 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIGGER: Scalable Generative Modelling for Temporal Interaction Graphs
Mar 08, 2022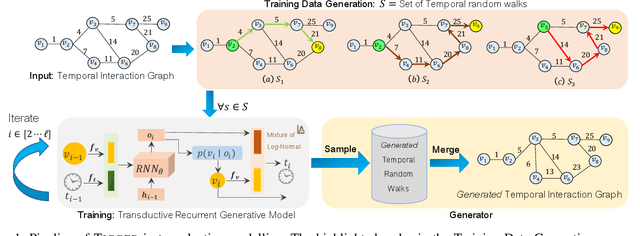
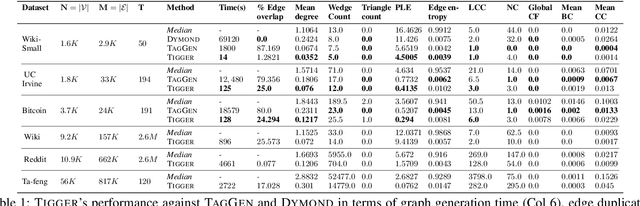

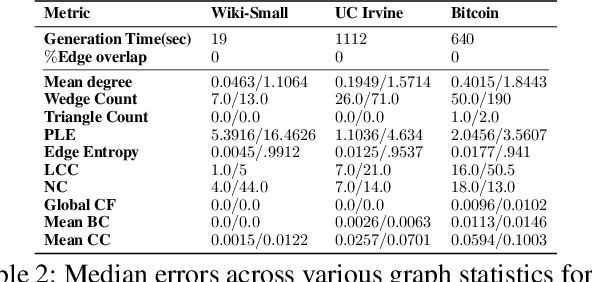
There has been a recent surge in learning generative models for graphs. While impressive progress has been made on static graphs, work on generative modeling of temporal graphs is at a nascent stage with significant scope for improvement. First, existing generative models do not scale with either the time horizon or the number of nodes. Second, existing techniques are transductive in nature and thus do not facilitate knowledge transfer. Finally, due to relying on one-to-one node mapping from source to the generated graph, existing models leak node identity information and do not allow up-scaling/down-scaling the source graph size. In this paper, we bridge these gaps with a novel generative model called TIGGER. TIGGER derives its power through a combination of temporal point processes with auto-regressive modeling enabling both transductive and inductive variants. Through extensive experiments on real datasets, we establish TIGGER generates graphs of superior fidelity, while also being up to 3 orders of magnitude faster than the state-of-the-art.
Learning Temporal Point Processes for Efficient Retrieval of Continuous Time Event Sequences
Feb 17, 2022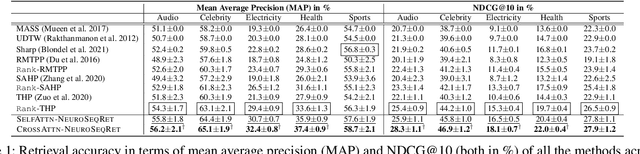

Recent developments in predictive modeling using marked temporal point processes (MTPP) have enabled an accurate characterization of several real-world applications involving continuous-time event sequences (CTESs). However, the retrieval problem of such sequences remains largely unaddressed in literature. To tackle this, we propose NEUROSEQRET which learns to retrieve and rank a relevant set of continuous-time event sequences for a given query sequence, from a large corpus of sequences. More specifically, NEUROSEQRET first applies a trainable unwarping function on the query sequence, which makes it comparable with corpus sequences, especially when a relevant query-corpus pair has individually different attributes. Next, it feeds the unwarped query sequence and the corpus sequence into MTPP guided neural relevance models. We develop two variants of the relevance model which offer a tradeoff between accuracy and efficiency. We also propose an optimization framework to learn binary sequence embeddings from the relevance scores, suitable for the locality-sensitive hashing leading to a significant speedup in returning top-K results for a given query sequence. Our experiments with several datasets show the significant accuracy boost of NEUROSEQRET beyond several baselines, as well as the efficacy of our hashing mechanism.
