 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Approach to Privacy-Preserving Federated Learning
Dec 07, 2018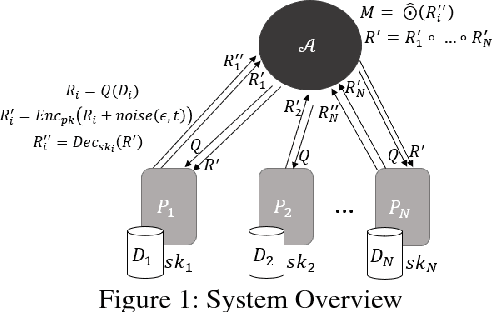
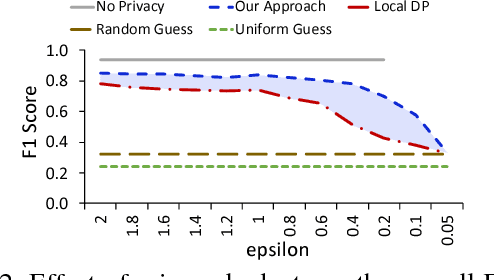
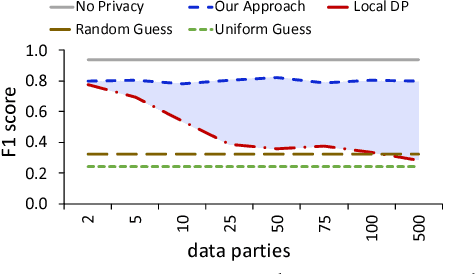
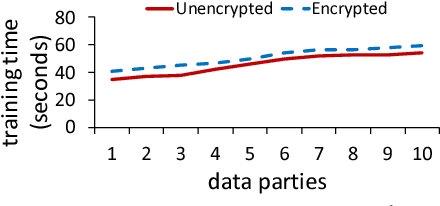
Training machine learning models often requires data from multiple parties. However, in some cases, data owners cannot share their data due to legal or privacy constraints but would still benefit from training a model jointly with multiple parties. Federated learning has arisen as an alternative to allow for the collaborative training of models without the sharing of raw data. However, attacks in the literature have demonstrated that simply maintaining data locally during training processes does not provide strong enough privacy guarantees. We need a federated learning system capable of preventing inference over the messages exchanged between parties during training as well as the final, trained model, considering potential collusion between parties, and ensuring the resulting machine learning model has acceptable predictive accuracy. Currently, existing approaches are either vulnerable to inference or do not scale for a large number of parties, resulting in models with low accuracy. To close this gap, we present a scalable approach that protects against these threats while producing models with high accuracy. Our approach provides formal data privacy guarantees using both differential privacy and secure multiparty computation frameworks. We validate our system with experimental results on two popular and significantly different machine learning algorithms: decision trees and convolutional neural networks. To the best of our knowledge, this presents the first approach to accurately train a neural network in a private, federated fashion. Our experiments demonstrate that our approach outperforms state of the art solutions in accuracy, customizability, and scalability.
Adversarial Examples in Deep Learning: Characterization and Divergence
Oct 29, 2018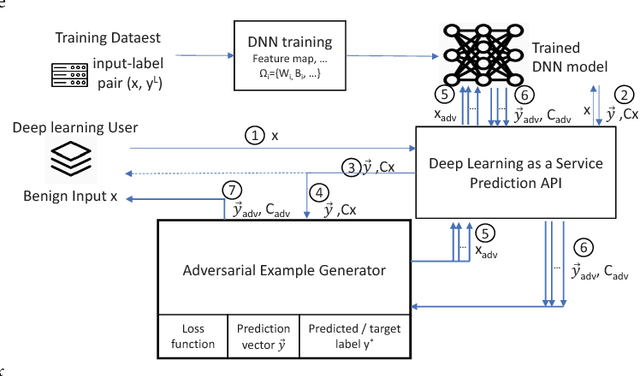

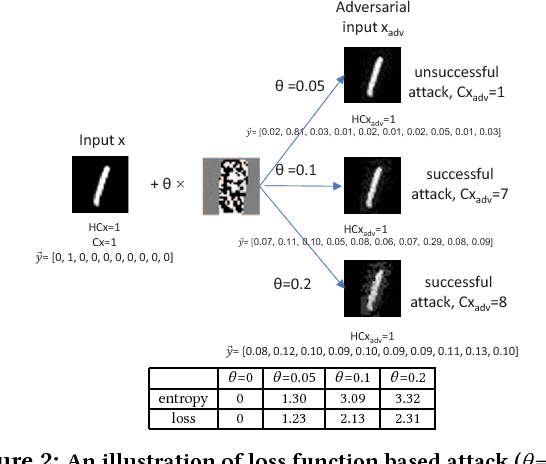
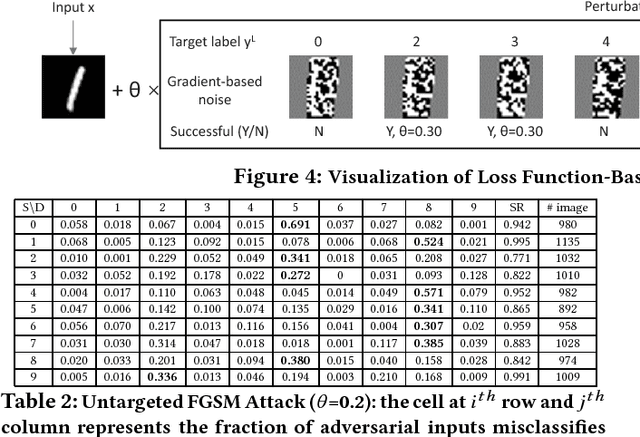
The burgeoning success of deep learning has raised the security and privacy concerns as more and more tasks are accompanied with sensitive data. Adversarial attacks in deep learning have emerged as one of the dominating security threat to a range of mission-critical deep learning systems and applications. This paper takes a holistic and principled approach to perform statistical characterization of adversarial examples in deep learning. We provide a general formulation of adversarial examples and elaborate on the basic principle for adversarial attack algorithm design. We introduce easy and hard categorization of adversarial attacks to analyze the effectiveness of adversarial examples in terms of attack success rate, degree of change in adversarial perturbation, average entropy of prediction qualities, and fraction of adversarial examples that lead to successful attacks. We conduct extensive experimental study on adversarial behavior in easy and hard attacks under deep learning models with different hyperparameters and different deep learning frameworks. We show that the same adversarial attack behaves differently under different hyperparameters and across different frameworks due to the different features learned under different deep learning model training process. Our statistical characterization with strong empirical evidence provides a transformative enlightenment on mitigation strategies towards effective countermeasures against present and future adversarial attacks.