 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGSHOT: Few-shot Generative Modeling of Labeled Graphs
Jun 06, 2023Deep graph generative modeling has gained enormous attraction in recent years due to its impressive ability to directly learn the underlying hidden graph distribution. Despite their initial success, these techniques, like much of the existing deep generative methods, require a large number of training samples to learn a good model. Unfortunately, large number of training samples may not always be available in scenarios such as drug discovery for rare diseases. At the same time, recent advances in few-shot learning have opened door to applications where available training data is limited. In this work, we introduce the hitherto unexplored paradigm of few-shot graph generative modeling. Towards this, we develop GSHOT, a meta-learning based framework for few-shot labeled graph generative modeling. GSHOT learns to transfer meta-knowledge from similar auxiliary graph datasets. Utilizing these prior experiences, GSHOT quickly adapts to an unseen graph dataset through self-paced fine-tuning. Through extensive experiments on datasets from diverse domains having limited training samples, we establish that GSHOT generates graphs of superior fidelity compared to existing baselines.
GRAFENNE: Learning on Graphs with Heterogeneous and Dynamic Feature Sets
Jun 06, 2023



Graph neural networks (GNNs), in general, are built on the assumption of a static set of features characterizing each node in a graph. This assumption is often violated in practice. Existing methods partly address this issue through feature imputation. However, these techniques (i) assume uniformity of feature set across nodes, (ii) are transductive by nature, and (iii) fail to work when features are added or removed over time. In this work, we address these limitations through a novel GNN framework called GRAFENNE. GRAFENNE performs a novel allotropic transformation on the original graph, wherein the nodes and features are decoupled through a bipartite encoding. Through a carefully chosen message passing framework on the allotropic transformation, we make the model parameter size independent of the number of features and thereby inductive to both unseen nodes and features. We prove that GRAFENNE is at least as expressive as any of the existing message-passing GNNs in terms of Weisfeiler-Leman tests, and therefore, the additional inductivity to unseen features does not come at the cost of expressivity. In addition, as demonstrated over four real-world graphs, GRAFENNE empowers the underlying GNN with high empirical efficacy and the ability to learn in continual fashion over streaming feature sets.
Embeddings for Tabular Data: A Survey
Feb 23, 2023



Tabular data comprising rows (samples) with the same set of columns (attributes, is one of the most widely used data-type among various industries, including financial services, health care, research, retail, and logistics, to name a few. Tables are becoming the natural way of storing data among various industries and academia. The data stored in these tables serve as an essential source of information for making various decisions. As computational power and internet connectivity increase, the data stored by these companies grow exponentially, and not only do the databases become vast and challenging to maintain and operate, but the quantity of database tasks also increases. Thus a new line of research work has been started, which applies various learning techniques to support various database tasks for such large and complex tables. In this work, we split the quest of learning on tabular data into two phases: The Classical Learning Phase and The Modern Machine Learning Phase. The classical learning phase consists of the models such as SVMs, linear and logistic regression, and tree-based methods. These models are best suited for small-size tables. However, the number of tasks these models can address is limited to classification and regression. In contrast, the Modern Machine Learning Phase contains models that use deep learning for learning latent space representation of table entities. The objective of this survey is to scrutinize the varied approaches used by practitioners to learn representation for the structured data, and to compare their efficacy.
DetAIL : A Tool to Automatically Detect and Analyze Drift In Language
Nov 03, 2022



Machine learning and deep learning-based decision making has become part of today's software. The goal of this work is to ensure that machine learning and deep learning-based systems are as trusted as traditional software. Traditional software is made dependable by following rigorous practice like static analysis, testing, debugging, verifying, and repairing throughout the development and maintenance life-cycle. Similarly for machine learning systems, we need to keep these models up to date so that their performance is not compromised. For this, current systems rely on scheduled re-training of these models as new data kicks in. In this work, we propose to measure the data drift that takes place when new data kicks in so that one can adaptively re-train the models whenever re-training is actually required irrespective of schedules. In addition to that, we generate various explanations at sentence level and dataset level to capture why a given payload text has drifted.
