 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable End-to-End Training of Knowledge Graph-Enhanced Aspect Embedding for Aspect Level Sentiment Analysis
Aug 26, 2021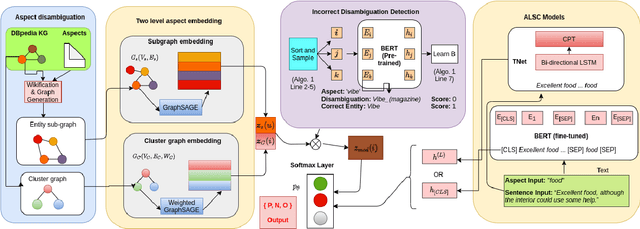

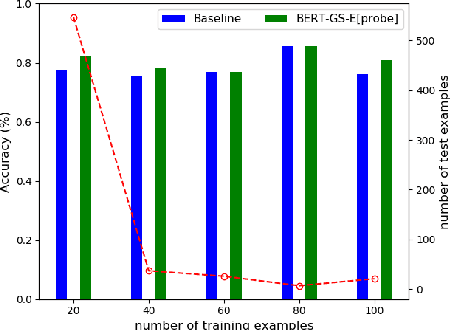
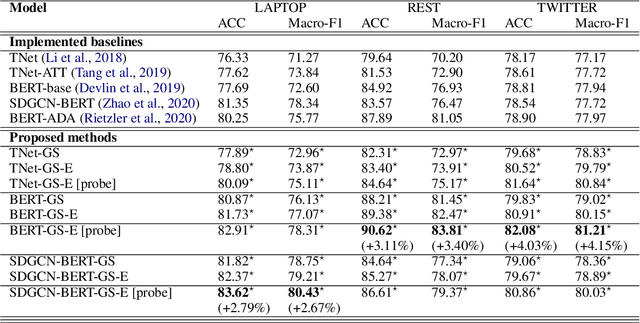
Aspect level sentiment classification (ALSC) is a difficult problem with state-of-the-art models showing less than 80% macro-F1 score on benchmark datasets. Existing models do not incorporate information on aspect-aspect relations in knowledge graphs (KGs), e.g. DBpedia. Two main challenges stem from inaccurate disambiguation of aspects to KG entities, and the inability to learn aspect representations from the large KGs in joint training with ALSC models. We propose a two-level global-local entity embedding scheme that allows efficient joint training of KG-based aspect embeddings and ALSC models. A novel incorrect disambiguation detection technique addresses the problem of inaccuracy in aspect disambiguation. The proposed methods show a consistent improvement of $2.5 - 4.1$ percentage points, over the recent BERT-based baselines.
Finding High-Value Training Data Subset through Differentiable Convex Programming
Apr 28, 2021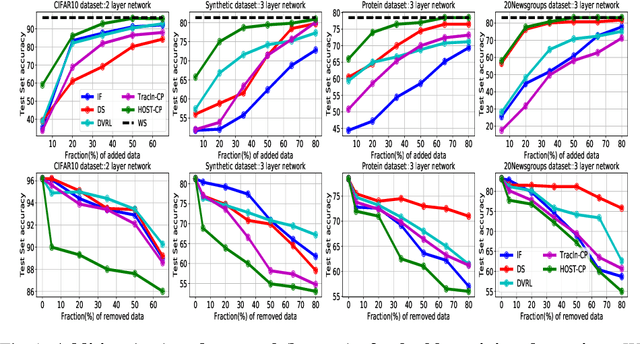
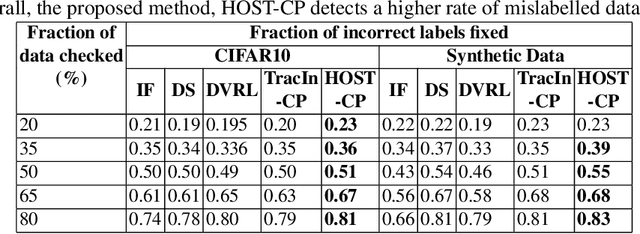
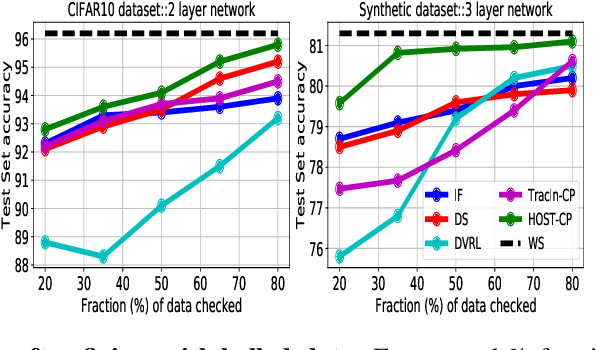

Finding valuable training data points for deep neural networks has been a core research challenge with many applications. In recent years, various techniques for calculating the "value" of individual training datapoints have been proposed for explaining trained models. However, the value of a training datapoint also depends on other selected training datapoints - a notion that is not explicitly captured by existing methods. In this paper, we study the problem of selecting high-value subsets of training data. The key idea is to design a learnable framework for online subset selection, which can be learned using mini-batches of training data, thus making our method scalable. This results in a parameterized convex subset selection problem that is amenable to a differentiable convex programming paradigm, thus allowing us to learn the parameters of the selection model in