 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Ensembles: A Loss Landscape Perspective
Dec 05, 2019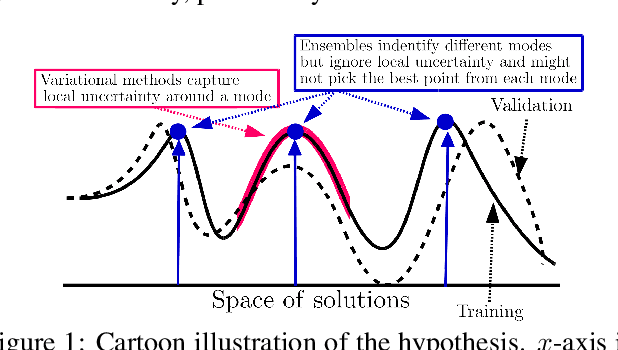
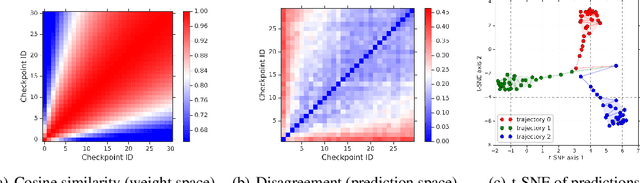
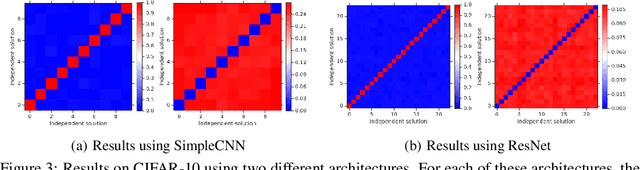
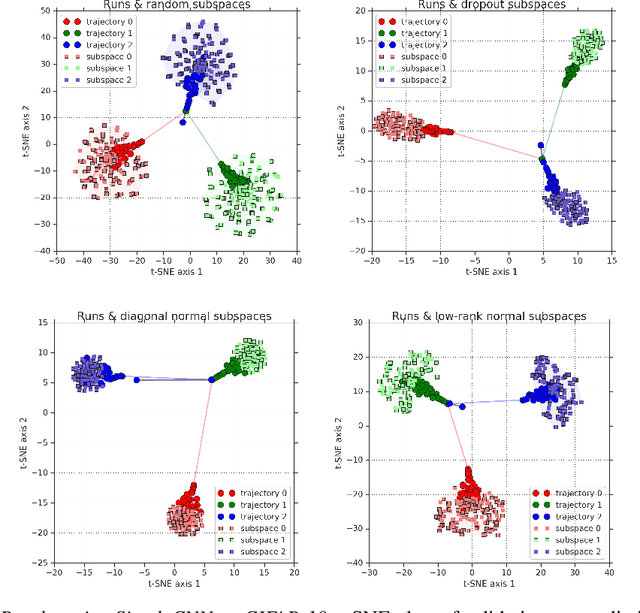
Deep ensembles have been empirically shown to be a promising approach for improving accuracy, uncertainty and out-of-distribution robustness of deep learning models. While deep ensembles were theoretically motivated by the bootstrap, non-bootstrap ensembles trained with just random initialization also perform well in practice, which suggests that there could be other explanations for why deep ensembles work well. Bayesian neural networks, which learn distributions over the parameters of the network, are theoretically well-motivated by Bayesian principles, but do not perform as well as deep ensembles in practice, particularly under dataset shift. One possible explanation for this gap between theory and practice is that popular scalable approximate Bayesian methods tend to focus on a single mode, whereas deep ensembles tend to explore diverse modes in function space. We investigate this hypothesis by building on recent work on understanding the loss landscape of neural networks and adding our own exploration to measure the similarity of functions in the space of predictions. Our results show that random initializations explore entirely different modes, while functions along an optimization trajectory or sampled from the subspace thereof cluster within a single mode predictions-wise, while often deviating significantly in the weight space. We demonstrate that while low-loss connectors between modes exist, they are not connected in the space of predictions. Developing the concept of the diversity--accuracy plane, we show that the decorrelation power of random initializations is unmatched by popular subspace sampling methods.
