 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Caching for Efficiently Serving Diffusion Models
Dec 07, 2023



Text-to-image generation using diffusion models has seen explosive popularity owing to their ability in producing high quality images adhering to text prompts. However, production-grade diffusion model serving is a resource intensive task that not only require high-end GPUs which are expensive but also incurs considerable latency. In this paper, we introduce a technique called approximate-caching that can reduce such iterative denoising steps for an image generation based on a prompt by reusing intermediate noise states created during a prior image generation for similar prompts. Based on this idea, we present an end to end text-to-image system, Nirvana, that uses the approximate-caching with a novel cache management-policy Least Computationally Beneficial and Frequently Used (LCBFU) to provide % GPU compute savings, 19.8% end-to-end latency reduction and 19% dollar savings, on average, on two real production workloads. We further present an extensive characterization of real production text-to-image prompts from the perspective of caching, popularity and reuse of intermediate states in a large production environment.
An Image is Worth Multiple Words: Multi-attribute Inversion for Constrained Text-to-Image Synthesis
Nov 20, 2023We consider the problem of constraining diffusion model outputs with a user-supplied reference image. Our key objective is to extract multiple attributes (e.g., color, object, layout, style) from this single reference image, and then generate new samples with them. One line of existing work proposes to invert the reference images into a single textual conditioning vector, enabling generation of new samples with this learned token. These methods, however, do not learn multiple tokens that are necessary to condition model outputs on the multiple attributes noted above. Another line of techniques expand the inversion space to learn multiple embeddings but they do this only along the layer dimension (e.g., one per layer of the DDPM model) or the timestep dimension (one for a set of timesteps in the denoising process), leading to suboptimal attribute disentanglement. To address the aforementioned gaps, the first contribution of this paper is an extensive analysis to determine which attributes are captured in which dimension of the denoising process. As noted above, we consider both the time-step dimension (in reverse denoising) as well as the DDPM model layer dimension. We observe that often a subset of these attributes are captured in the same set of model layers and/or across same denoising timesteps. For instance, color and style are captured across same U-Net layers, whereas layout and color are captured across same timestep stages. Consequently, an inversion process that is designed only for the time-step dimension or the layer dimension is insufficient to disentangle all attributes. This leads to our second contribution where we design a new multi-attribute inversion algorithm, MATTE, with associated disentanglement-enhancing regularization losses, that operates across both dimensions and explicitly leads to four disentangled tokens (color, style, layout, and object).
Iterative Multi-granular Image Editing using Diffusion Models
Sep 01, 2023



Recent advances in text-guided image synthesis has dramatically changed how creative professionals generate artistic and aesthetically pleasing visual assets. To fully support such creative endeavors, the process should possess the ability to: 1) iteratively edit the generations and 2) control the spatial reach of desired changes (global, local or anything in between). We formalize this pragmatic problem setting as Iterative Multi-granular Editing. While there has been substantial progress with diffusion-based models for image synthesis and editing, they are all one shot (i.e., no iterative editing capabilities) and do not naturally yield multi-granular control (i.e., covering the full spectrum of local-to-global edits). To overcome these drawbacks, we propose EMILIE: Iterative Multi-granular Image Editor. EMILIE introduces a novel latent iteration strategy, which re-purposes a pre-trained diffusion model to facilitate iterative editing. This is complemented by a gradient control operation for multi-granular control. We introduce a new benchmark dataset to evaluate our newly proposed setting. We conduct exhaustive quantitatively and qualitatively evaluation against recent state-of-the-art approaches adapted to our task, to being out the mettle of EMILIE. We hope our work would attract attention to this newly identified, pragmatic problem setting.
Learning with Multi-modal Gradient Attention for Explainable Composed Image Retrieval
Aug 31, 2023



