 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolMol: Evolutionary Agentic Framework for Multi-objective Drug Discovery
May 14, 2026Advances in large language models (LLMs) have recently opened new and promising avenues for small-molecule drug discovery. Yet existing LLM-based approaches for molecular generation often suffer from high rates of invalid and low-quality ligand candidates, a result of the syntactic limitations of current models with regard to molecular strings. In this paper, we introduce $\texttt{ToolMol}$, an evolutionary agentic framework for de novo drug design. $\texttt{ToolMol}$ combines a multi-objective genetic algorithm with an agentic LLM operator that iteratively updates the ligand population. We build a comprehensive toolbox of RDKit-backed functions that allows our agentic operator to consisently make precise ligand modifications. $\texttt{ToolMol}$ achieves state-of-the-art performance on multi-objective property optimization tasks, discovering drug-like and synthesizable ligands that have $>10\%$ stronger predicted binding affinity compared to existing methods, evaluated on three protein targets. $\texttt{ToolMol}$ ligands additionally achieve state-of-the-art results in gold-standard Absolute Binding Free Energy scores, gaining over existing methods by over $35\%$. By studying chain-of-thought reasoning traces, we observe that tool-calling enables the model to more faithfully execute its planned modifications, efficiently exploiting the strong chemical prior knowledge in LLMs.
Discovering Latent Structural Causal Models from Spatio-Temporal Data
Nov 08, 2024



Many important phenomena in scientific fields such as climate, neuroscience, and epidemiology are naturally represented as spatiotemporal gridded data with complex interactions. For example, in climate science, researchers aim to uncover how large-scale events, such as the North Atlantic Oscillation (NAO) and the Antarctic Oscillation (AAO), influence other global processes. Inferring causal relationships from these data is a challenging problem compounded by the high dimensionality of such data and the correlations between spatially proximate points. We present SPACY (SPAtiotemporal Causal discoverY), a novel framework based on variational inference, designed to explicitly model latent time-series and their causal relationships from spatially confined modes in the data. Our method uses an end-to-end training process that maximizes an evidence-lower bound (ELBO) for the data likelihood. Theoretically, we show that, under some conditions, the latent variables are identifiable up to transformation by an invertible matrix. Empirically, we show that SPACY outperforms state-of-the-art baselines on synthetic data, remains scalable for large grids, and identifies key known phenomena from real-world climate data.
Discovering Mixtures of Structural Causal Models from Time Series Data
Oct 10, 2023



