 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Image Captioning with Grounded Style
May 03, 2022
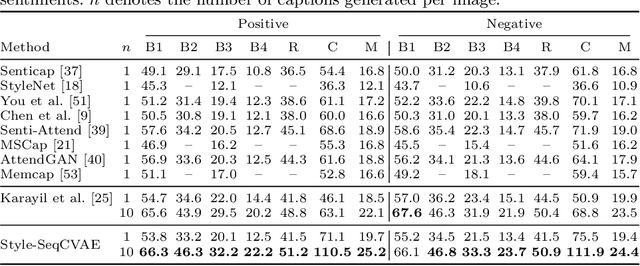
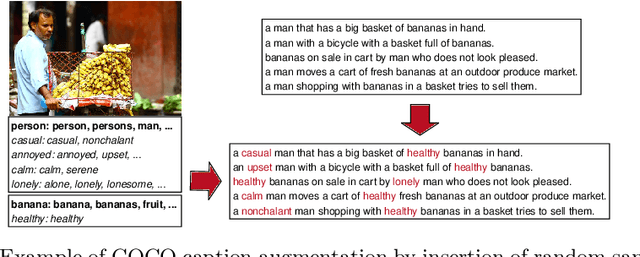
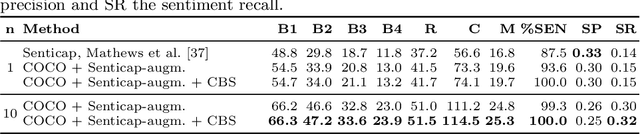
Stylized image captioning as presented in prior work aims to generate captions that reflect characteristics beyond a factual description of the scene composition, such as sentiments. Such prior work relies on given sentiment identifiers, which are used to express a certain global style in the caption, e.g. positive or negative, however without taking into account the stylistic content of the visual scene. To address this shortcoming, we first analyze the limitations of current stylized captioning datasets and propose COCO attribute-based augmentations to obtain varied stylized captions from COCO annotations. Furthermore, we encode the stylized information in the latent space of a Variational Autoencoder; specifically, we leverage extracted image attributes to explicitly structure its sequential latent space according to different localized style characteristics. Our experiments on the Senticap and COCO datasets show the ability of our approach to generate accurate captions with diversity in styles that are grounded in the image.
* In the 43rd DAGM German Conference on Pattern Recognition (GCPR) 2021
Fast Axiomatic Attribution for Neural Networks
Nov 15, 2021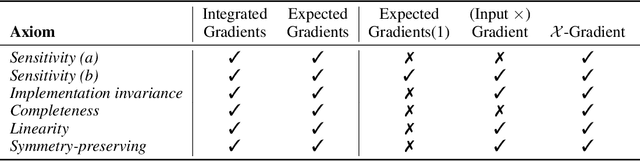
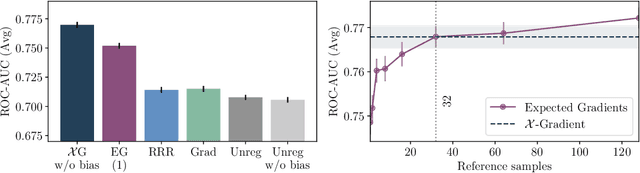


Mitigating the dependence on spurious correlations present in the training dataset is a quickly emerging and important topic of deep learning. Recent approaches include priors on the feature attribution of a deep neural network (DNN) into the training process to reduce the dependence on unwanted features. However, until now one needed to trade off high-quality attributions, satisfying desirable axioms, against the time required to compute them. This in turn either led to long training times or ineffective attribution priors. In this work, we break this trade-off by considering a special class of efficiently axiomatically attributable DNNs for which an axiomatic feature attribution can be computed with only a single forward/backward pass. We formally prove that nonnegatively homogeneous DNNs, here termed $\mathcal{X}$-DNNs, are efficiently axiomatically attributable and show that they can be effortlessly constructed from a wide range of regular DNNs by simply removing the bias term of each layer. Various experiments demonstrate the advantages of $\mathcal{X}$-DNNs, beating state-of-the-art generic attribution methods on regular DNNs for training with attribution priors.