Doing More with Less: Overcoming Data Scarcity for POI Recommendation via Cross-Region Transfer
Jan 16, 2022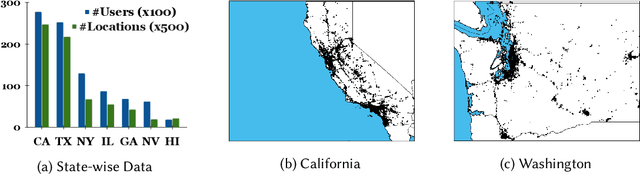
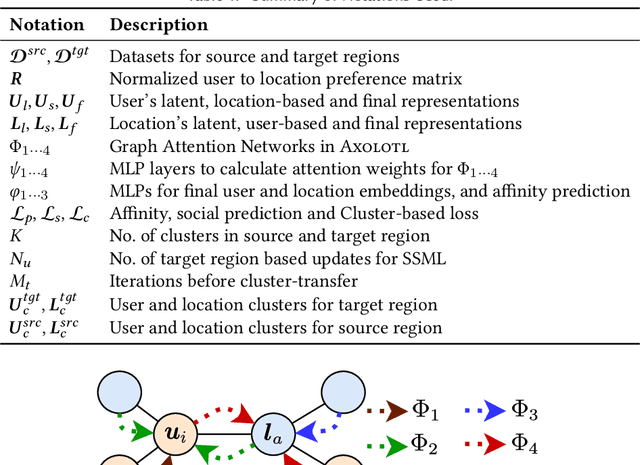
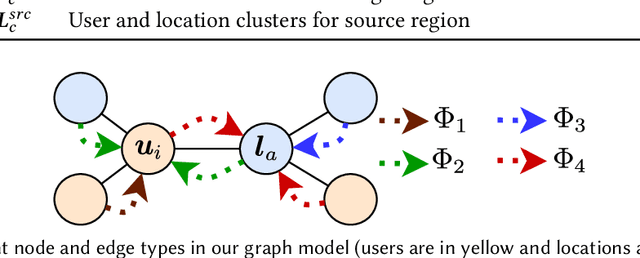

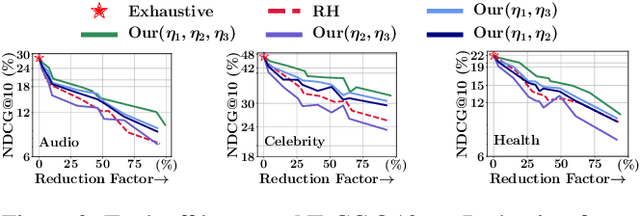
Variability in social app usage across regions results in a high skew of the quantity and the quality of check-in data collected, which in turn is a challenge for effective location recommender systems. In this paper, we present Axolotl (Automated cross Location-network Transfer Learning), a novel method aimed at transferring location preference models learned in a data-rich region to significantly boost the quality of recommendations in a data-scarce region. Axolotl predominantly deploys two channels for information transfer, (1) a meta-learning based procedure learned using location recommendation as well as social predictions, and (2) a lightweight unsupervised cluster-based transfer across users and locations with similar preferences. Both of these work together synergistically to achieve improved accuracy of recommendations in data-scarce regions without any prerequisite of overlapping users and with minimal fine-tuning. We build Axolotl on top of a twin graph-attention neural network model used for capturing the user- and location-conditioned influences in a user-mobility graph for each region. We conduct extensive experiments on 12 user mobility datasets across the U.S., Japan, and Germany, using 3 as source regions and 9 of them (that have much sparsely recorded mobility data) as target regions. Empirically, we show that Axolotl achieves up to 18% better recommendation performance than the existing state-of-the-art methods across all metrics.