Modeling Spatial Trajectories using Coarse-Grained Smartphone Logs
Aug 29, 2022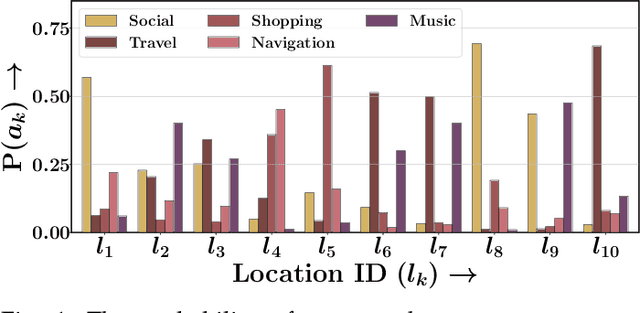

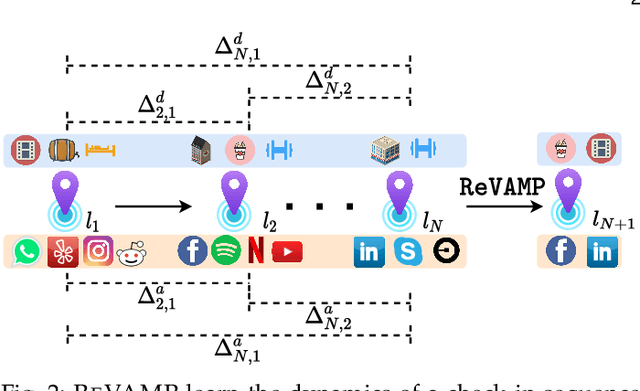
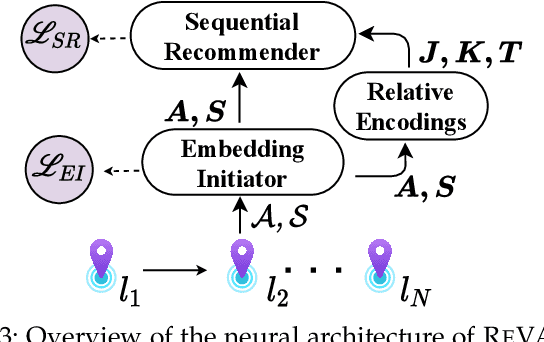
Current approaches for points-of-interest (POI) recommendation learn the preferences of a user via the standard spatial features such as the POI coordinates, the social network, etc. These models ignore a crucial aspect of spatial mobility -- every user carries their smartphones wherever they go. In addition, with growing privacy concerns, users refrain from sharing their exact geographical coordinates and their social media activity. In this paper, we present REVAMP, a sequential POI recommendation approach that utilizes the user activity on smartphone applications (or apps) to identify their mobility preferences. This work aligns with the recent psychological studies of online urban users, which show that their spatial mobility behavior is largely influenced by the activity of their smartphone apps. In addition, our proposal of coarse-grained smartphone data refers to data logs collected in a privacy-conscious manner, i.e., consisting only of (a) category of the smartphone app and (b) category of check-in location. Thus, REVAMP is not privy to precise geo-coordinates, social networks, or the specific application being accessed. Buoyed by the efficacy of self-attention models, we learn the POI preferences of a user using two forms of positional encodings -- absolute and relative -- with each extracted from the inter-check-in dynamics in the check-in sequence of a user. Extensive experiments across two large-scale datasets from China show the predictive prowess of REVAMP and its ability to predict app- and POI categories.
A Survey on Temporal Graph Representation Learning and Generative Modeling
Aug 25, 2022
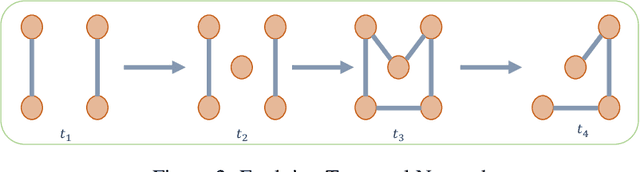
Temporal graphs represent the dynamic relationships among entities and occur in many real life application like social networks, e commerce, communication, road networks, biological systems, and many more. They necessitate research beyond the work related to static graphs in terms of their generative modeling and representation learning. In this survey, we comprehensively review the neural time dependent graph representation learning and generative modeling approaches proposed in recent times for handling temporal graphs. Finally, we identify the weaknesses of existing approaches and discuss the research proposal of our recently published paper TIGGER[24].