Dense Unsupervised Learning for Video Segmentation
Nov 11, 2021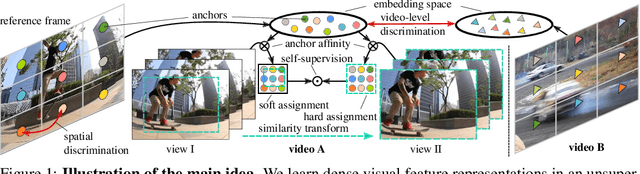
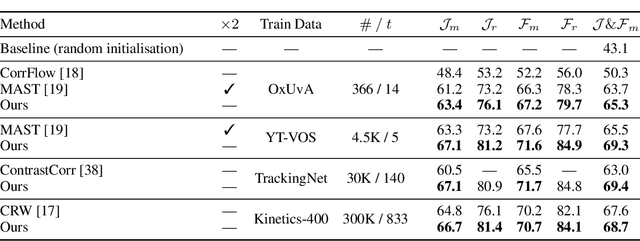
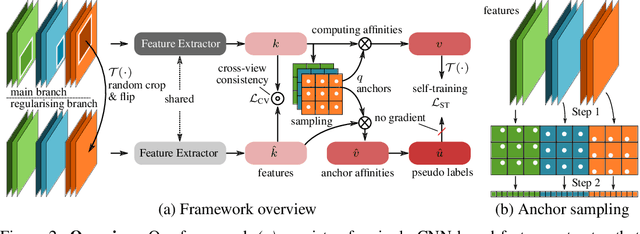
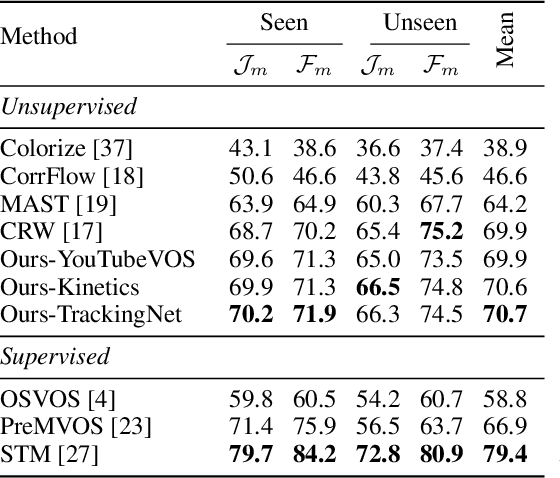
We present a novel approach to unsupervised learning for video object segmentation (VOS). Unlike previous work, our formulation allows to learn dense feature representations directly in a fully convolutional regime. We rely on uniform grid sampling to extract a set of anchors and train our model to disambiguate between them on both inter- and intra-video levels. However, a naive scheme to train such a model results in a degenerate solution. We propose to prevent this with a simple regularisation scheme, accommodating the equivariance property of the segmentation task to similarity transformations. Our training objective admits efficient implementation and exhibits fast training convergence. On established VOS benchmarks, our approach exceeds the segmentation accuracy of previous work despite using significantly less training data and compute power.
PixelPyramids: Exact Inference Models from Lossless Image Pyramids
Oct 17, 2021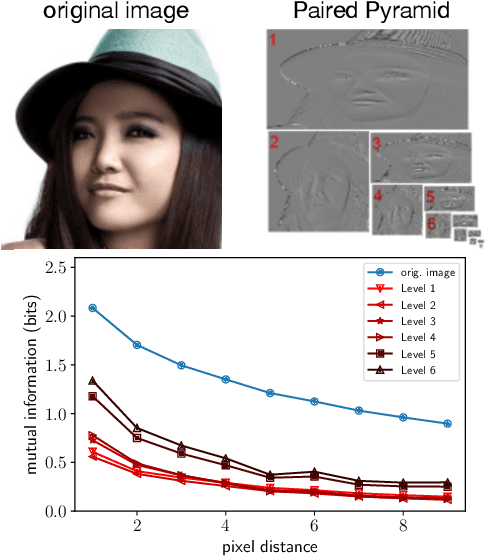
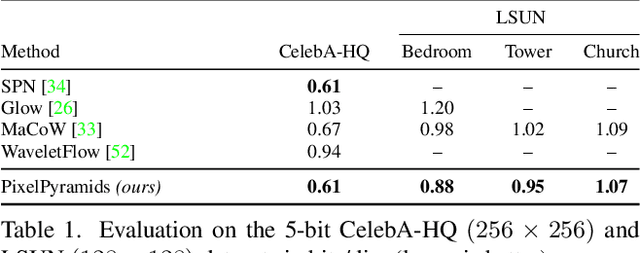
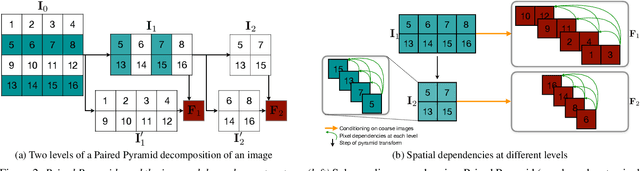

Autoregressive models are a class of exact inference approaches with highly flexible functional forms, yielding state-of-the-art density estimates for natural images. Yet, the sequential ordering on the dimensions makes these models computationally expensive and limits their applicability to low-resolution imagery. In this work, we propose Pixel-Pyramids, a block-autoregressive approach employing a lossless pyramid decomposition with scale-specific representations to encode the joint distribution of image pixels. Crucially, it affords a sparser dependency structure compared to fully autoregressive approaches. Our PixelPyramids yield state-of-the-art results for density estimation on various image datasets, especially for high-resolution data. For CelebA-HQ 1024 x 1024, we observe that the density estimates (in terms of bits/dim) are improved to ~44% of the baseline despite sampling speeds superior even to easily parallelizable flow-based models.