VizAI : Selecting Accurate Visualizations of Numerical Data
Nov 07, 2021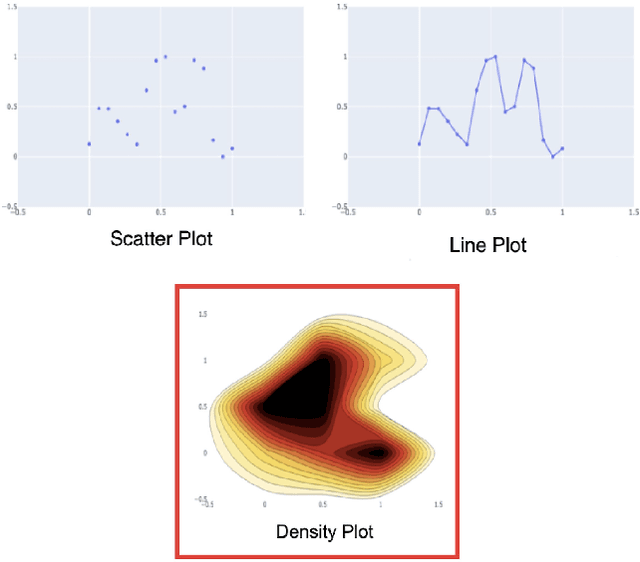
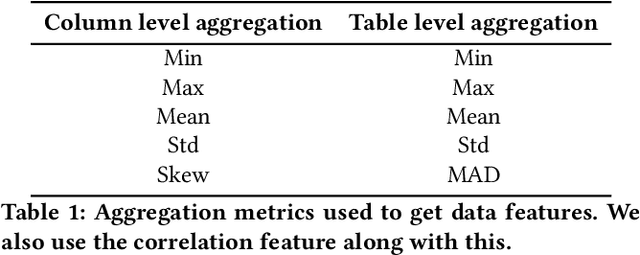
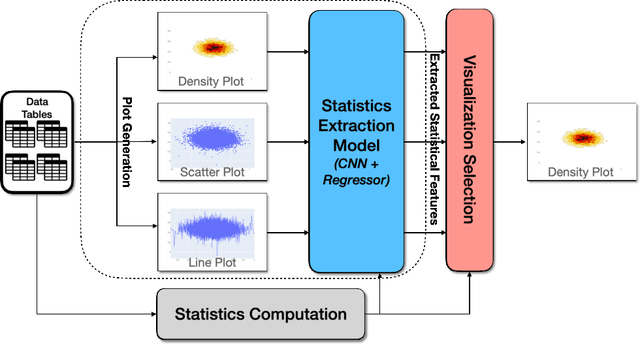
A good data visualization is not only a distortion-free graphical representation of data but also a way to reveal underlying statistical properties of the data. Despite its common use across various stages of data analysis, selecting a good visualization often is a manual process involving many iterations. Recently there has been interest in reducing this effort by developing models that can recommend visualizations, but they are of limited use since they require large training samples (data and visualization pairs) and focus primarily on the design aspects rather than on assessing the effectiveness of the selected visualization. In this paper, we present VizAI, a generative-discriminative framework that first generates various statistical properties of the data from a number of alternative visualizations of the data. It is linked to a discriminative model that selects the visualization that best matches the true statistics of the data being visualized. VizAI can easily be trained with minimal supervision and adapts to settings with varying degrees of supervision easily. Using crowd-sourced judgements and a large repository of publicly available visualizations, we demonstrate that VizAI outperforms the state of the art methods that learn to recommend visualizations.
Region Invariant Normalizing Flows for Mobility Transfer
Sep 13, 2021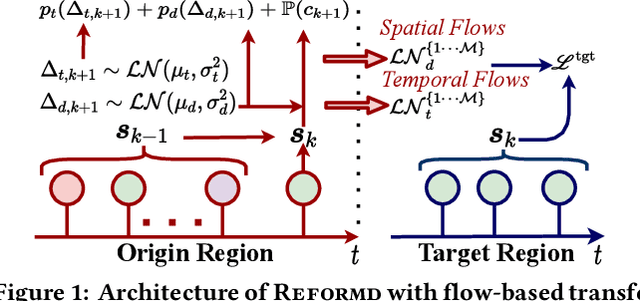
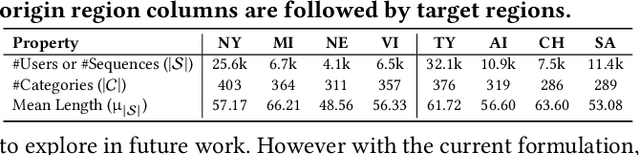
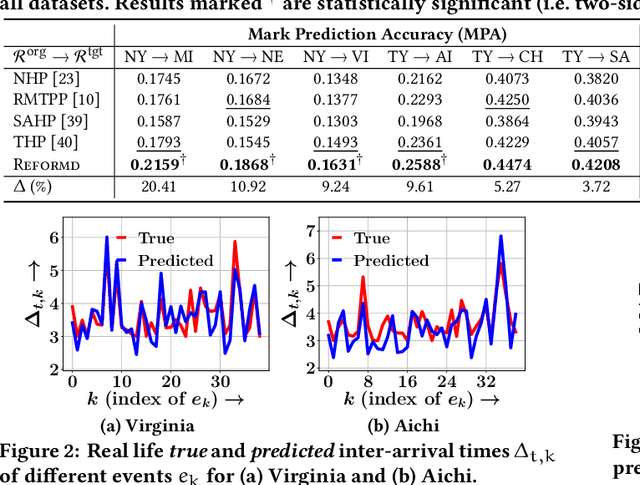
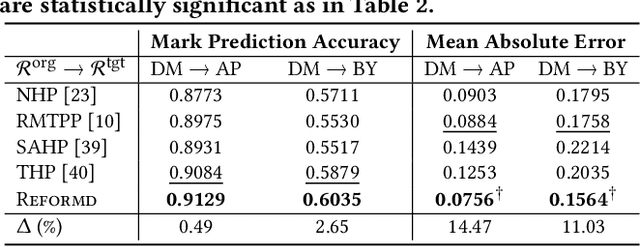
There exists a high variability in mobility data volumes across different regions, which deteriorates the performance of spatial recommender systems that rely on region-specific data. In this paper, we propose a novel transfer learning framework called REFORMD, for continuous-time location prediction for regions with sparse checkin data. Specifically, we model user-specific checkin-sequences