 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Paraphrases: The Impact of Prompt Syntax and supplementary Information on Knowledge Retrieval from Pretrained Language Models
Apr 02, 2024



Pre-trained Language Models (PLMs) are known to contain various kinds of knowledge. One method to infer relational knowledge is through the use of cloze-style prompts, where a model is tasked to predict missing subjects or objects. Typically, designing these prompts is a tedious task because small differences in syntax or semantics can have a substantial impact on knowledge retrieval performance. Simultaneously, evaluating the impact of either prompt syntax or information is challenging due to their interdependence. We designed CONPARE-LAMA - a dedicated probe, consisting of 34 million distinct prompts that facilitate comparison across minimal paraphrases. These paraphrases follow a unified meta-template enabling the controlled variation of syntax and semantics across arbitrary relations. CONPARE-LAMA enables insights into the independent impact of either syntactical form or semantic information of paraphrases on the knowledge retrieval performance of PLMs. Extensive knowledge retrieval experiments using our probe reveal that prompts following clausal syntax have several desirable properties in comparison to appositive syntax: i) they are more useful when querying PLMs with a combination of supplementary information, ii) knowledge is more consistently recalled across different combinations of supplementary information, and iii) they decrease response uncertainty when retrieving known facts. In addition, range information can boost knowledge retrieval performance more than domain information, even though domain information is more reliably helpful across syntactic forms.
TACO -- Twitter Arguments from COnversations
Mar 30, 2024



Twitter has emerged as a global hub for engaging in online conversations and as a research corpus for various disciplines that have recognized the significance of its user-generated content. Argument mining is an important analytical task for processing and understanding online discourse. Specifically, it aims to identify the structural elements of arguments, denoted as information and inference. These elements, however, are not static and may require context within the conversation they are in, yet there is a lack of data and annotation frameworks addressing this dynamic aspect on Twitter. We contribute TACO, the first dataset of Twitter Arguments utilizing 1,814 tweets covering 200 entire conversations spanning six heterogeneous topics annotated with an agreement of 0.718 Krippendorff's alpha among six experts. Second, we provide our annotation framework, incorporating definitions from the Cambridge Dictionary, to define and identify argument components on Twitter. Our transformer-based classifier achieves an 85.06\% macro F1 baseline score in detecting arguments. Moreover, our data reveals that Twitter users tend to engage in discussions involving informed inferences and information. TACO serves multiple purposes, such as training tweet classifiers to manage tweets based on inference and information elements, while also providing valuable insights into the conversational reply patterns of tweets.
nuScenes Knowledge Graph -- A comprehensive semantic representation of traffic scenes for trajectory prediction
Dec 15, 2023



Trajectory prediction in traffic scenes involves accurately forecasting the behaviour of surrounding vehicles. To achieve this objective it is crucial to consider contextual information, including the driving path of vehicles, road topology, lane dividers, and traffic rules. Although studies demonstrated the potential of leveraging heterogeneous context for improving trajectory prediction, state-of-the-art deep learning approaches still rely on a limited subset of this information. This is mainly due to the limited availability of comprehensive representations. This paper presents an approach that utilizes knowledge graphs to model the diverse entities and their semantic connections within traffic scenes. Further, we present nuScenes Knowledge Graph (nSKG), a knowledge graph for the nuScenes dataset, that models explicitly all scene participants and road elements, as well as their semantic and spatial relationships. To facilitate the usage of the nSKG via graph neural networks for trajectory prediction, we provide the data in a format, ready-to-use by the PyG library. All artefacts can be found here: https://github.com/boschresearch/nuScenes_Knowledge_Graph
GSAP-NER: A Novel Task, Corpus, and Baseline for Scholarly Entity Extraction Focused on Machine Learning Models and Datasets
Nov 16, 2023



Named Entity Recognition (NER) models play a crucial role in various NLP tasks, including information extraction (IE) and text understanding. In academic writing, references to machine learning models and datasets are fundamental components of various computer science publications and necessitate accurate models for identification. Despite the advancements in NER, existing ground truth datasets do not treat fine-grained types like ML model and model architecture as separate entity types, and consequently, baseline models cannot recognize them as such. In this paper, we release a corpus of 100 manually annotated full-text scientific publications and a first baseline model for 10 entity types centered around ML models and datasets. In order to provide a nuanced understanding of how ML models and datasets are mentioned and utilized, our dataset also contains annotations for informal mentions like "our BERT-based model" or "an image CNN". You can find the ground truth dataset and code to replicate model training at https://data.gesis.org/gsap/gsap-ner.