xGQA: Cross-Lingual Visual Question Answering
Sep 13, 2021
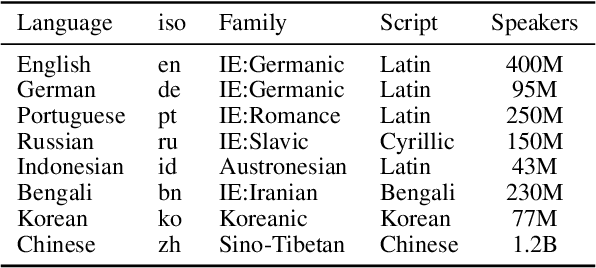

Recent advances in multimodal vision and language modeling have predominantly focused on the English language, mostly due to the lack of multilingual multimodal datasets to steer modeling efforts. In this work, we address this gap and provide xGQA, a new multilingual evaluation benchmark for the visual question answering task. We extend the established English GQA dataset to 7 typologically diverse languages, enabling us to detect and explore crucial challenges in cross-lingual visual question answering. We further propose new adapter-based approaches to adapt multimodal transformer-based models to become multilingual, and -- vice versa -- multilingual models to become multimodal. Our proposed methods outperform current state-of-the-art multilingual multimodal models (e.g., M3P) in zero-shot cross-lingual settings, but the accuracy remains low across the board; a performance drop of around 38 accuracy points in target languages showcases the difficulty of zero-shot cross-lingual transfer for this task. Our results suggest that simple cross-lingual transfer of multimodal models yields latent multilingual multimodal misalignment, calling for more sophisticated methods for vision and multilingual language modeling. The xGQA dataset is available online at: https://github.com/Adapter-Hub/xGQA.
TxT: Crossmodal End-to-End Learning with Transformers
Sep 09, 2021
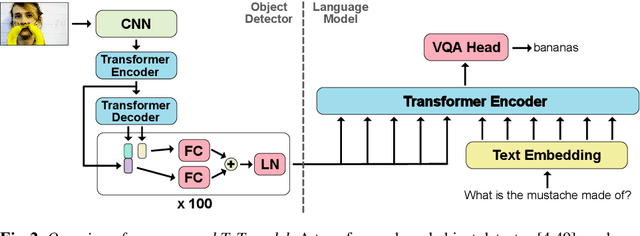

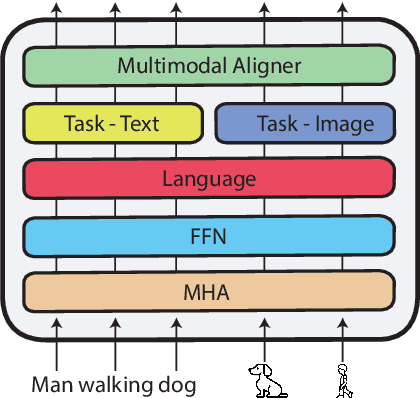
Reasoning over multiple modalities, e.g. in Visual Question Answering (VQA), requires an alignment of semantic concepts across domains. Despite the widespread success of end-to-end learning, today's multimodal pipelines by and large leverage pre-extracted, fixed features from object detectors, typically Faster R-CNN, as representations of the visual world. The obvious downside is that the visual representation is not specifically tuned to the multimodal task at hand. At the same time, while transformer-based object detectors have gained popularity, they have not been employed in today's multimodal pipelines. We address both shortcomings with TxT, a transformer-based crossmodal pipeline that enables fine-tuning both language and visual components on the downstream task in a fully end-to-end manner. We overcome existing limitations of transformer-based detectors for multimodal reasoning regarding the integration of global context and their scalability. Our transformer-based multimodal model achieves considerable gains from end-to-end learning for multimodal question answering.
