 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Resampling-Based Framework for Network Structure Learning in High-Dimensional Data
May 12, 2026RSNet is an open-source R package that provides a resampling-based framework for robust and interpretable network inference, designed to address the limited-sample-size challenges common in high-dimensional data. It supports both the estimation of partial correlation networks modeled as Gaussian networks and conditional Gaussian Bayesian networks for mixed data types that combine continuous and discrete variables. The framework incorporates multiple resampling strategies, including bootstrap, subsampling, and cluster-based approaches, to accommodate both independent and correlated observations. To enhance interpretability, RSNet integrates graphlet-based topology analysis that captures higher-order connectivity and edge sign information, enabling single-node and subnetwork-level insights. Notably, RSNet is the first R package to efficiently construct signed graphlet degree vector matrices (GDVMs) in near-constant time for sparse networks, providing scalable analysis of higher-order network structure. Collectively, RSNet offers a versatile tool for statistically reliable and interpretable network inference in high-dimensional data.
A Multivariate Discretization Method for Learning Bayesian Networks from Mixed Data
Jan 30, 2013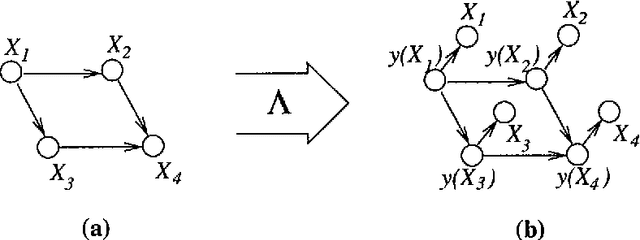
In this paper we address the problem of discretization in the context of learning Bayesian networks (BNs) from data containing both continuous and discrete variables. We describe a new technique for <EM>multivariate</EM> discretization, whereby each continuous variable is discretized while taking into account its interaction with the other variables. The technique is based on the use of a Bayesian scoring metric that scores the discretization policy for a continuous variable given a BN structure and the observed data. Since the metric is relative to the BN structure currently being evaluated, the discretization of a variable needs to be dynamically adjusted as the BN structure changes.
A Bayesian Network Classifier that Combines a Finite Mixture Model and a Naive Bayes Model
Jan 23, 2013
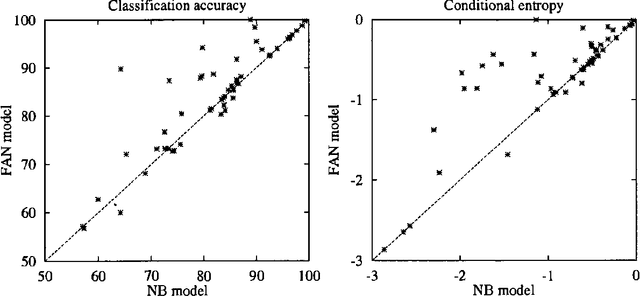
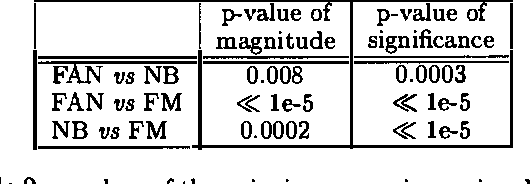
In this paper we present a new Bayesian network model for classification that combines the naive-Bayes (NB) classifier and the finite-mixture (FM) classifier. The resulting classifier aims at relaxing the strong assumptions on which the two component models are based, in an attempt to improve on their classification performance, both in terms of accuracy and in terms of calibration of the estimated probabilities. The proposed classifier is obtained by superimposing a finite mixture model on the set of feature variables of a naive Bayes model. We present experimental results that compare the predictive performance on real datasets of the new classifier with the predictive performance of the NB classifier and the FM classifier.