end-to-end training. Using this framework, we design an online alternating minimization-based algorithm for jointly learning the parameters of the selection model and ML model. Extensive evaluation on a synthetic dataset, and three standard datasets, show that our algorithm finds consistently higher value subsets of training data, compared to the recent state-of-the-art methods, sometimes ~20% higher value than existing methods. The subsets are also useful in finding mislabelled training data. Our algorithm takes running time comparable to the existing valuation functions.
Convex Online Video Frame Subset Selection using Multiple Criteria for Data Efficient Autonomous Driving
Mar 24, 2021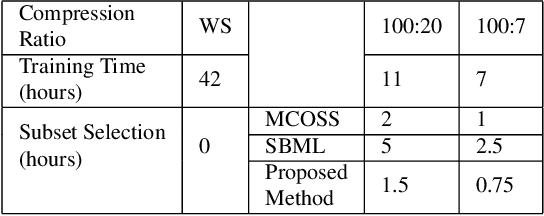
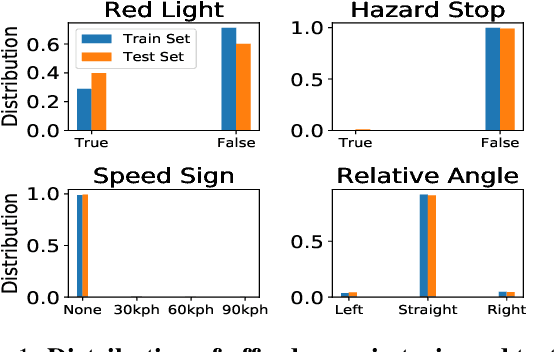
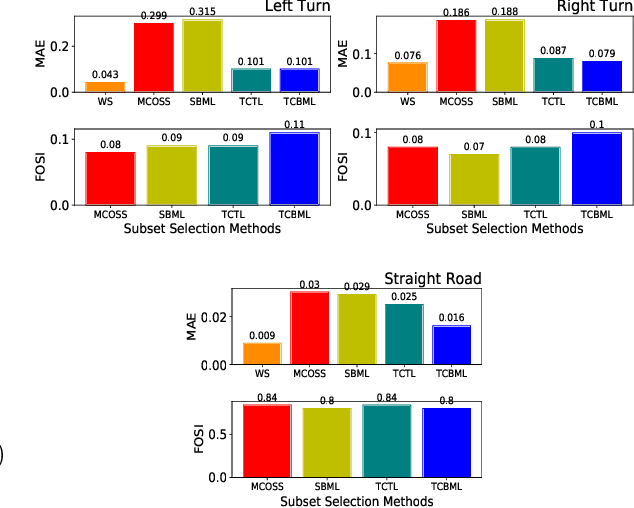
Training vision-based Urban Autonomous driving models is a challenging problem, which is highly researched in recent times. Training such models is a data-intensive task requiring the storage and processing of vast volumes of (possibly redundant) driving video data. In this paper, we study the problem of developing data-efficient autonomous driving systems. In this context, we study the problem of multi-criteria online video frame subset selection. We study convex optimization-based solutions and show that they are unable to provide solutions with high weightage to the loss of selected video frames. We design a novel convex optimization-based multi-criteria online subset selection algorithm that uses a thresholded concave function of selection variables. We also propose and study a submodular optimization-based algorithm. Extensive experiments using the driving simulator CARLA show that we are able to drop 80% of the frames while succeeding to complete 100% of the episodes w.r.t. the model trained on 100% data, in the most difficult task of taking turns. This results in a training time of less than 30% compared to training on the whole dataset. We also perform detailed experiments on prediction performances of various affordances used by the Conditional Affordance Learning (CAL) model and show that our subset selection improves performance on the crucial affordance "Relative Angle" during turns.
