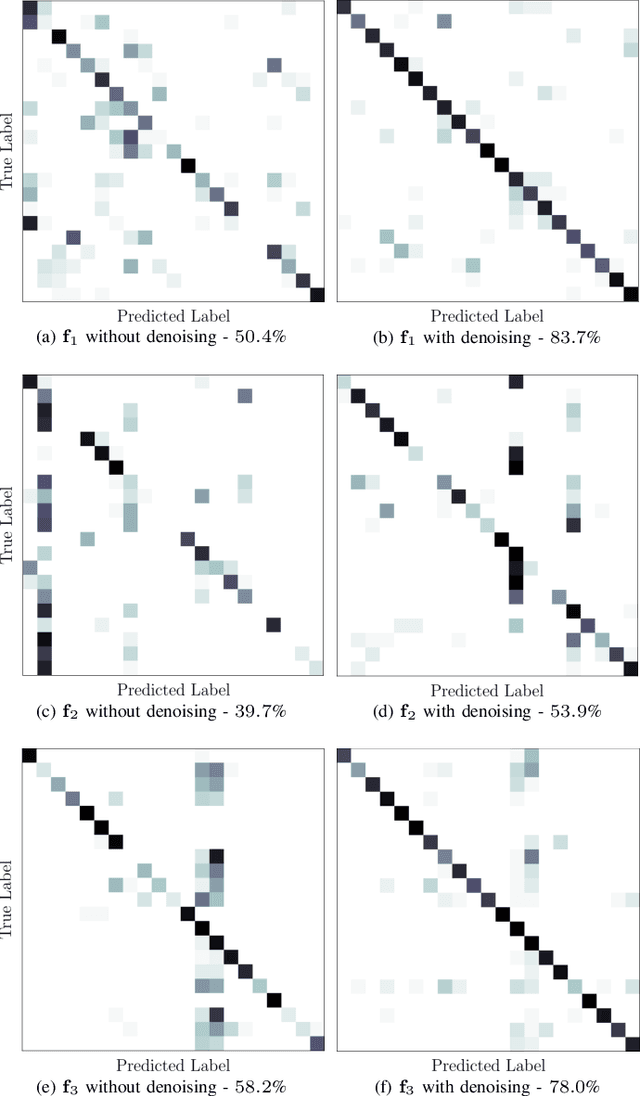
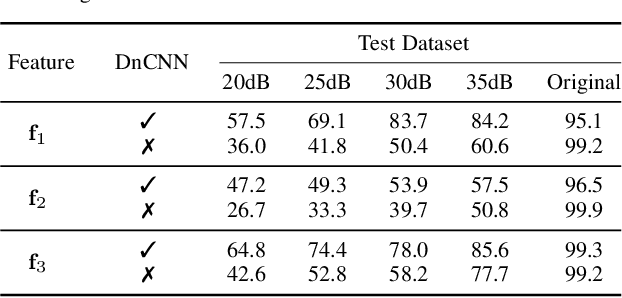
This work proposes a method for source device identification from speech recordings that applies neural-network-based denoising, to mitigate the impact of counter-forensics attacks using noise injection. The method is evaluated by comparing the impact of denoising on three state-of-the-art features for microphone classification, determining their discriminating power with and without denoising being applied. The proposed framework achieves a significant performance increase for noisy material, and more generally, validates the usefulness of applying denoising prior to device identification for noisy recordings.