Self-Supervised Multi-Frame Monocular Scene Flow
May 05, 2021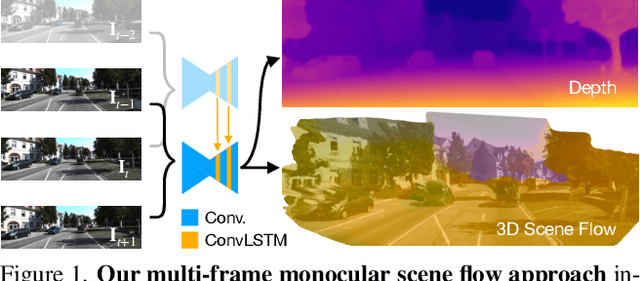

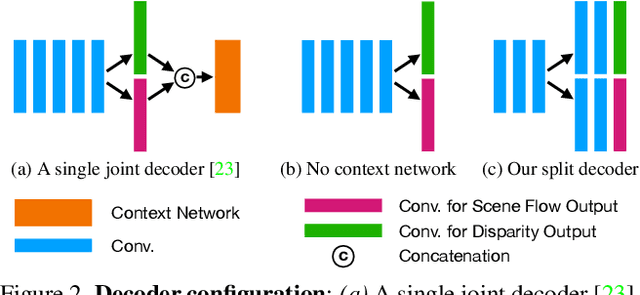
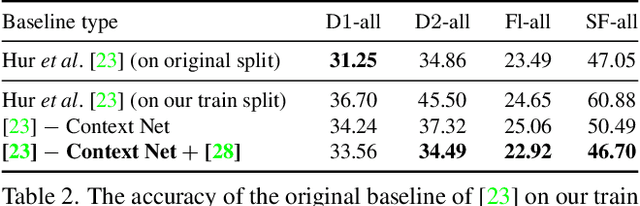
Estimating 3D scene flow from a sequence of monocular images has been gaining increased attention due to the simple, economical capture setup. Owing to the severe ill-posedness of the problem, the accuracy of current methods has been limited, especially that of efficient, real-time approaches. In this paper, we introduce a multi-frame monocular scene flow network based on self-supervised learning, improving the accuracy over previous networks while retaining real-time efficiency. Based on an advanced two-frame baseline with a split-decoder design, we propose (i) a multi-frame model using a triple frame input and convolutional LSTM connections, (ii) an occlusion-aware census loss for better accuracy, and (iii) a gradient detaching strategy to improve training stability. On the KITTI dataset, we observe state-of-the-art accuracy among monocular scene flow methods based on self-supervised learning.
Self-supervised Augmentation Consistency for Adapting Semantic Segmentation
Apr 30, 2021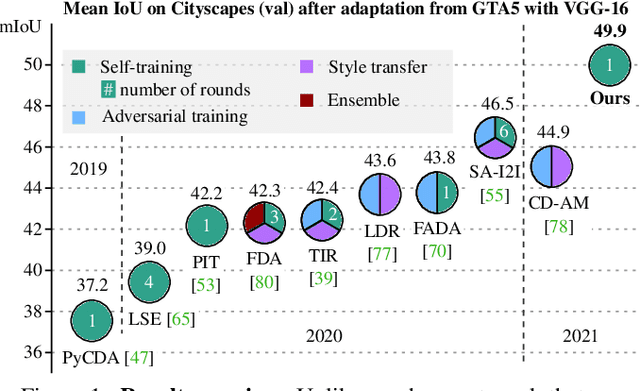


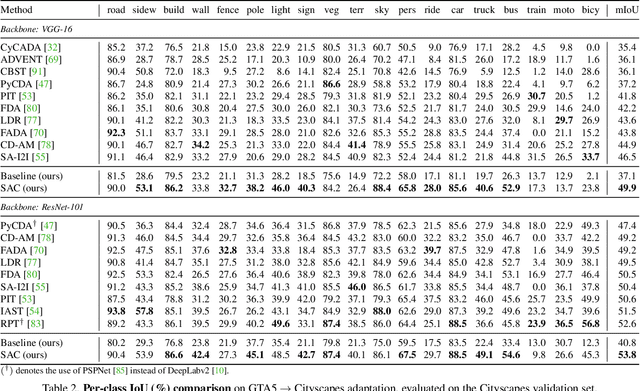
We propose an approach to domain adaptation for semantic segmentation that is both practical and highly accurate. In contrast to previous work, we abandon the use of computationally involved adversarial objectives, network ensembles and style transfer. Instead, we employ standard data augmentation techniques $-$ photometric noise, flipping and scaling $-$ and ensure consistency of the semantic predictions across these image transformations. We develop this principle in a lightweight self-supervised framework trained on co-evolving pseudo labels without the need for cumbersome extra training rounds. Simple in training from a practitioner's standpoint, our approach is remarkably effective. We achieve significant improvements of the state-of-the-art segmentation accuracy after adaptation, consistent both across different choices of the backbone architecture and adaptation scenarios.