Modeling Continuous Time Sequences with Intermittent Observations using Marked Temporal Point Processes
Jun 23, 2022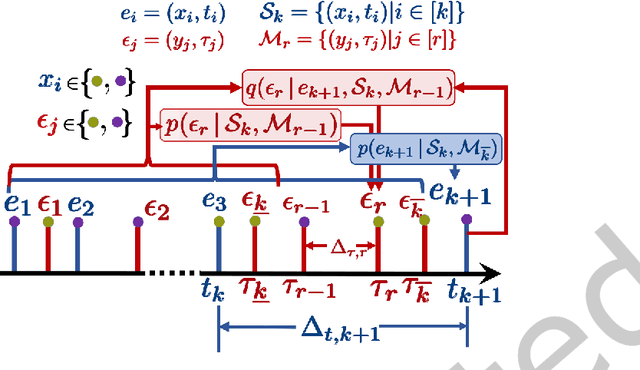

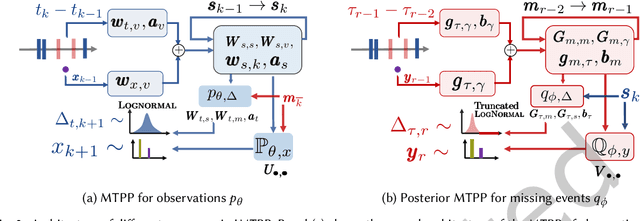
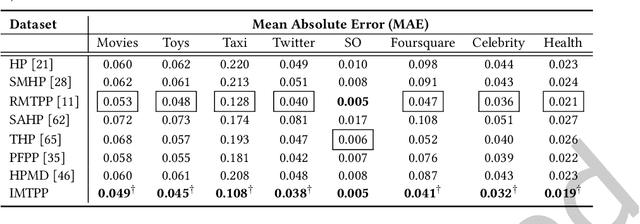
A large fraction of data generated via human activities such as online purchases, health records, spatial mobility etc. can be represented as a sequence of events over a continuous-time. Learning deep learning models over these continuous-time event sequences is a non-trivial task as it involves modeling the ever-increasing event timestamps, inter-event time gaps, event types, and the influences between different events within and across different sequences. In recent years neural enhancements to marked temporal point processes (MTPP) have emerged as a powerful framework to model the underlying generative mechanism of asynchronous events localized in continuous time. However, most existing models and inference methods in the MTPP framework consider only the complete observation scenario i.e. the event sequence being modeled is completely observed with no missing events -- an ideal setting that is rarely applicable in real-world applications. A recent line of work which considers missing events while training MTPP utilizes supervised learning techniques that require additional knowledge of missing or observed label for each event in a sequence, which further restricts its practicability as in several scenarios the details of missing events is not known apriori. In this work, we provide a novel unsupervised model and inference method for learning MTPP in presence of event sequences with missing events. Specifically, we first model the generative processes of observed events and missing events using two MTPP, where the missing events are represented as latent random variables. Then, we devise an unsupervised training method that jointly learns both the MTPP by means of variational inference. Such a formulation can effectively impute the missing data among the observed events and can identify the optimal position of missing events in a sequence.