Emergent properties of the local geometry of neural loss landscapes
Oct 14, 2019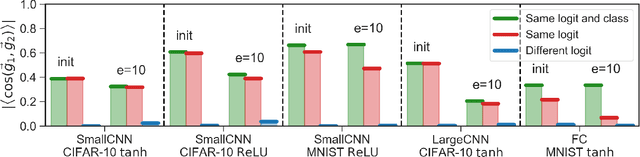
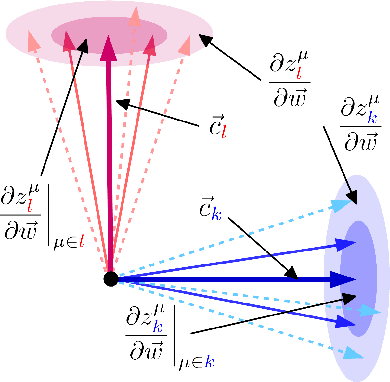

The local geometry of high dimensional neural network loss landscapes can both challenge our cherished theoretical intuitions as well as dramatically impact the practical success of neural network training. Indeed recent works have observed 4 striking local properties of neural loss landscapes on classification tasks: (1) the landscape exhibits exactly $C$ directions of high positive curvature, where $C$ is the number of classes; (2) gradient directions are largely confined to this extremely low dimensional subspace of positive Hessian curvature, leaving the vast majority of directions in weight space unexplored; (3) gradient descent transiently explores intermediate regions of higher positive curvature before eventually finding flatter minima; (4) training can be successful even when confined to low dimensional {\it random} affine hyperplanes, as long as these hyperplanes intersect a Goldilocks zone of higher than average curvature. We develop a simple theoretical model of gradients and Hessians, justified by numerical experiments on architectures and datasets used in practice, that {\it simultaneously} accounts for all $4$ of these surprising and seemingly unrelated properties. Our unified model provides conceptual insights into the emergence of these properties and makes connections with diverse topics in neural networks, random matrix theory, and spin glasses, including the neural tangent kernel, BBP phase transitions, and Derrida's random energy model.
Large Scale Structure of Neural Network Loss Landscapes
Jun 11, 2019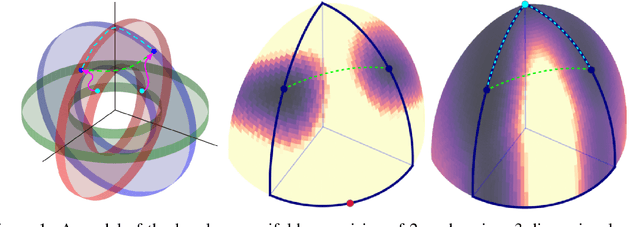
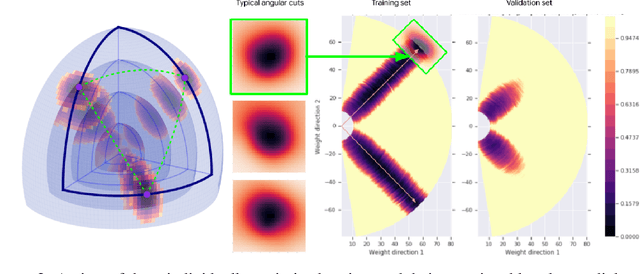
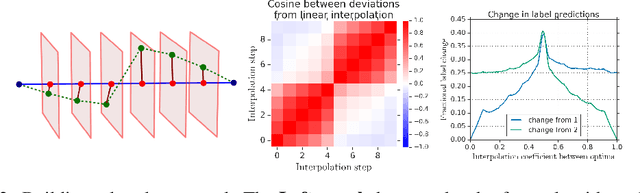
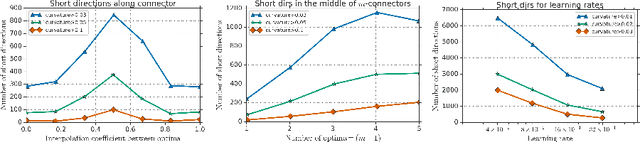
There are many surprising and perhaps counter-intuitive properties of optimization of deep neural networks. We propose and experimentally verify a unified phenomenological model of the loss landscape that incorporates many of them. High dimensionality plays a key role in our model. Our core idea is to model the loss landscape as a set of high dimensional \emph{wedges} that together form a large-scale, inter-connected structure and towards which optimization is drawn. We first show that hyperparameter choices such as learning rate, network width and $L_2$ regularization, affect the path optimizer takes through the landscape in a similar ways, influencing the large scale curvature of the regions the optimizer explores. Finally, we predict and demonstrate new counter-intuitive properties of the loss-landscape. We show an existence of low loss subspaces connecting a set (not only a pair) of solutions, and verify it experimentally. Finally, we analyze recently popular ensembling techniques for deep networks in the light of our model.
