 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn GNN explanability with activation rules
Jun 17, 2024



GNNs are powerful models based on node representation learning that perform particularly well in many machine learning problems related to graphs. The major obstacle to the deployment of GNNs is mostly a problem of societal acceptability and trustworthiness, properties which require making explicit the internal functioning of such models. Here, we propose to mine activation rules in the hidden layers to understand how the GNNs perceive the world. The problem is not to discover activation rules that are individually highly discriminating for an output of the model. Instead, the challenge is to provide a small set of rules that cover all input graphs. To this end, we introduce the subjective activation pattern domain. We define an effective and principled algorithm to enumerate activations rules in each hidden layer. The proposed approach for quantifying the interest of these rules is rooted in information theory and is able to account for background knowledge on the input graph data. The activation rules can then be redescribed thanks to pattern languages involving interpretable features. We show that the activation rules provide insights on the characteristics used by the GNN to classify the graphs. Especially, this allows to identify the hidden features built by the GNN through its different layers. Also, these rules can subsequently be used for explaining GNN decisions. Experiments on both synthetic and real-life datasets show highly competitive performance, with up to 200% improvement in fidelity on explaining graph classification over the SOTA methods.
Interpretable Summaries of Black Box Incident Triaging with Subgroup Discovery
Aug 06, 2021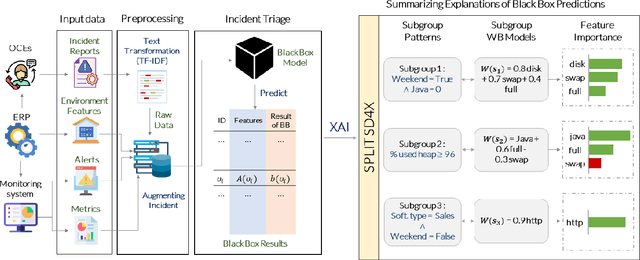
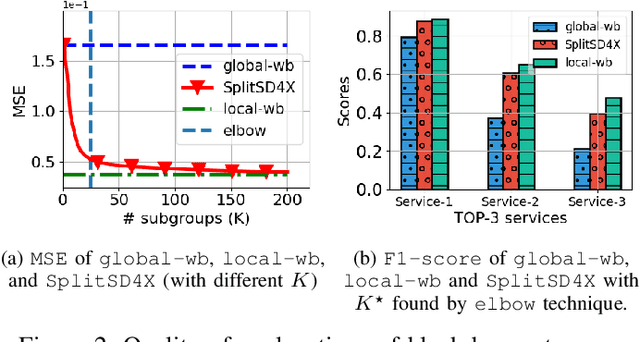
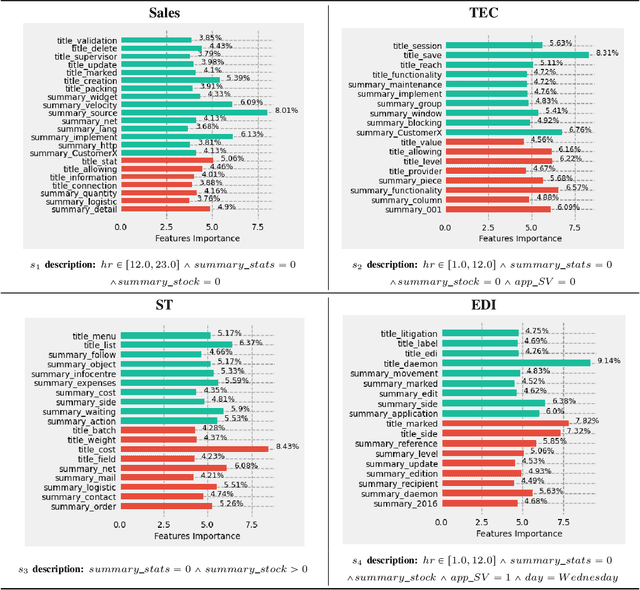
The need of predictive maintenance comes with an increasing number of incidents reported by monitoring systems and equipment/software users. In the front line, on-call engineers (OCEs) have to quickly assess the degree of severity of an incident and decide which service to contact for corrective actions. To automate these decisions, several predictive models have been proposed, but the most efficient models are opaque (say, black box), strongly limiting their adoption. In this paper, we propose an efficient black box model based on 170K incidents reported to our company over the last 7 years and emphasize on the need of automating triage when incidents are massively reported on thousands of servers running our product, an ERP. Recent developments in eXplainable Artificial Intelligence (XAI) help in providing global explanations to the model, but also, and most importantly, with local explanations for each model prediction/outcome. Sadly, providing a human with an explanation for each outcome is not conceivable when dealing with an important number of daily predictions. To address this problem, we propose an original data-mining method rooted in Subgroup Discovery, a pattern mining technique with the natural ability to group objects that share similar explanations of their black box predictions and provide a description for each group. We evaluate this approach and present our preliminary results which give us good hope towards an effective OCE's adoption. We believe that this approach provides a new way to address the problem of model agnostic outcome explanation.