In fields such as finance, climate science, and neuroscience, inferring causal relationships from time series data poses a formidable challenge. While contemporary techniques can handle nonlinear relationships between variables and flexible noise distributions, they rely on the simplifying assumption that data originates from the same underlying causal model. In this work, we relax this assumption and perform causal discovery from time series data originating from mixtures of different causal models. We infer both the underlying structural causal models and the posterior probability for each sample belonging to a specific mixture component. Our approach employs an end-to-end training process that maximizes an evidence-lower bound for data likelihood. Through extensive experimentation on both synthetic and real-world datasets, we demonstrate that our method surpasses state-of-the-art benchmarks in causal discovery tasks, particularly when the data emanates from diverse underlying causal graphs. Theoretically, we prove the identifiability of such a model under some mild assumptions.
Domain Generalization via Inference-time Label-Preserving Target Projections
Mar 01, 2021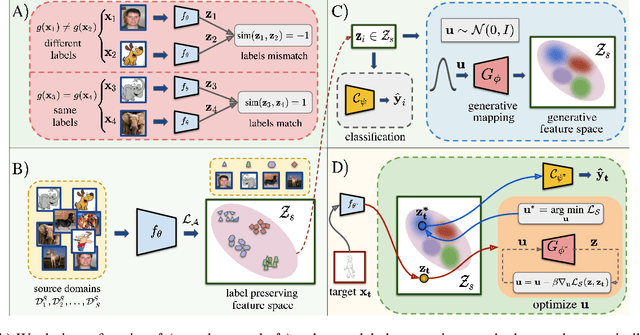
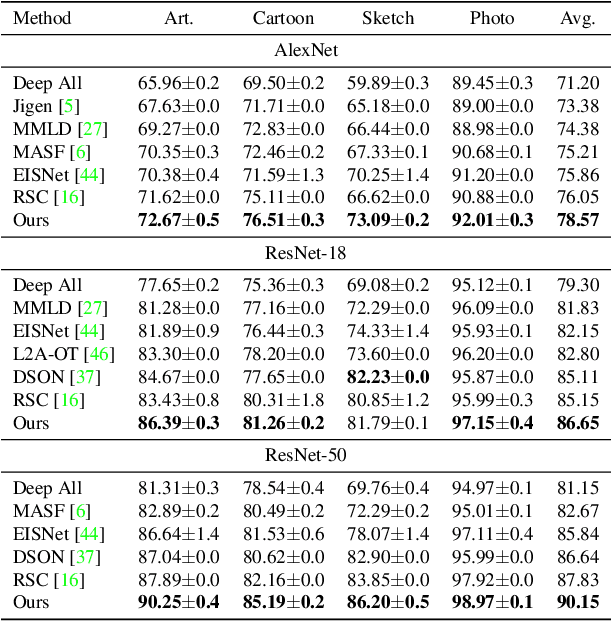
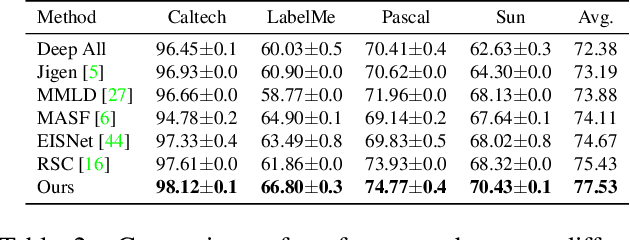
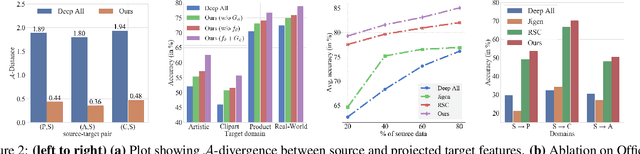
Generalization of machine learning models trained on a set of source domains on unseen target domains with different statistics, is a challenging problem. While many approaches have been proposed to solve this problem, they only utilize source data during training but do not take advantage of the fact that a single target example is available at the time of inference. Motivated by this, we propose a method that effectively uses the target sample during inference beyond mere classification. Our method has three components - (i) A label-preserving feature or metric transformation on source data such that the source samples are clustered in accordance with their class irrespective of their domain (ii) A generative model trained on the these features (iii) A label-preserving projection of the target point on the source-feature manifold during inference via solving an optimization problem on the input space of the generative model using the learned metric. Finally, the projected target is used in the classifier. Since the projected target feature comes from the source manifold and has the same label as the real target by design, the classifier is expected to perform better on it than the true target. We demonstrate that our method outperforms the state-of-the-art Domain Generalization methods on multiple datasets and tasks.
FROCC: Fast Random projection-based One-Class Classification
Nov 29, 2020