in a region using a marked temporal point process (MTPP) with normalizing flows to learn the inter-checkin time and geo-distributions. Later, we transfer the model parameters of spatial and temporal flows trained on a data-rich origin region for the next check-in and time prediction in a target region with scarce checkin data. We capture the evolving region-specific checkin dynamics for MTPP and spatial-temporal flows by maximizing the joint likelihood of next checkin with three channels (1) checkin-category prediction, (2) checkin-time prediction, and (3) travel distance prediction. Extensive experiments on different user mobility datasets across the U.S. and Japan show that our model significantly outperforms state-of-the-art methods for modeling continuous-time sequences. Moreover, we also show that REFORMD can be easily adapted for product recommendations i.e., sequences without any spatial component.
BERT Meets Relational DB: Contextual Representations of Relational Databases
Apr 30, 2021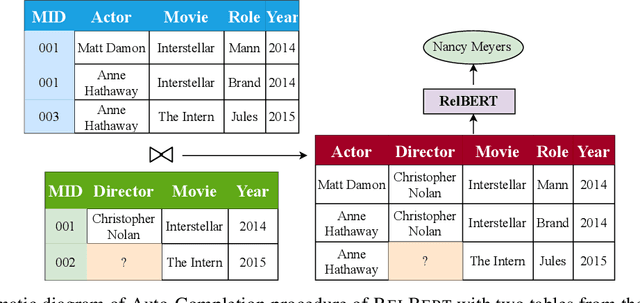
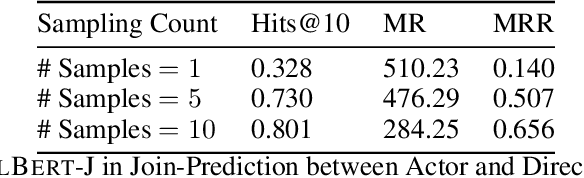
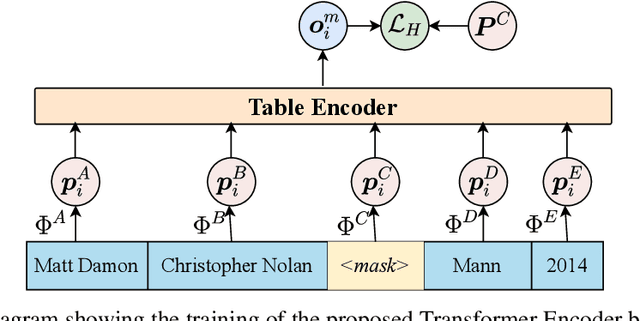
In this paper, we address the problem of learning low dimension representation of entities on relational databases consisting of multiple tables. Embeddings help to capture semantics encoded in the database and can be used in a variety of settings like auto-completion of tables, fully-neural query processing of relational joins queries, seamlessly handling missing values, and more. Current work is restricted to working with just single table, or using pretrained embeddings over an external corpus making them unsuitable for use in real-world databases. In this work, we look into ways of using these attention-based model to learn embeddings for entities in the relational database. We are inspired by BERT style pretraining methods and are interested in observing how they can be extended for representation learning on structured databases. We evaluate our approach of the autocompletion of relational databases and achieve improvement over standard baselines.