Demarcating Endogenous and Exogenous Opinion Dynamics: An Experimental Design Approach
Feb 11, 2021
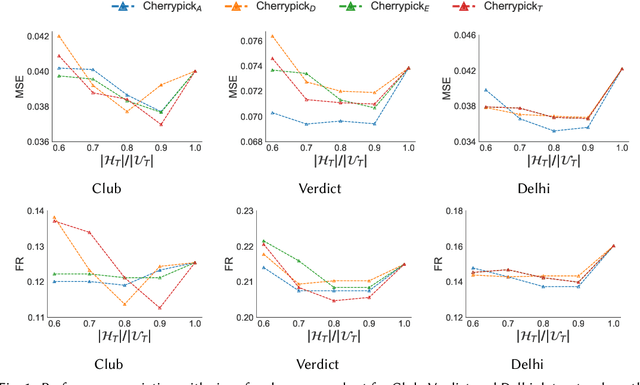
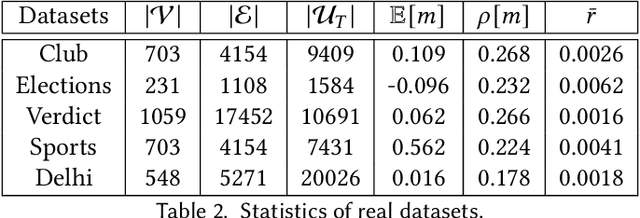
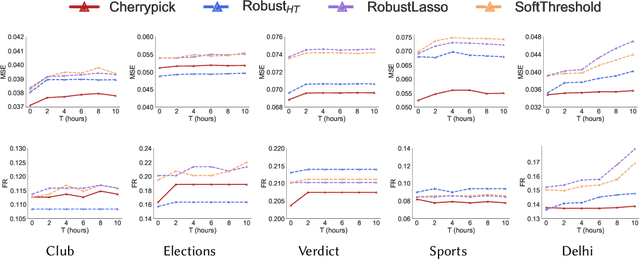
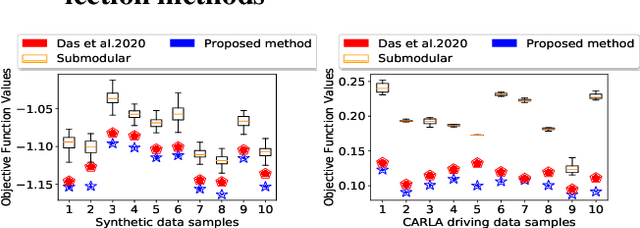
The networked opinion diffusion in online social networks (OSN) is often governed by the two genres of opinions - endogenous opinions that are driven by the influence of social contacts among users, and exogenous opinions which are formed by external effects like news, feeds etc. Accurate demarcation of endogenous and exogenous messages offers an important cue to opinion modeling, thereby enhancing its predictive performance. In this paper, we design a suite of unsupervised classification methods based on experimental design approaches, in which, we aim to select the subsets of events which minimize different measures of mean estimation error. In more detail, we first show that these subset selection tasks are NP-Hard. Then we show that the associated objective functions are weakly submodular, which allows us to cast efficient approximation algorithms with guarantees. Finally, we validate the efficacy of our proposal on various real-world datasets crawled from Twitter as well as diverse synthetic datasets. Our experiments range from validating prediction performance on unsanitized and sanitized events to checking the effect of selecting optimal subsets of various sizes. Through various experiments, we have found that our method offers a significant improvement in accuracy in terms of opinion forecasting, against several competitors.
