 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating "Epistemic Debt" in Generative AI-Scaffolded Novice Programming using Metacognitive Scripts
Feb 22, 2026The democratization of Large Language Models (LLMs) has given rise to ``Vibe Coding," a workflow where novice programmers prioritize semantic intent over syntactic implementation. While this lowers barriers to entry, we hypothesize that without pedagogical guardrails, it is fundamentally misaligned with cognitive skill acquisition. Drawing on the distinction between Cognitive Offloading and Cognitive Outsourcing, we argue that unrestricted AI encourages novices to outsource the Intrinsic Cognitive Load required for schema formation, rather than merely offloading Extraneous Load. This accumulation of ``Epistemic Debt" creates ``Fragile Experts" whose high functional utility masks critically low corrective competence. To quantify and mitigate this debt, we conducted a between-subjects experiment (N=78) using a custom Cursor IDE plugin backed by Claude 3.5 Sonnet. Participants represented "AI-Native" learners across three conditions: Manual (Control), Unrestricted AI (Outsourcing), and Scaffolded AI (Offloading). The Scaffolded condition utilized a novel ``Explanation Gate," leveraging a real-time LLM-as-a-Judge framework to enforce a ``Teach-Back" protocol before generated code could be integrated. Results reveal a ``Collapse of Competence": while Unrestricted AI users matched the productivity of the Scaffolded group (p < .001 vs. Manual), they suffered a 77% failure rate in a subsequent AI-Blackout maintenance task, compared to only 39% in the Scaffolded group. Qualitative analysis suggests that successful vibe coders naturally engage in self-scaffolding, treating the AI as a consultant rather than a contractor. We discuss the implications for the maintainability of AI-generated software and propose that future learning systems must enforce Metacognitive Friction to prevent the mass production of unmaintainable code.
Disagreement as Data: Reasoning Trace Analytics in Multi-Agent Systems
Jan 18, 2026Learning analytics researchers often analyze qualitative student data such as coded annotations or interview transcripts to understand learning processes. With the rise of generative AI, fully automated and human-AI workflows have emerged as promising methods for analysis. However, methodological standards to guide such workflows remain limited. In this study, we propose that reasoning traces generated by large language model (LLM) agents, especially within multi-agent systems, constitute a novel and rich form of process data to enhance interpretive practices in qualitative coding. We apply cosine similarity to LLM reasoning traces to systematically detect, quantify, and interpret disagreements among agents, reframing disagreement as a meaningful analytic signal. Analyzing nearly 10,000 instances of agent pairs coding human tutoring dialog segments, we show that LLM agents' semantic reasoning similarity robustly differentiates consensus from disagreement and correlates with human coding reliability. Qualitative analysis guided by this metric reveals nuanced instructional sub-functions within codes and opportunities for conceptual codebook refinement. By integrating quantitative similarity metrics with qualitative review, our method has the potential to improve and accelerate establishing inter-rater reliability during coding by surfacing interpretive ambiguity, especially when LLMs collaborate with humans. We discuss how reasoning-trace disagreements represent a valuable new class of analytic signals advancing methodological rigor and interpretive depth in educational research.