Plug and Play Counterfactual Text Generation for Model Robustness
Jun 21, 2022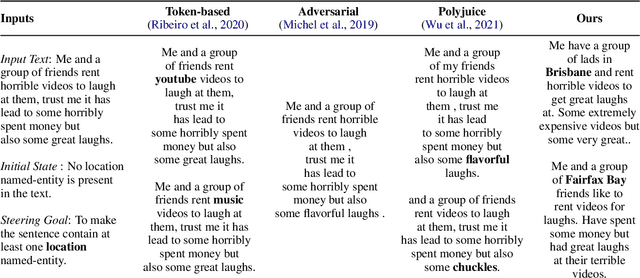
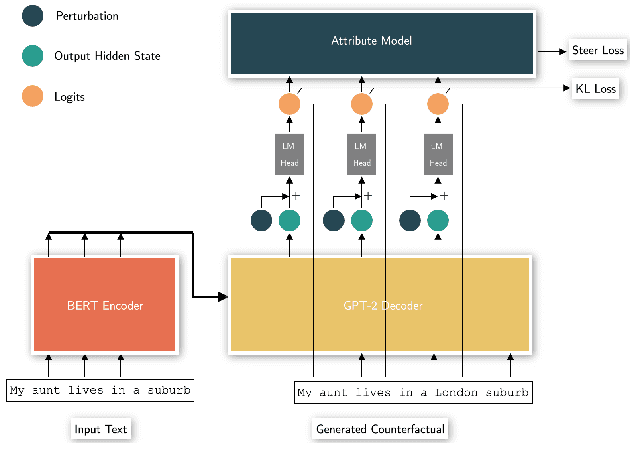


Generating counterfactual test-cases is an important backbone for testing NLP models and making them as robust and reliable as traditional software. In generating the test-cases, a desired property is the ability to control the test-case generation in a flexible manner to test for a large variety of failure cases and to explain and repair them in a targeted manner. In this direction, significant progress has been made in the prior works by manually writing rules for generating controlled counterfactuals. However, this approach requires heavy manual supervision and lacks the flexibility to easily introduce new controls. Motivated by the impressive flexibility of the plug-and-play approach of PPLM, we propose bringing the framework of plug-and-play to counterfactual test case generation task. We introduce CASPer, a plug-and-play counterfactual generation framework to generate test cases that satisfy goal attributes on demand. Our plug-and-play model can steer the test case generation process given any attribute model without requiring attribute-specific training of the model. In experiments, we show that CASPer effectively generates counterfactual text that follow the steering provided by an attribute model while also being fluent, diverse and preserving the original content. We also show that the generated counterfactuals from CASPer can be used for augmenting the training data and thereby fixing and making the test model more robust.
TransDrift: Modeling Word-Embedding Drift using Transformer
Jun 16, 2022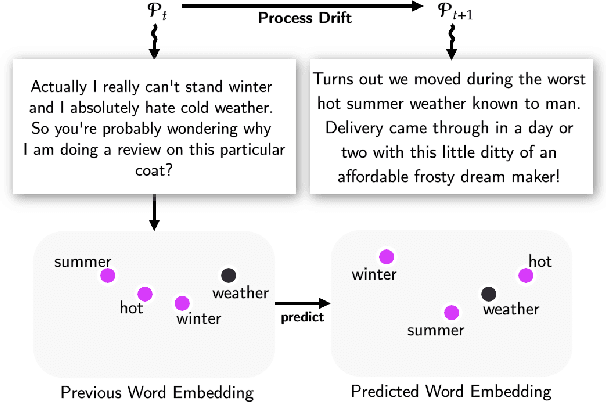
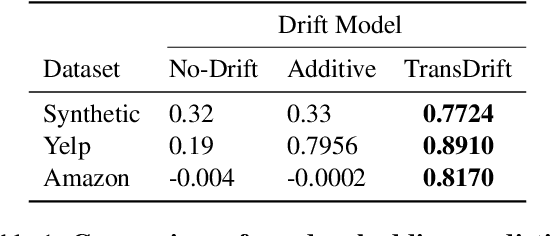
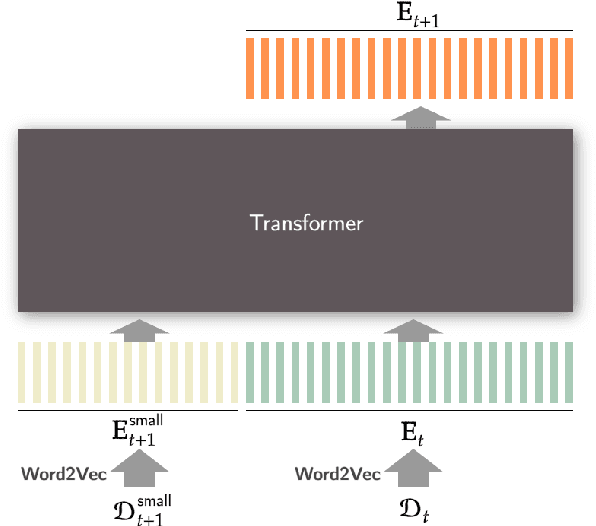
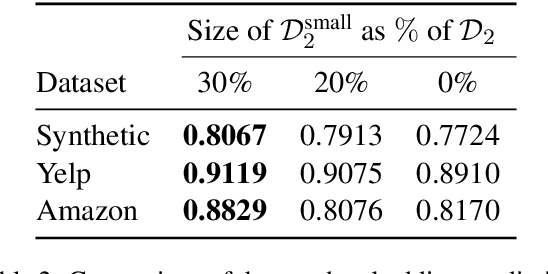
In modern NLP applications, word embeddings are a crucial backbone that can be readily shared across a number of tasks. However as the text distributions change and word semantics evolve over time, the downstream applications using the embeddings can suffer if the word representations do not conform to the data drift. Thus, maintaining word embeddings to be consistent with the underlying data distribution is a key problem. In this work, we tackle this problem and propose TransDrift, a transformer-based prediction model for word embeddings. Leveraging the flexibility of transformer, our model accurately learns the dynamics of the embedding drift and predicts the future embedding. In experiments, we compare with existing methods and show that our model makes significantly more accurate predictions of the word embedding than the baselines. Crucially, by applying the predicted embeddings as a backbone for downstream classification tasks, we show that our embeddings lead to superior performance compared to the previous methods.