* 25 Pages, Accepted in ACM TKDD, 2021
Scalable Backdoor Detection in Neural Networks
Jun 10, 2020
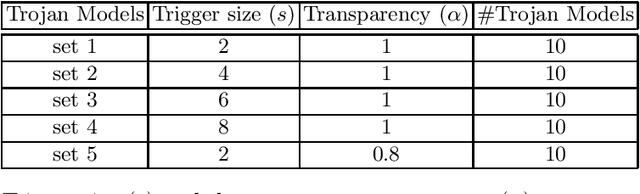
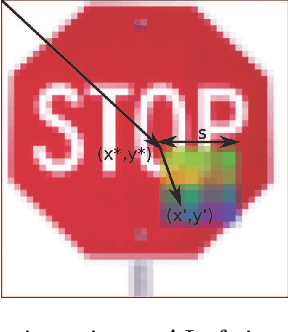

Recently, it has been shown that deep learning models are vulnerable to Trojan attacks, where an attacker can install a backdoor during training time to make the resultant model misidentify samples contaminated with a small trigger patch. Current backdoor detection methods fail to achieve good detection performance and are computationally expensive. In this paper, we propose a novel trigger reverse-engineering based approach whose computational complexity does not scale with the number of labels, and is based on a measure that is both interpretable and universal across different network and patch types. In experiments, we observe that our method achieves a perfect score in separating Trojaned models from pure models, which is an improvement over the current state-of-the art method.
Read what you need: Controllable Aspect-based Opinion Summarization of Tourist Reviews
Jun 09, 2020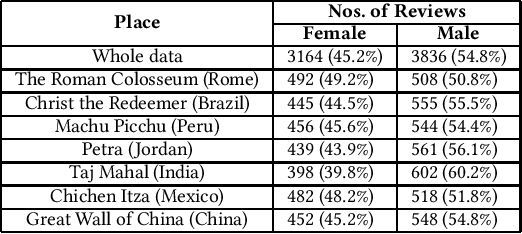
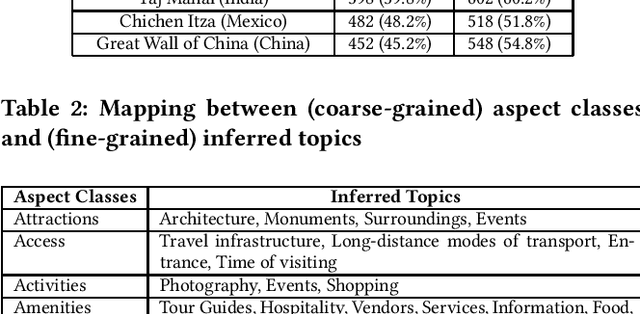
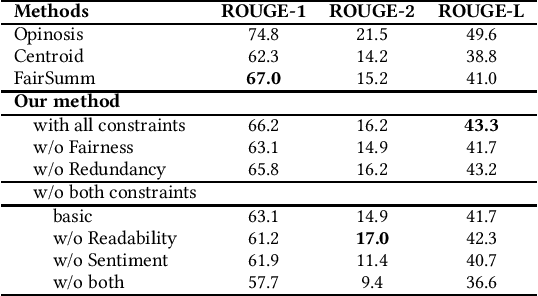
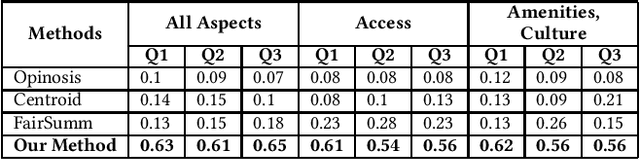
Manually extracting relevant aspects and opinions from large volumes of user-generated text is a time-consuming process. Summaries, on the other hand, help readers with limited time budgets to quickly consume the key ideas from the data. State-of-the-art approaches for multi-document summarization, however, do not consider user preferences while generating summaries. In this work, we argue the need and propose a solution for generating personalized aspect-based opinion summaries from large collections of online tourist reviews. We let our readers decide and control several attributes of the summary such as the length and specific aspects of interest among others. Specifically, we take an unsupervised approach to extract coherent aspects from tourist reviews posted on TripAdvisor. We then propose an Integer Linear Programming (ILP) based extractive technique to select an informative subset of opinions around the identified aspects while respecting the user-specified values for various control parameters. Finally, we evaluate and compare our summaries using crowdsourcing and ROUGE-based metrics and obtain competitive results.