Large Language Models and Knowledge Graphs: Opportunities and Challenges
Aug 11, 2023Large Language Models (LLMs) have taken Knowledge Representation -- and the world -- by storm. This inflection point marks a shift from explicit knowledge representation to a renewed focus on the hybrid representation of both explicit knowledge and parametric knowledge. In this position paper, we will discuss some of the common debate points within the community on LLMs (parametric knowledge) and Knowledge Graphs (explicit knowledge) and speculate on opportunities and visions that the renewed focus brings, as well as related research topics and challenges.
Which Factors Drive Open Access Publishing? A Springer Nature Case Study
Aug 17, 2022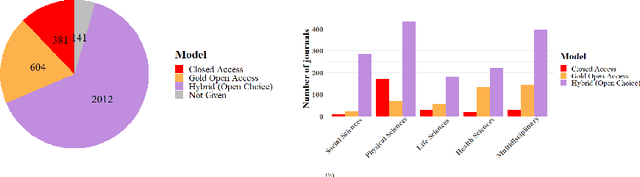
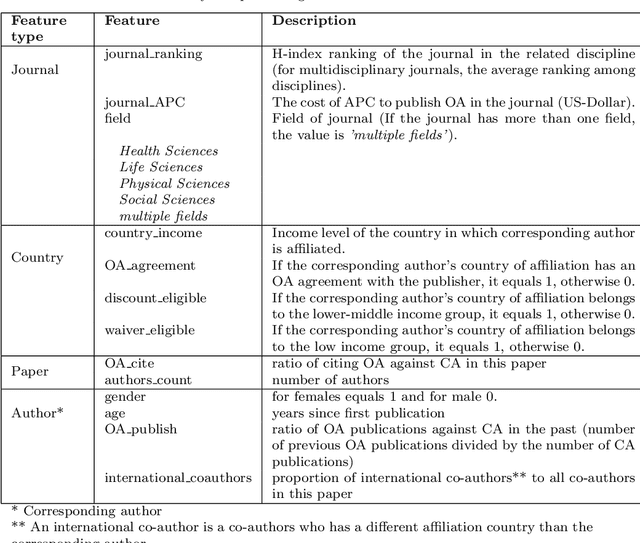
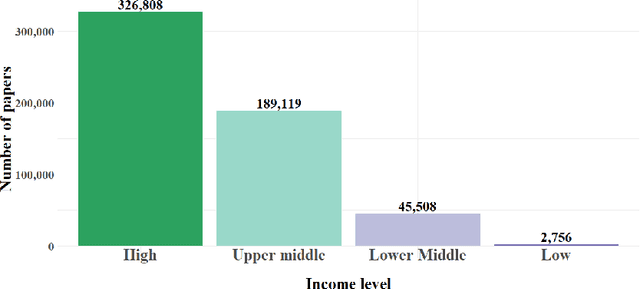
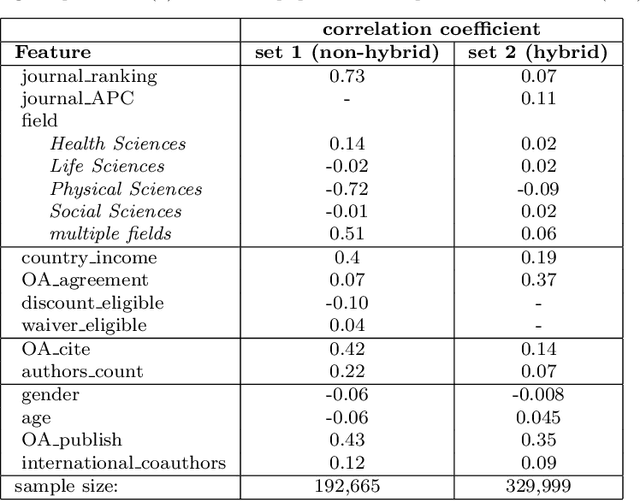
Open Access (OA) facilitates access to articles. But, authors or funders often must pay the publishing costs preventing authors who do not receive financial support from participating in OA publishing and citation advantage for OA articles. OA may exacerbate existing inequalities in the publication system rather than overcome them. To investigate this, we studied 522,664 articles published by Springer Nature. Employing statistical methods, we describe the relationship between authors affiliated with countries from different income levels, their choice of publishing (OA or closed access), and the citation impact of their papers. A machine learning classification method helped us to explore the association between OA-publishing and attributes of the author, especially eligibility for APC-waivers or discounts, journal, country, and paper. The results indicate that authors eligible for the APC-waivers publish more in gold-OA-journals than other authors. In contrast, authors eligible for an APC discount have the lowest ratio of OA publications, leading to the assumption that this discount insufficiently motivates authors to publish in a gold-OA-journal. The rank of journals is a significant driver for publishing in a gold-OA-journal, whereas the OA option is mostly avoided in hybrid journals. Seniority, experience with OA publications, and the scientific field are the most decisive factors in OA-publishing.