Stiffness: A New Perspective on Generalization in Neural Networks
Jan 28, 2019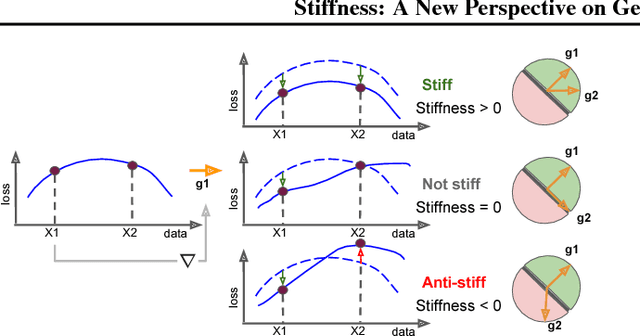
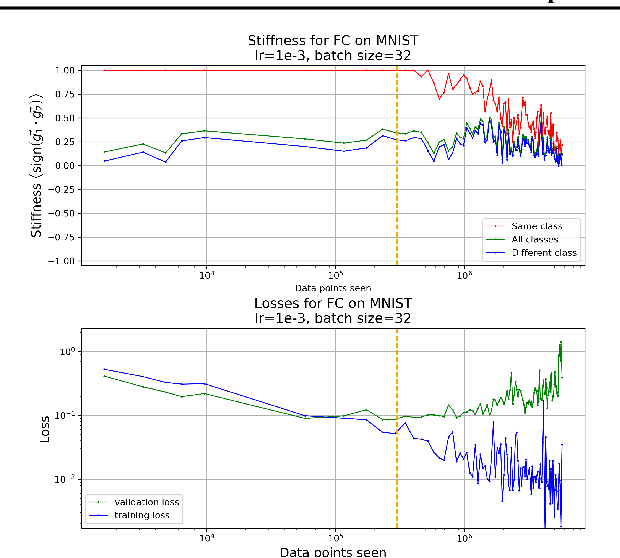
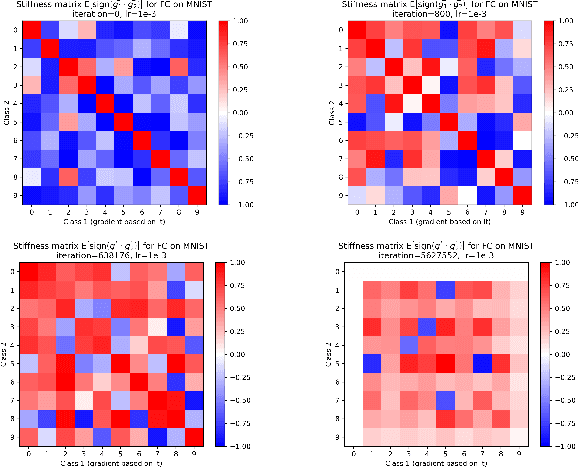
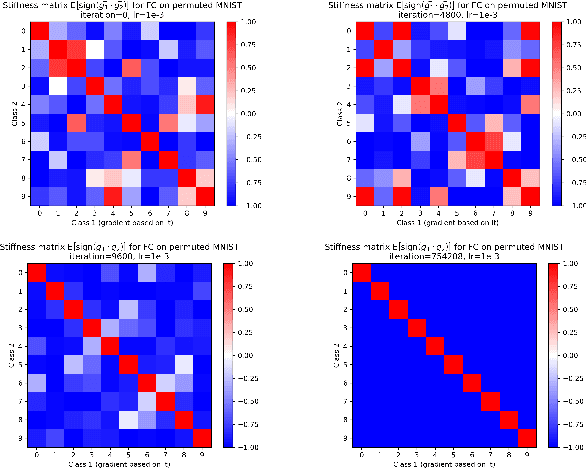
We investigate neural network training and generalization using the concept of stiffness. We measure how stiff a network is by looking at how a small gradient step on one example affects the loss on another example. In particular, we study how stiffness varies with 1) class membership, 2) distance between data points (in the input space as well as in latent spaces), 3) training iteration, and 4) learning rate. We empirically study the evolution of stiffness on MNIST, FASHION MNIST, CIFAR-10 and CIFAR-100 using fully-connected and convolutional neural networks. Our results demonstrate that stiffness is a useful concept for diagnosing and characterizing generalization. We observe that small learning rates lead to initial learning of more specific features that do not translate well to improvements on inputs from all classes, whereas high learning rates initially benefit all classes at once. We measure stiffness as a function of distance between data points and observe