Combining Model-Free Q-Ensembles and Model-Based Approaches for Informed Exploration
Jun 12, 2018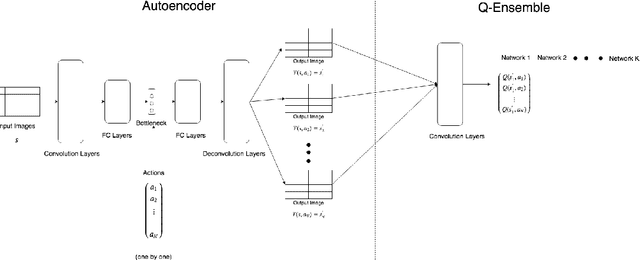
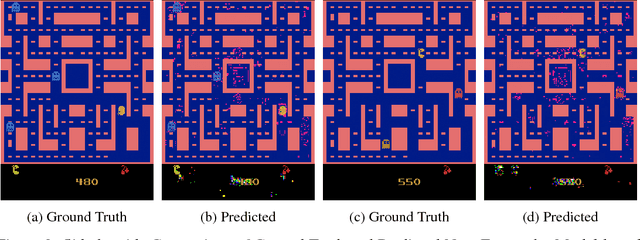
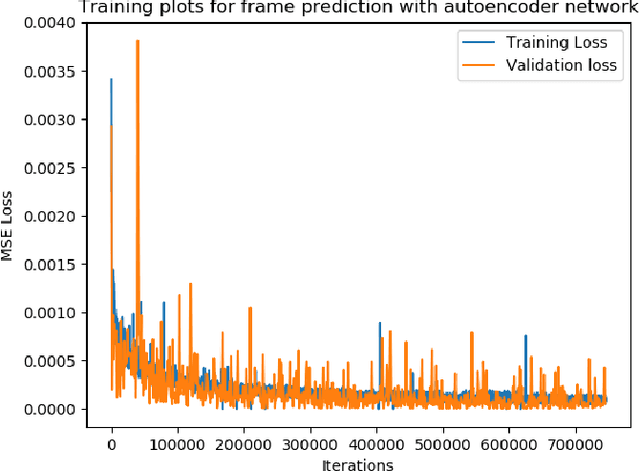
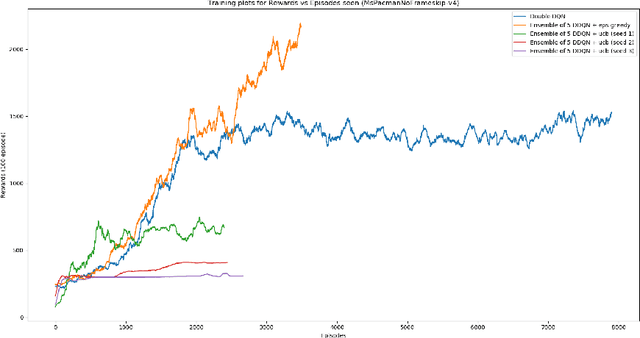
Q-Ensembles are a model-free approach where input images are fed into different Q-networks and exploration is driven by the assumption that uncertainty is proportional to the variance of the output Q-values obtained. They have been shown to perform relatively well compared to other exploration strategies. Further, model-based approaches, such as encoder-decoder models have been used successfully for next frame prediction given previous frames. This paper proposes to integrate the model-free Q-ensembles and model-based approaches with the hope of compounding the benefits of both and achieving superior exploration as a result. Results show that a model-based trajectory memory approach when combined with Q-ensembles produces superior performance when compared to only using Q-ensembles.
Coordinating Collaborative Chat in Massive Open Online Courses
Apr 18, 2017
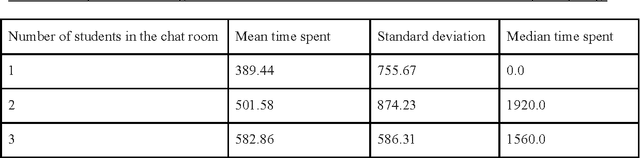
An earlier study of a collaborative chat intervention in a Massive Open Online Course (MOOC) identified negative effects on attrition stemming from a requirement for students to be matched with exactly one partner prior to beginning the activity. That study raised questions about how to orchestrate a collaborative chat intervention in a MOOC context in order to provide the benefit of synchronous social engagement without the coordination difficulties. In this paper we present a careful analysis of an intervention designed to overcome coordination difficulties by welcoming students into the chat on a rolling basis as they arrive rather than requiring them to be matched with a partner before beginning. The results suggest the most positive impact when experiencing a chat with exactly one partner rather than more or less. A qualitative analysis of the chat data reveals differential experiences between these configurations that suggests a potential explanation for the effect and raises questions for future research.
* 8 pages