Still Haven't Found What You're Looking For -- Detecting the Intent of Web Search Missions from User Interaction Features
Jul 04, 2022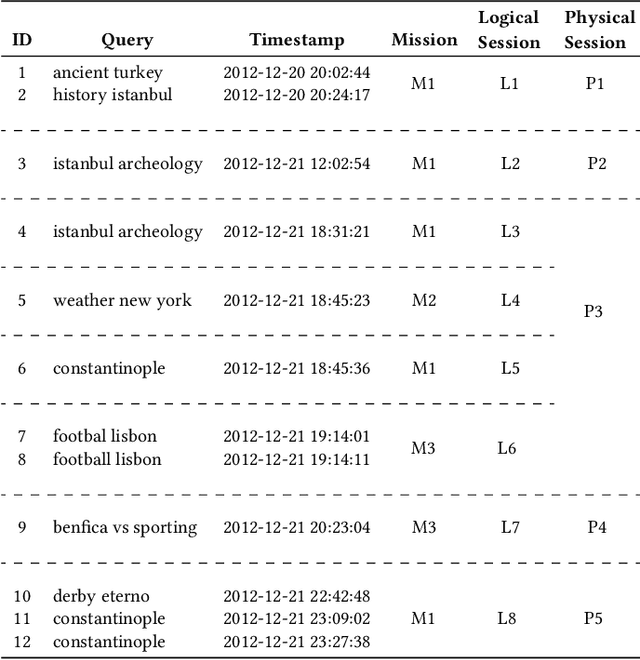
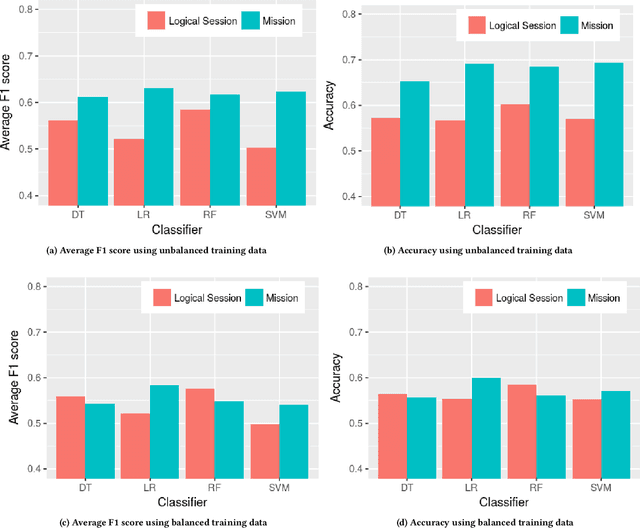
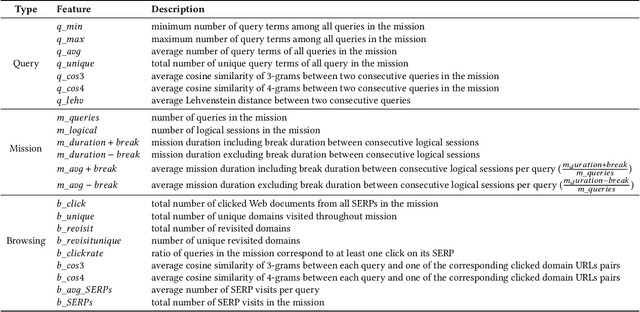
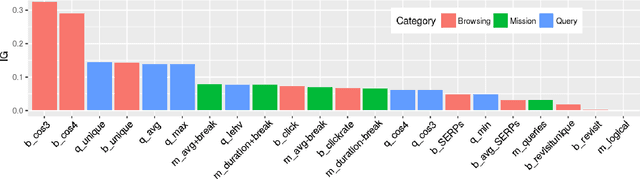
Web search is among the most frequent online activities. Whereas traditional information retrieval techniques focus on the information need behind a user query, previous work has shown that user behaviour and interaction can provide important signals for understanding the underlying intent of a search mission. An established taxonomy distinguishes between transactional, navigational and informational search missions, where in particular the latter involve a learning goal, i.e. the intent to acquire knowledge about a particular topic. We introduce a supervised approach for classifying online search missions into either of these categories by utilising a range of features obtained from the user interactions during an online search mission. Applying our model to a dataset of real-world query logs, we show that search missions can be categorised with an average F1 score of 63% and accuracy of 69%, while performance on informational and navigational missions is particularly promising (F1>75%). This suggests the potential to utilise such supervised classification during online search to better facilitate retrieval and ranking as well as to improve affiliated services, such as targeted online ads.