Tracking entities in technical procedures -- a new dataset and baselines
Apr 15, 2021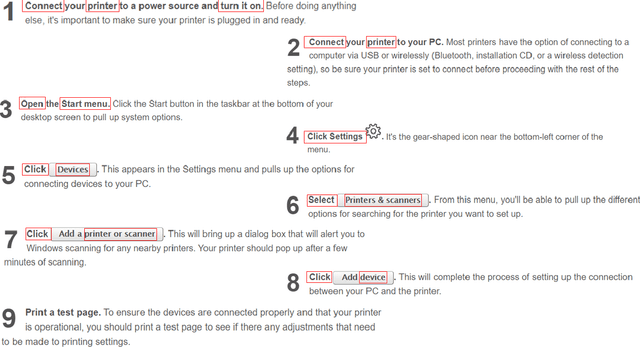

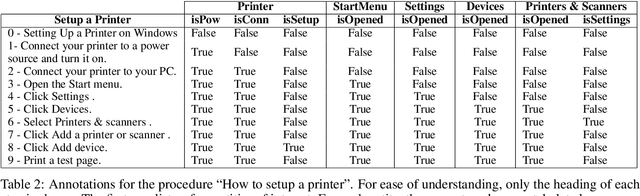
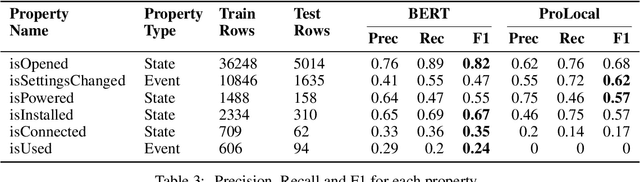
We introduce TechTrack, a new dataset for tracking entities in technical procedures. The dataset, prepared by annotating open domain articles from WikiHow, consists of 1351 procedures, e.g., "How to connect a printer", identifies more than 1200 unique entities with an average of 4.7 entities per procedure. We evaluate the performance of state-of-the-art models on the entity-tracking task and find that they are well below the human annotation performance. We describe how TechTrack can be used to take forward the research on understanding procedures from temporal texts.
FROCC: Fast Random projection-based One-Class Classification
Nov 29, 2020

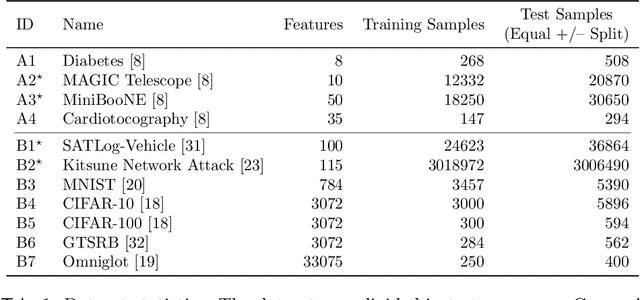

We present Fast Random projection-based One-Class Classification (FROCC), an extremely efficient method for one-class classification. Our method is based on a simple idea of transforming the training data by projecting it onto a set of random unit vectors that are chosen uniformly and independently from the unit sphere, and bounding the regions based on separation of the data. FROCC can be naturally extended with kernels. We theoretically prove that FROCC generalizes well in the sense that it is stable and has low bias. FROCC achieves up to 3.1 percent points better ROC, with 1.2--67.8x speedup in training and test times over a range of state-of-the-art benchmarks including the SVM and the deep learning based models for the OCC task.