Map Enhanced Route Travel Time Prediction using Deep Neural Networks
Nov 06, 2019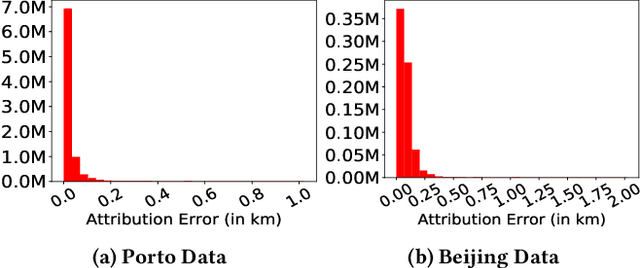
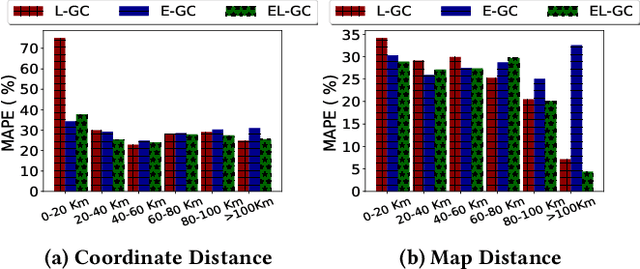
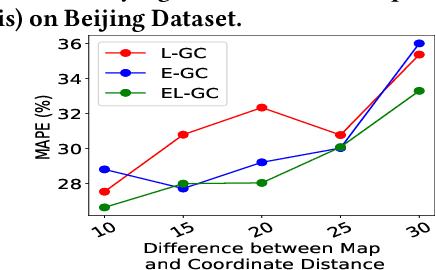
Travel time estimation is a fundamental problem in transportation science with extensive literature. The study of these techniques has intensified due to availability of many publicly available large trip datasets. Recently developed deep learning based models have improved the generality and performance and have focused on estimating times for individual sub-trajectories and aggregating them to predict the travel time of the entire trajectory. However, these techniques ignore the road network information. In this work, we propose and study techniques for incorporating road networks along with historical trips' data into travel time prediction. We incorporate both node embeddings as well as road distance into the existing model. Experiments on large real-world benchmark datasets suggest improved performance, especially when the train data is small. As expected, the proposed method performs better than the baseline when there is a larger difference between road distance and Vincenty distance between start and end points.
A Methodology for Customizing Clinical Tests for Esophageal Cancer based on Patient Preferences
Oct 06, 2016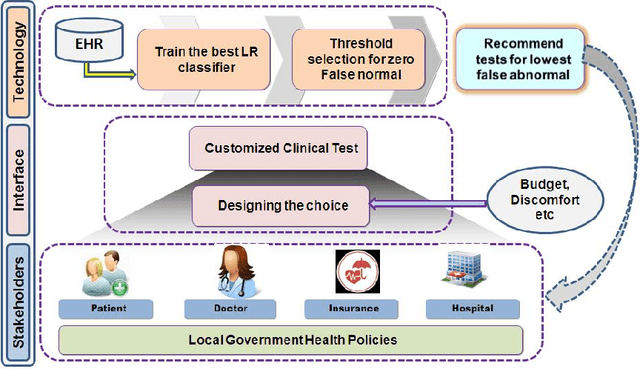
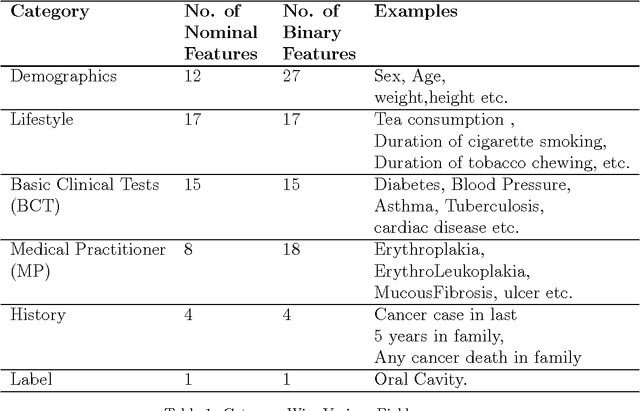
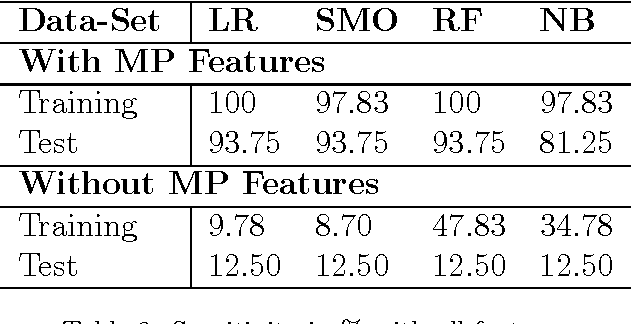
Tests for Esophageal cancer can be expensive, uncomfortable and can have side effects. For many patients, we can predict non-existence of disease with 100% certainty, just using demographics, lifestyle, and medical history information. Our objective is to devise a general methodology for customizing tests using user preferences so that expensive or uncomfortable tests can be avoided. We propose to use classifiers trained from electronic health records (EHR) for selection of tests. The key idea is to design classifiers with 100% false normal rates, possibly at the cost higher false abnormals. We compare Naive Bayes classification (NB), Random Forests (RF), Support Vector Machines (SVM) and Logistic Regression (LR), and find kernel Logistic regression to be most suitable for the task. We propose an algorithm for finding the best probability