SciTweets -- A Dataset and Annotation Framework for Detecting Scientific Online Discourse
Jun 15, 2022
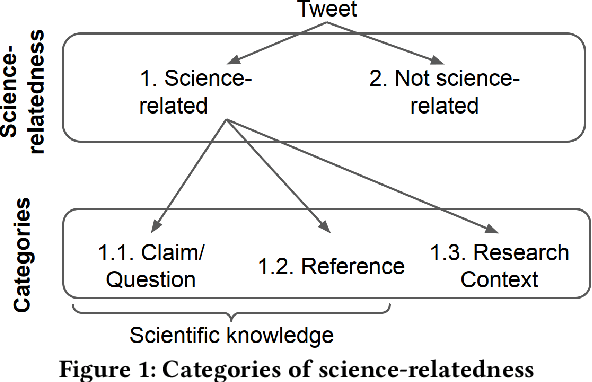
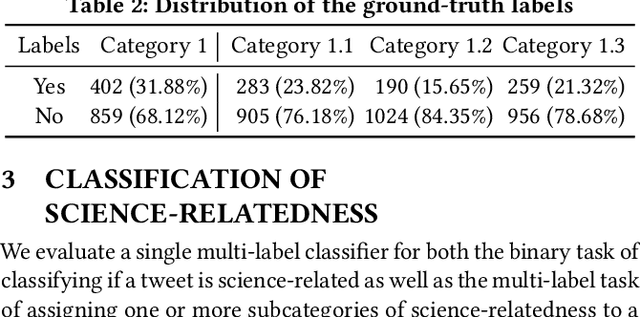
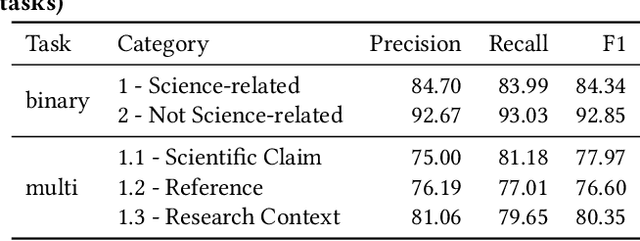
Scientific topics, claims and resources are increasingly debated as part of online discourse, where prominent examples include discourse related to COVID-19 or climate change. This has led to both significant societal impact and increased interest in scientific online discourse from various disciplines. For instance, communication studies aim at a deeper understanding of biases, quality or spreading pattern of scientific information whereas computational methods have been proposed to extract, classify or verify scientific claims using NLP and IR techniques. However, research across disciplines currently suffers from both a lack of robust definitions of the various forms of science-relatedness as well as appropriate ground truth data for distinguishing them. In this work, we contribute (a) an annotation framework and corresponding definitions for different forms of scientific relatedness of online discourse in Tweets, (b) an expert-annotated dataset of 1261 tweets obtained through our labeling framework reaching an average Fleiss Kappa $\kappa$ of 0.63, (c) a multi-label classifier trained on our data able to detect science-relatedness with 89% F1 and also able to detect distinct forms of scientific knowledge (claims, references). With this work we aim to lay the foundation for developing and evaluating robust methods for analysing science as part of large-scale online discourse.
SaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022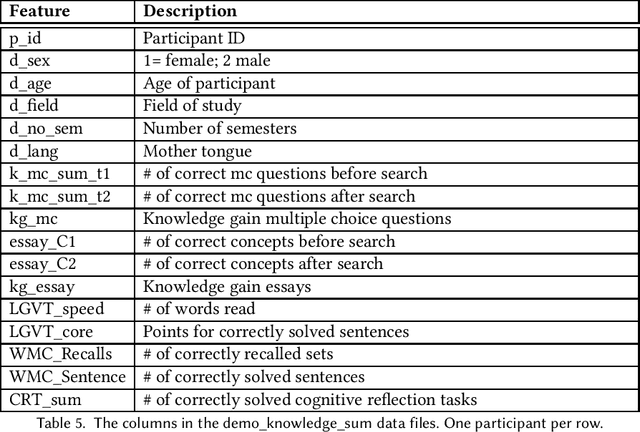
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.