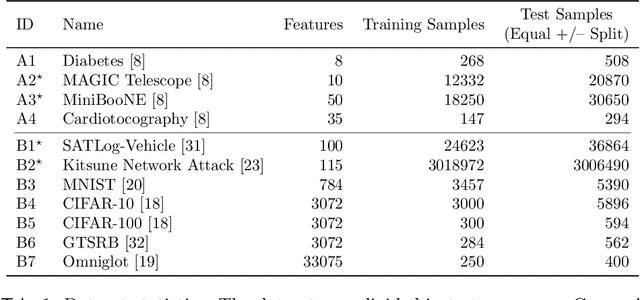

We present Fast Random projection-based One-Class Classification (FROCC), an extremely efficient method for one-class classification. Our method is based on a simple idea of transforming the training data by projecting it onto a set of random unit vectors that are chosen uniformly and independently from the unit sphere, and bounding the regions based on separation of the data. FROCC can be naturally extended with kernels. We theoretically prove that FROCC generalizes well in the sense that it is stable and has low bias. FROCC achieves up to 3.1 percent points better ROC, with 1.2--67.8x speedup in training and test times over a range of state-of-the-art benchmarks including the SVM and the deep learning based models for the OCC task.
Discrepancy Minimization in Domain Generalization with Generative Nearest Neighbors
Jul 28, 2020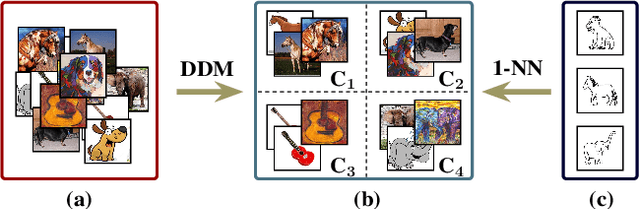
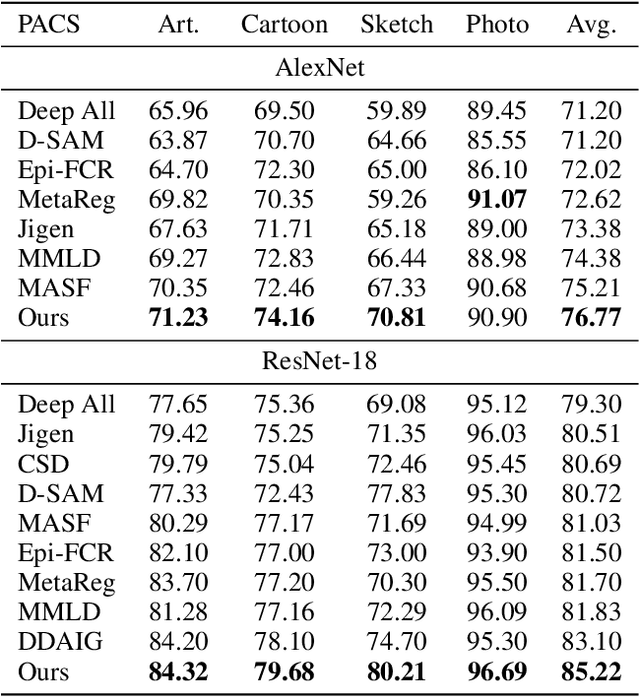

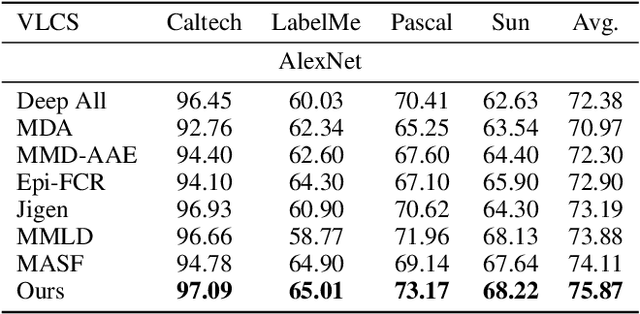
Domain generalization (DG) deals with the problem of domain shift where a machine learning model trained on multiple-source domains fail to generalize well on a target domain with different statistics. Multiple approaches have been proposed to solve the problem of domain generalization by learning domain invariant representations across the source domains that fail to guarantee generalization on the shifted target domain. We propose a Generative Nearest Neighbor based Discrepancy Minimization (GNNDM) method which provides a theoretical guarantee that is upper bounded by the error in the labeling process of the target. We employ a Domain Discrepancy Minimization Network (DDMN) that learns domain agnostic features to produce a single source domain while preserving the class labels of the data points. Features extracted from this source domain are learned using a generative model whose latent space is used as a sampler to retrieve the nearest neighbors for the target data points. The proposed method does not require access to the domain labels (a more realistic scenario) as opposed to the existing approaches. Empirically, we show the efficacy of our method on two datasets: PACS and VLCS. Through extensive experimentation, we demonstrate the effectiveness of the proposed method that outperforms several state-of-the-art DG methods.