We consider the problem of composed image retrieval that takes an input query consisting of an image and a modification text indicating the desired changes to be made on the image and retrieves images that match these changes. Current state-of-the-art techniques that address this problem use global features for the retrieval, resulting in incorrect localization of the regions of interest to be modified because of the global nature of the features, more so in cases of real-world, in-the-wild images. Since modifier texts usually correspond to specific local changes in an image, it is critical that models learn local features to be able to both localize and retrieve better. To this end, our key novelty is a new gradient-attention-based learning objective that explicitly forces the model to focus on the local regions of interest being modified in each retrieval step. We achieve this by first proposing a new visual image attention computation technique, which we call multi-modal gradient attention (MMGrad) that is explicitly conditioned on the modifier text. We next demonstrate how MMGrad can be incorporated into an end-to-end model training strategy with a new learning objective that explicitly forces these MMGrad attention maps to highlight the correct local regions corresponding to the modifier text. By training retrieval models with this new loss function, we show improved grounding by means of better visual attention maps, leading to better explainability of the models as well as competitive quantitative retrieval performance on standard benchmark datasets.
Contextual Prompt Learning for Vision-Language Understanding
Jul 03, 2023



Recent advances in multimodal learning has resulted in powerful vision-language models, whose representations are generalizable across a variety of downstream tasks. Recently, their generalizability has been further extended by incorporating trainable prompts, borrowed from the natural language processing literature. While such prompt learning techniques have shown impressive results, we identify that these prompts are trained based on global image features which limits itself in two aspects: First, by using global features, these prompts could be focusing less on the discriminative foreground image, resulting in poor generalization to various out-of-distribution test cases. Second, existing work weights all prompts equally whereas our intuition is that these prompts are more specific to the type of the image. We address these issues with as part of our proposed Contextual Prompt Learning (CoPL) framework, capable of aligning the prompts to the localized features of the image. Our key innovations over earlier works include using local image features as part of the prompt learning process, and more crucially, learning to weight these prompts based on local features that are appropriate for the task at hand. This gives us dynamic prompts that are both aligned to local image features as well as aware of local contextual relationships. Our extensive set of experiments on a variety of standard and few-shot datasets show that our method produces substantially improved performance when compared to the current state of the art methods. We also demonstrate both few-shot and out-of-distribution performance to establish the utility of learning dynamic prompts that are aligned to local image features.
A-STAR: Test-time Attention Segregation and Retention for Text-to-image Synthesis
Jun 26, 2023



While recent developments in text-to-image generative models have led to a suite of high-performing methods capable of producing creative imagery from free-form text, there are several limitations. By analyzing the cross-attention representations of these models, we notice two key issues. First, for text prompts that contain multiple concepts, there is a significant amount of pixel-space overlap (i.e., same spatial regions) among pairs of different concepts. This eventually leads to the model being unable to distinguish between the two concepts and one of them being ignored in the final generation. Next, while these models attempt to capture all such concepts during the beginning of denoising (e.g., first few steps) as evidenced by cross-attention maps, this knowledge is not retained by the end of denoising (e.g., last few steps). Such loss of knowledge eventually leads to inaccurate generation outputs. To address these issues, our key innovations include two test-time attention-based loss functions that substantially improve the performance of pretrained baseline text-to-image diffusion models. First, our attention segregation loss reduces the cross-attention overlap between attention maps of different concepts in the text prompt, thereby reducing the confusion/conflict among various concepts and the eventual capture of all concepts in the generated output. Next, our attention retention loss explicitly forces text-to-image diffusion models to retain cross-attention information for all concepts across all denoising time steps, thereby leading to reduced information loss and the preservation of all concepts in the generated output.
Learning with Difference Attention for Visually Grounded Self-supervised Representations
Jun 26, 2023