SoMeSci- A 5 Star Open Data Gold Standard Knowledge Graph of Software Mentions in Scientific Articles
Aug 20, 2021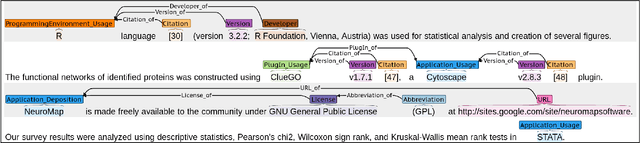
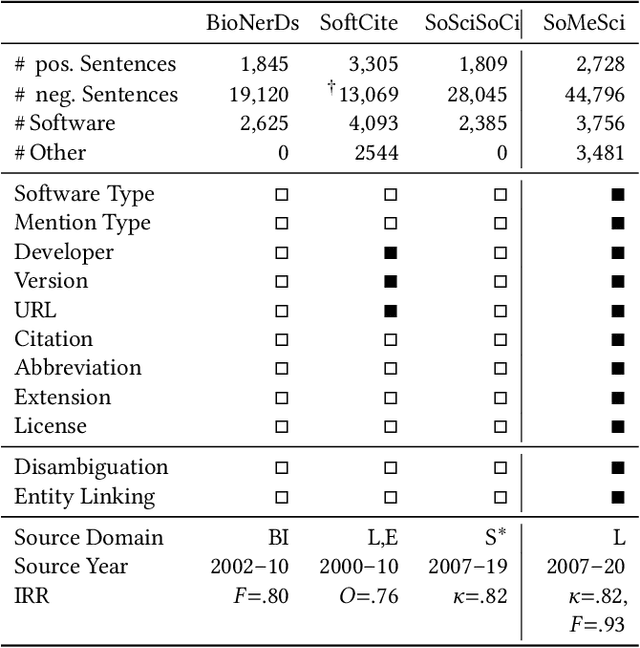
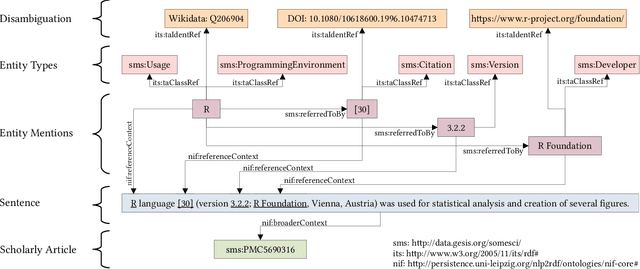
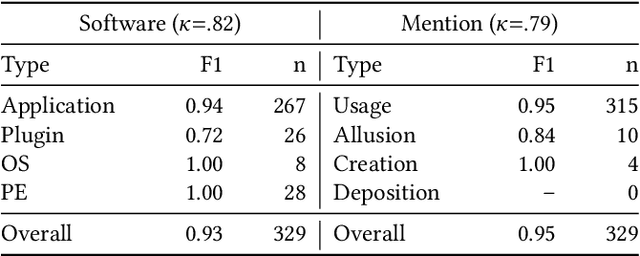
Knowledge about software used in scientific investigations is important for several reasons, for instance, to enable an understanding of provenance and methods involved in data handling. However, software is usually not formally cited, but rather mentioned informally within the scholarly description of the investigation, raising the need for automatic information extraction and disambiguation. Given the lack of reliable ground truth data, we present SoMeSci (Software Mentions in Science) a gold standard knowledge graph of software mentions in scientific articles. It contains high quality annotations (IRR: $\kappa{=}.82$) of 3756 software mentions in 1367 PubMed Central articles. Besides the plain mention of the software, we also provide relation labels for additional information, such as the version, the developer, a URL or citations. Moreover, we distinguish between different types, such as application, plugin or programming environment, as well as different types of mentions, such as usage or creation. To the best of our knowledge, SoMeSci is the most comprehensive corpus about software mentions in scientific articles, providing training samples for Named Entity Recognition, Relation Extraction, Entity Disambiguation, and Entity Linking. Finally, we sketch potential use cases and provide baseline results.