Deep Wiener Deconvolution: Wiener Meets Deep Learning for Image Deblurring
Mar 18, 2021
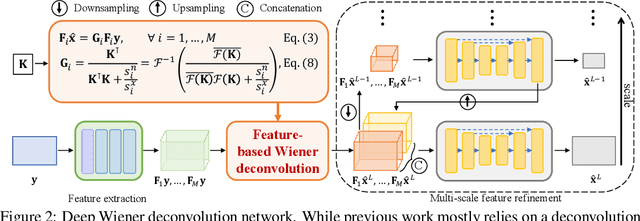
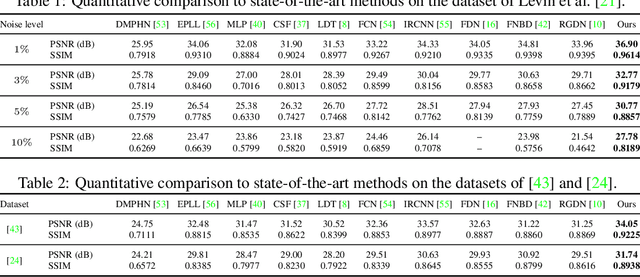

We present a simple and effective approach for non-blind image deblurring, combining classical techniques and deep learning. In contrast to existing methods that deblur the image directly in the standard image space, we propose to perform an explicit deconvolution process in a feature space by integrating a classical Wiener deconvolution framework with learned deep features. A multi-scale feature refinement module then predicts the deblurred image from the deconvolved deep features, progressively recovering detail and small-scale structures. The proposed model is trained in an end-to-end manner and evaluated on scenarios with both simulated and real-world image blur. Our extensive experimental results show that the proposed deep Wiener deconvolution network facilitates deblurred results with visibly fewer artifacts. Moreover, our approach quantitatively outperforms state-of-the-art non-blind image deblurring methods by a wide margin.
Sampling-free Variational Inference for Neural Networks with Multiplicative Activation Noise
Mar 16, 2021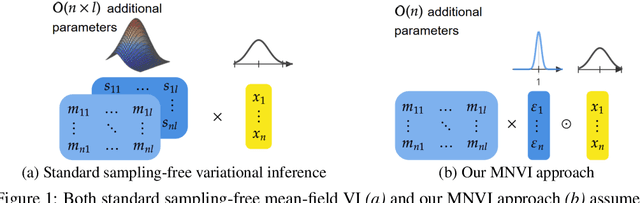

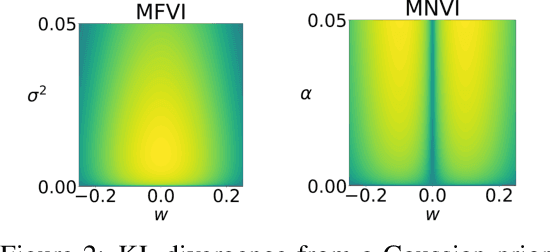
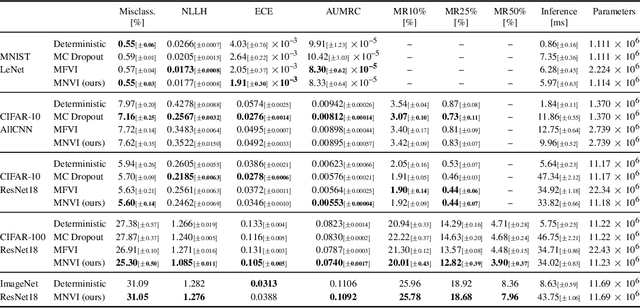
To adopt neural networks in safety critical domains, knowing whether we can trust their predictions is crucial. Bayesian neural networks (BNNs) provide uncertainty estimates by averaging predictions with respect to the posterior weight distribution. Variational inference methods for BNNs approximate the intractable weight posterior with a tractable distribution, yet mostly rely on sampling from the variational distribution during training and inference. Recent sampling-free approaches offer an alternative, but incur a significant parameter overhead. We here propose a more efficient parameterization of the posterior approximation for sampling-free variational inference that relies on the distribution induced by multiplicative Gaussian activation noise. This allows us to combine parameter efficiency with the benefits of sampling-free variational inference. Our approach yields competitive results for standard regression problems and scales well to large-scale image classification tasks including ImageNet.