that higher learning rates induce positive correlation between changes in loss further apart, pointing towards a regularization effect of learning rate. When training on CIFAR-100, the stiffness matrix exhibits a coarse-grained behavior suggestive of the model's awareness of super-class membership.
Adaptive Quantum State Tomography with Neural Networks
Dec 17, 2018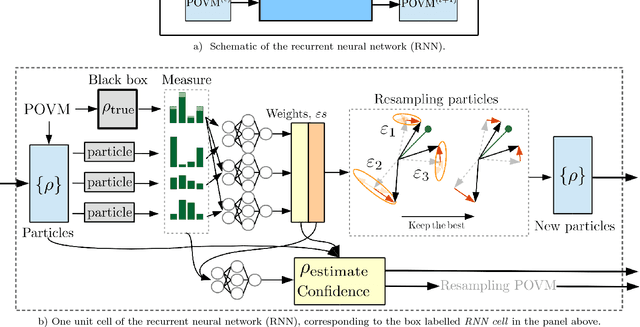
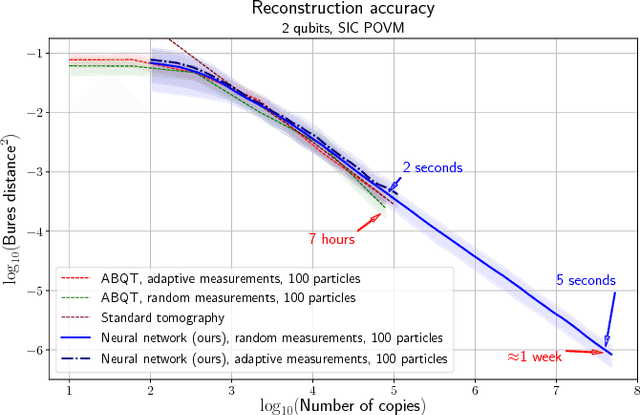
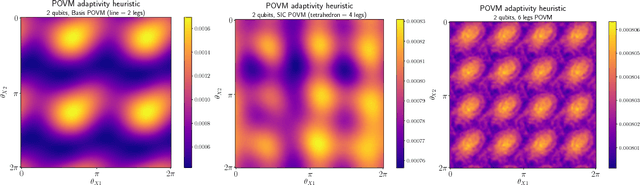
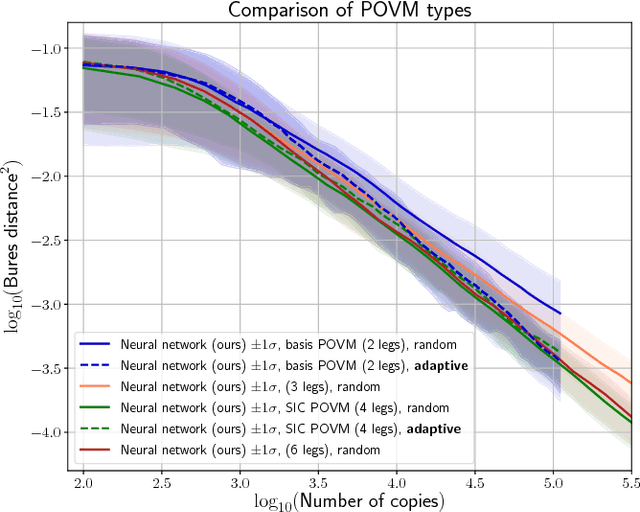
Quantum State Tomography is the task of determining an unknown quantum state by making measurements on identical copies of the state. Current algorithms are costly both on the experimental front -- requiring vast numbers of measurements -- as well as in terms of the computational time to analyze those measurements. In this paper, we address the problem of analysis speed and flexibility, introducing \textit{Neural Adaptive Quantum State Tomography} (NA-QST), a machine learning based algorithm for quantum state tomography that adapts measurements and provides orders of magnitude faster processing while retaining state-of-the-art reconstruction accuracy. Our algorithm is inspired by particle swarm optimization and Bayesian particle-filter based adaptive methods, which we extend and enhance using neural networks. The resampling step, in which a bank of candidate solutions -- particles -- is refined, is in our case learned directly from data, removing the computational bottleneck of standard methods. We successfully replace the Bayesian calculation that requires computational time of $O(\mathrm{poly}(n))$ with a learned heuristic whose time complexity empirically scales as $O(\log(n))$ with the number of copies measured $n$, while retaining the same reconstruction accuracy. This corresponds to a factor of a million speedup for $10^7$ copies measured. We demonstrate that our algorithm learns to work with basis, symmetric informationally complete (SIC), as well as other types of POVMs. We discuss the value of measurement adaptivity for each POVM type, demonstrating that its effect is significant only for basis POVMs. Our algorithm can be retrained within hours on a single laptop for a two-qubit situation, which suggests a feasible time-cost when extended to larger systems. It can also adapt to a subset of possible states, a choice of the type of measurement, and other experimental details.