Recent works in self-supervised learning have shown impressive results on single-object images, but they struggle to perform well on complex multi-object images as evidenced by their poor visual grounding. To demonstrate this concretely, we propose visual difference attention (VDA) to compute visual attention maps in an unsupervised fashion by comparing an image with its salient-regions-masked-out version. We use VDA to derive attention maps for state-of-the art SSL methods and show they do not highlight all salient regions in an image accurately, suggesting their inability to learn strong representations for downstream tasks like segmentation. Motivated by these limitations, we cast VDA as a differentiable operation and propose a new learning objective, Differentiable Difference Attention (DiDA) loss, which leads to substantial improvements in an SSL model's visually grounding to an image's salient regions.
Audio Retrieval for Multimodal Design Documents: A New Dataset and Algorithms
Feb 28, 2023



We consider and propose a new problem of retrieving audio files relevant to multimodal design document inputs comprising both textual elements and visual imagery, e.g., birthday/greeting cards. In addition to enhancing user experience, integrating audio that matches the theme/style of these inputs also helps improve the accessibility of these documents (e.g., visually impaired people can listen to the audio instead). While recent work in audio retrieval exists, these methods and datasets are targeted explicitly towards natural images. However, our problem considers multimodal design documents (created by users using creative software) substantially different from a naturally clicked photograph. To this end, our first contribution is collecting and curating a new large-scale dataset called Melodic-Design (or MELON), comprising design documents representing various styles, themes, templates, illustrations, etc., paired with music audio. Given our paired image-text-audio dataset, our next contribution is a novel multimodal cross-attention audio retrieval (MMCAR) algorithm that enables training neural networks to learn a common shared feature space across image, text, and audio dimensions. We use these learned features to demonstrate that our method outperforms existing state-of-the-art methods and produce a new reference benchmark for the research community on our new dataset.
Preserving Privacy in Federated Learning with Ensemble Cross-Domain Knowledge Distillation
Sep 10, 2022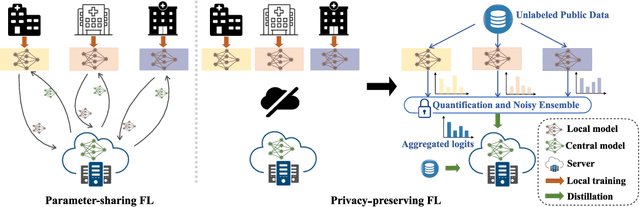
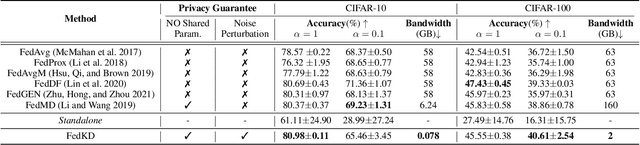