Sequential recommendation with metric models based on frequent sequences
Aug 12, 2020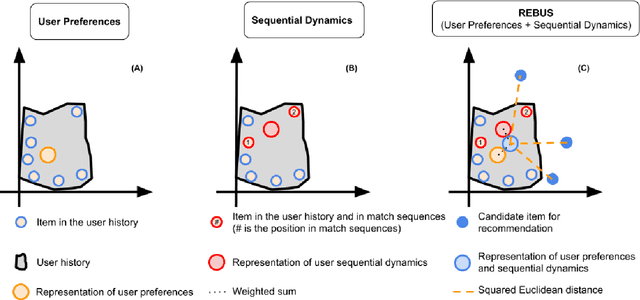

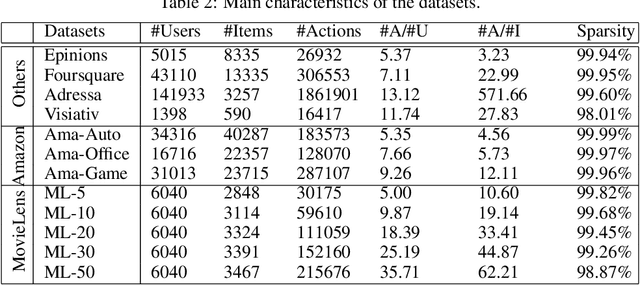
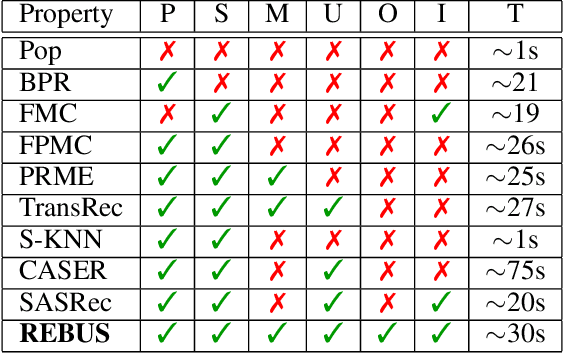
Modeling user preferences (long-term history) and user dynamics (short-term history) is of greatest importance to build efficient sequential recommender systems. The challenge lies in the successful combination of the whole user's history and his recent actions (sequential dynamics) to provide personalized recommendations. Existing methods capture the sequential dynamics of a user using fixed-order Markov chains (usually first order chains) regardless of the user, which limits both the impact of the past of the user on the recommendation and the ability to adapt its length to the user profile. In this article, we propose to use frequent sequences to identify the most relevant part of the user history for the recommendation. The most salient items are then used in a unified metric model that embeds items based on user preferences and sequential dynamics. Extensive experiments demonstrate that our method outperforms state-of-the-art, especially on sparse datasets. We show that considering sequences of varying lengths improves the recommendations and we also emphasize that these sequences provide explanations on the recommendation.