The Goldilocks zone: Towards better understanding of neural network loss landscapes
Jul 06, 2018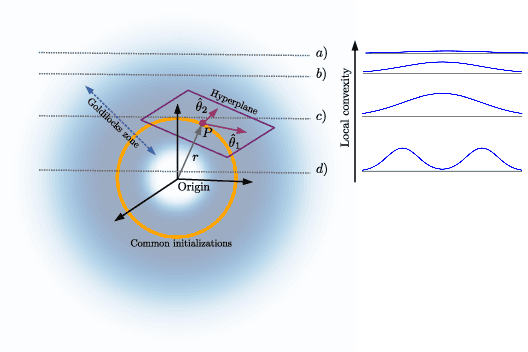
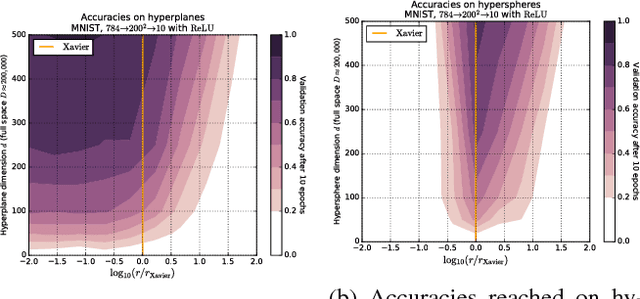
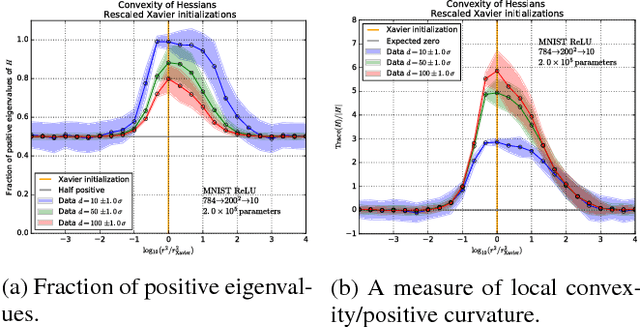
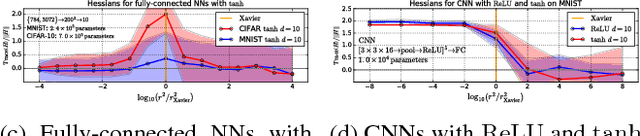
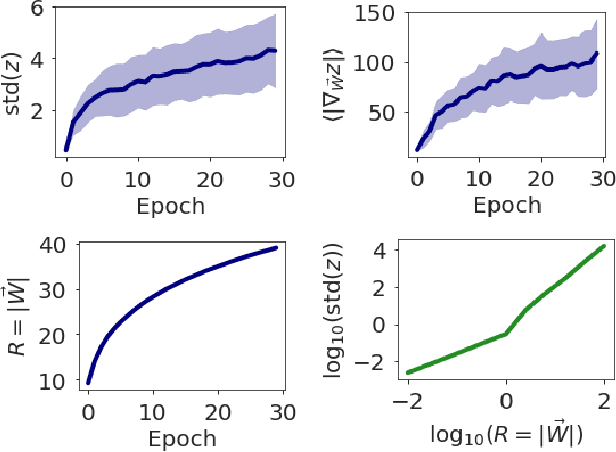
We explore the loss landscape of fully-connected neural networks using random, low-dimensional hyperplanes and hyperspheres. Evaluating the Hessian, $H$, of the loss function on these hypersurfaces, we observe 1) an unusual excess of the number of positive eigenvalues of $H$, and 2) a large value of $\mathrm{Tr}(H) / |H|$ at a well defined range of configuration space radii, corresponding to a thick, hollow, spherical shell we refer to as the \textit{Goldilocks zone}. We observe this effect for fully-connected neural networks over a range of network widths and depths on MNIST and CIFAR-10 with the $\mathrm{ReLU}$ non-linearity. The effect is not observed for the $\tanh$ non-linearity. Using our observations, we demonstrate a close connection between the Goldilocks zone, measures of local convexity/prevalence of positive curvature, and the suitability of a network initialization. We show that the high and stable accuracy reached when optimizing on random, low-dimensional hypersurfaces is directly related to the overlap between the hypersurface and the Goldilocks zone. We note that common initialization techniques initialize neural networks in this particular region of unusually high convexity, and offer a geometric intuition for their success. We take steps towards an analytic description of the general features of the loss function geometry, exploring its anisotropy and strong radial dependence. We support our theoretical results with experiments. Furthermore, we demonstrate that initializing a neural network at a number of points and selecting for high measures of local convexity such as $\mathrm{Tr}(H) / |H|$, number of positive eigenvalues of $H$, or low initial loss, leads to statistically significantly faster training on MNIST. Based on our observations, we hypothesize that the Goldilocks zone contains a high density of suitable initialization configurations.