ProActive: Self-Attentive Temporal Point Process Flows for Activity Sequences
Jun 10, 2022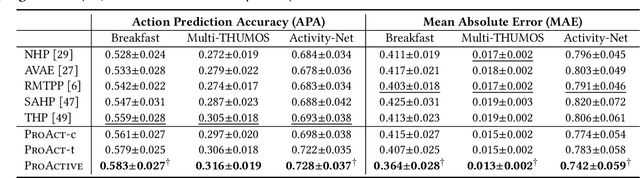
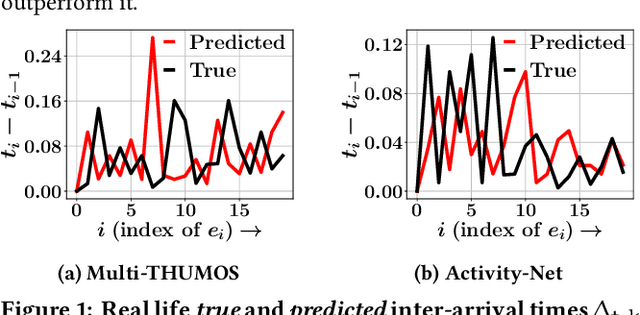
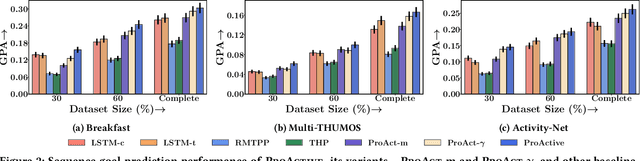
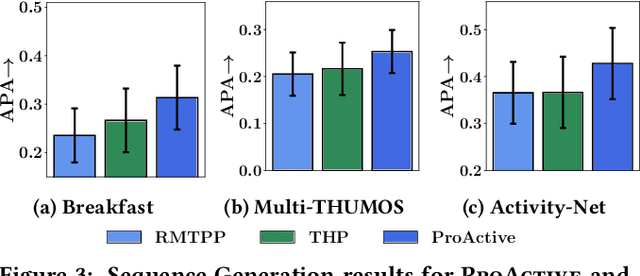
Any human activity can be represented as a temporal sequence of actions performed to achieve a certain goal. Unlike machine-made time series, these action sequences are highly disparate as the time taken to finish a similar action might vary between different persons. Therefore, understanding the dynamics of these sequences is essential for many downstream tasks such as activity length prediction, goal prediction, etc. Existing neural approaches that model an activity sequence are either limited to visual data or are task specific, i.e., limited to next action or goal prediction. In this paper, we present ProActive, a neural marked temporal point process (MTPP) framework for modeling the continuous-time distribution of actions in an activity sequence while simultaneously addressing three high-impact problems -- next action prediction, sequence-goal prediction, and end-to-end sequence generation. Specifically, we utilize a self-attention module with temporal normalizing flows to model the influence and the inter-arrival times between actions in a sequence. Moreover, for time-sensitive prediction, we perform an early detection of sequence goal via a constrained margin-based optimization procedure. This in-turn allows ProActive to predict the sequence goal using a limited number of actions. Extensive experiments on sequences derived from three activity recognition datasets show the significant accuracy boost of ProActive over the state-of-the-art in terms of action and goal prediction, and the first-ever application of end-to-end action sequence generation.