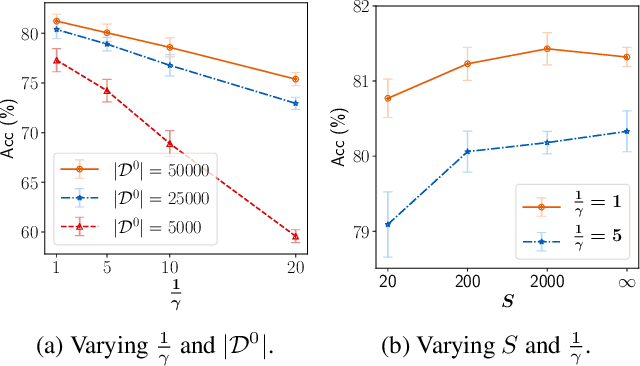
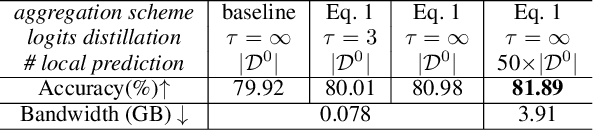
Federated Learning (FL) is a machine learning paradigm where local nodes collaboratively train a central model while the training data remains decentralized. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they suffer from communication bottlenecks. More importantly, they risk privacy leakage. In this work, we develop a privacy preserving and communication efficient method in a FL framework with one-shot offline knowledge distillation using unlabeled, cross-domain public data. We propose a quantized and noisy ensemble of local predictions from completely trained local models for stronger privacy guarantees without sacrificing accuracy. Based on extensive experiments on image classification and text classification tasks, we show that our privacy-preserving method outperforms baseline FL algorithms with superior performance in both accuracy and communication efficiency.
Self-supervised Human Mesh Recovery with Cross-Representation Alignment
Sep 10, 2022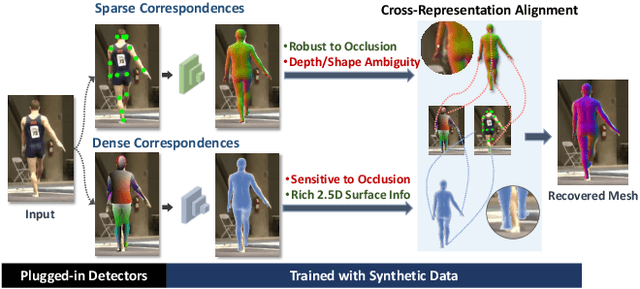
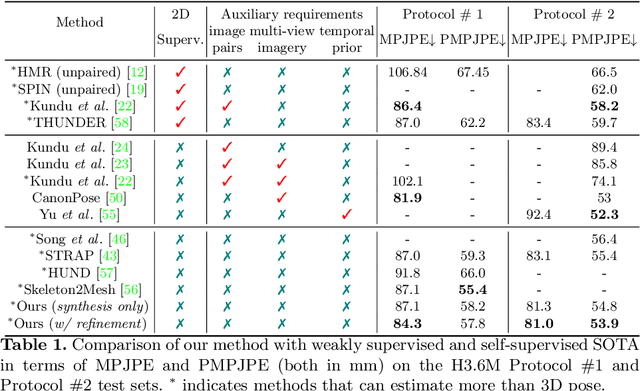
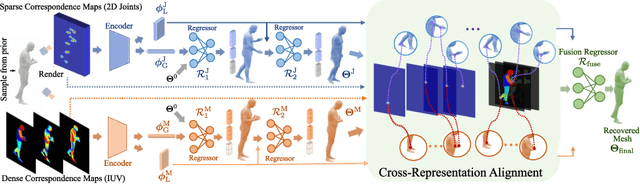
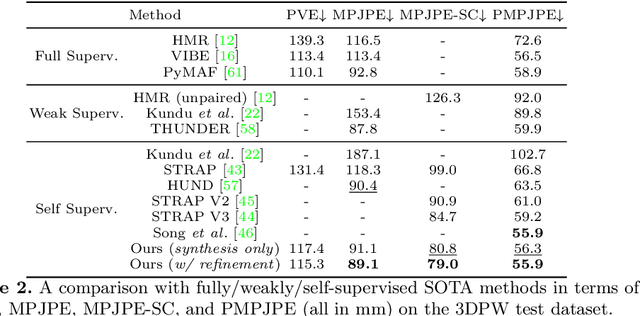
Fully supervised human mesh recovery methods are data-hungry and have poor generalizability due to the limited availability and diversity of 3D-annotated benchmark datasets. Recent progress in self-supervised human mesh recovery has been made using synthetic-data-driven training paradigms where the model is trained from synthetic paired 2D representation (e.g., 2D keypoints and segmentation masks) and 3D mesh. However, on synthetic dense correspondence maps (i.e., IUV) few have been explored since the domain gap between synthetic training data and real testing data is hard to address for 2D dense representation. To alleviate this domain gap on IUV, we propose cross-representation alignment utilizing the complementary information from the robust but sparse representation (2D keypoints). Specifically, the alignment errors between initial mesh estimation and both 2D representations are forwarded into regressor and dynamically corrected in the following mesh regression. This adaptive cross-representation alignment explicitly learns from the deviations and captures complementary information: robustness from sparse representation and richness from dense representation. We conduct extensive experiments on multiple standard benchmark datasets and demonstrate competitive results, helping take a step towards reducing the annotation effort needed to produce state-of-the-art models in human mesh estimation.