Towards understanding feedback from supermassive black holes using convolutional neural networks
Dec 02, 2017
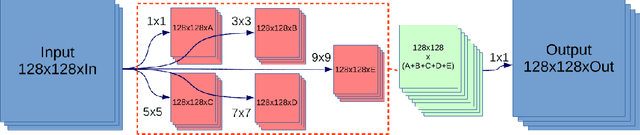
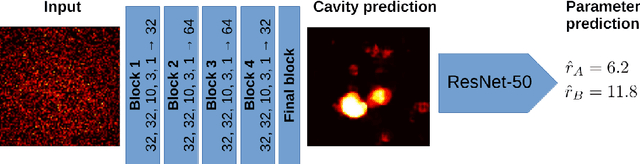

Supermassive black holes at centers of clusters of galaxies strongly interact with their host environment via AGN feedback. Key tracers of such activity are X-ray cavities -- regions of lower X-ray brightness within the cluster. We present an automatic method for detecting, and characterizing X-ray cavities in noisy, low-resolution X-ray images. We simulate clusters of galaxies, insert cavities into them, and produce realistic low-quality images comparable to observations at high redshifts. We then train a custom-built convolutional neural network to generate pixel-wise analysis of presence of cavities in a cluster. A ResNet architecture is then used to decode radii of cavities from the pixel-wise predictions. We surpass the accuracy, stability, and speed of current visual inspection based methods on simulated data.
Gaussian Prototypical Networks for Few-Shot Learning on Omniglot
Aug 09, 2017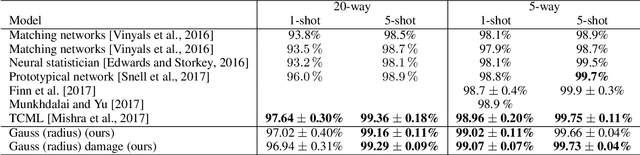
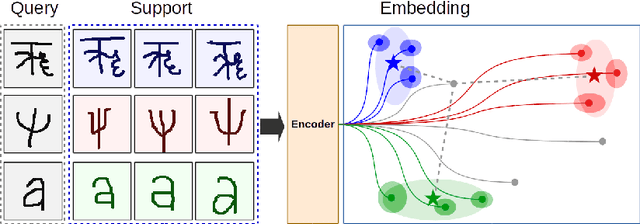
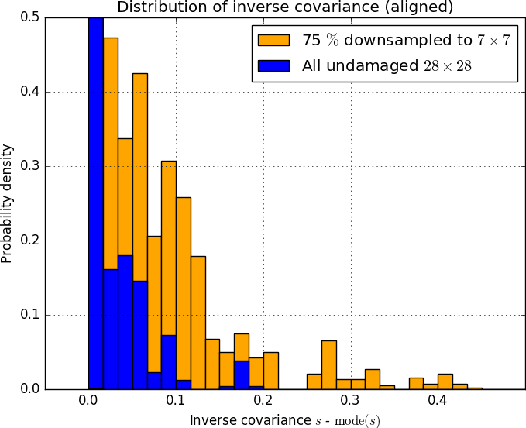
We propose a novel architecture for $k$-shot classification on the Omniglot dataset. Building on prototypical networks, we extend their architecture to what we call Gaussian prototypical networks. Prototypical networks learn a map between images and embedding vectors, and use their clustering for classification. In our model, a part of the encoder output is interpreted as a confidence region estimate about the embedding point, and expressed as a Gaussian covariance matrix. Our network then constructs a direction and class dependent distance metric on the embedding space, using uncertainties of individual data points as weights. We show that Gaussian prototypical networks are a preferred architecture over vanilla prototypical networks with an equivalent number of parameters. We report state-of-the-art performance in 1-shot and 5-shot classification both in 5-way and 20-way regime (for 5-shot 5-way, we are comparable to previous state-of-the-art) on the Omniglot dataset. We explore artificially down-sampling a fraction of images in the training set, which improves our performance even further. We therefore hypothesize that Gaussian prototypical networks might perform better in less homogeneous, noisier datasets, which are commonplace in real world applications.