A Survey on Semantic Parsing from the perspective of Compositionality
Sep 29, 2020Different from previous surveys in semantic parsing (Kamath and Das, 2018) and knowledge base question answering(KBQA)(Chakraborty et al., 2019; Zhu et al., 2019; Hoffner et al., 2017) we try to takes a different perspective on the study of semantic parsing. Specifically, we will focus on (a)meaning composition from syntactical structure(Partee, 1975), and (b) the ability of semantic parsers to handle lexical variation given the context of a knowledge base (KB). In the following section after an introduction of the field of semantic parsing and its uses in KBQA, we will describe meaning representation using grammar formalism CCG (Steedman, 1996). We will discuss semantic composition using formal languages in Section 2. In section 3 we will consider systems that uses formal languages e.g. $\lambda$-calculus (Steedman, 1996), $\lambda$-DCS (Liang, 2013). Section 4 and 5 consider semantic parser using structured-language for logical form. Section 6 is on different benchmark datasets ComplexQuestions (Bao et al.,2016) and GraphQuestions (Su et al., 2016) that can be used to evaluate semantic parser on their ability to answer complex questions that are highly compositional in nature.
IterefinE: Iterative KG Refinement Embeddings using Symbolic Knowledge
Jun 03, 2020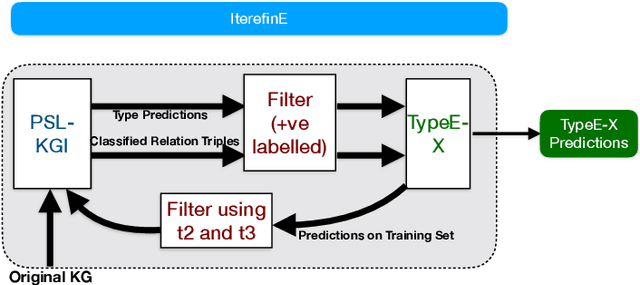
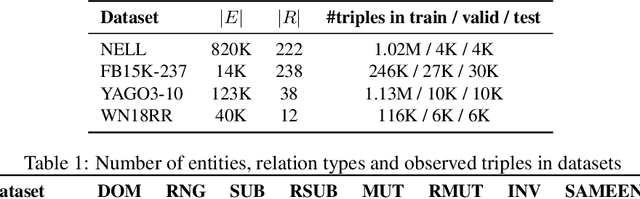
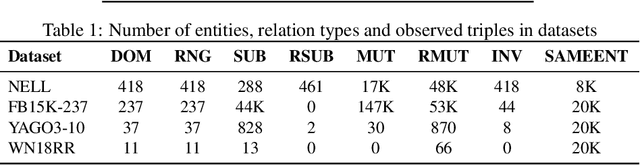
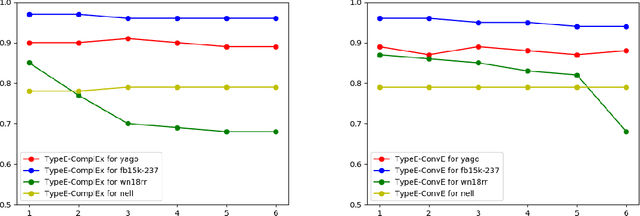
Knowledge Graphs (KGs) extracted from text sources are often noisy and lead to poor performance in downstream application tasks such as KG-based question answering.While much of the recent activity is focused on addressing the sparsity of KGs by using embeddings for inferring new facts, the issue of cleaning up of noise in KGs through KG refinement task is not as actively studied. Most successful techniques for KG refinement make use of inference rules and reasoning over ontologies. Barring a few exceptions, embeddings do not make use of ontological information, and their performance in KG refinement task is not well understood. In this paper, we present a KG refinement framework called IterefinE which iteratively combines the two techniques - one which uses ontological information and inferences rules, PSL-KGI, and the KG embeddings such as ComplEx and ConvE which do not. As a result, IterefinE is able to exploit not only the ontological information to improve the quality of predictions, but also the power of KG embeddings which (implicitly) perform longer chains of reasoning. The IterefinE framework, operates in a co-training mode and results in explicit type-supervised embedding of the refined KG from PSL-KGI which we call as TypeE-X. Our experiments over a range of KG benchmarks show that the embeddings that we produce are able to reject noisy facts from KG and at the same time infer higher quality new facts resulting in up to 9% improvement of overall weighted F1 score