threshold for kernel LR, based on test set accuracy. Using the proposed algorithm, we describe schemes for selecting tests, which appear as features in the automatic classification algorithm, using preferences on costs and discomfort of the users. We test our methodology with EHRs collected for more than 3000 patients, as a part of project carried out by a reputed hospital in Mumbai, India. Kernel SVM and kernel LR with a polynomial kernel of degree 3, yields an accuracy of 99.8% and sensitivity 100%, without the MP features, i.e. using only clinical tests. We demonstrate our test selection algorithm using two case studies, one using cost of clinical tests, and other using "discomfort" values for clinical tests. We compute the test sets corresponding to the lowest false abnormals for each criterion described above, using exhaustive enumeration of 15 clinical tests. The sets turn out to different, substantiating our claim that one can customize test sets based on user preferences.
Distributed Weighted Parameter Averaging for SVM Training on Big Data
Sep 30, 2015
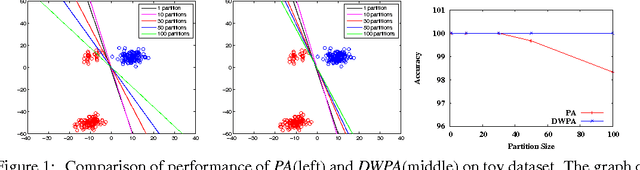
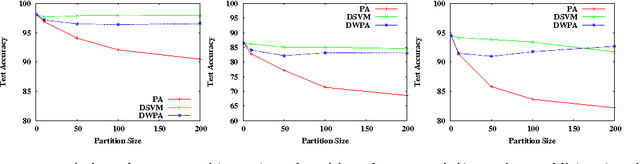
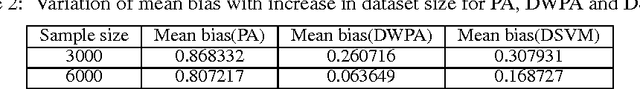
Two popular approaches for distributed training of SVMs on big data are parameter averaging and ADMM. Parameter averaging is efficient but suffers from loss of accuracy with increase in number of partitions, while ADMM in the feature space is accurate but suffers from slow convergence. In this paper, we report a hybrid approach called weighted parameter averaging (WPA), which optimizes the regularized hinge loss with respect to weights on parameters. The problem is shown to be same as solving SVM in a projected space. We also demonstrate an $O(\frac{1}{N})$ stability bound on final hypothesis given by WPA, using novel proof techniques. Experimental results on a variety of toy and real world datasets show that our approach is significantly more accurate than parameter averaging for high number of partitions. It is also seen the proposed method enjoys much faster convergence compared to ADMM in features space.
Mechanism Design for Cost Optimal PAC Learning in the Presence of Strategic Noisy Annotators
Oct 16, 2012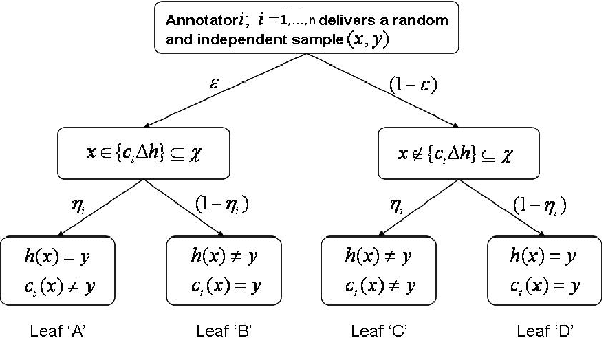
We consider the problem of Probably Approximate Correct (PAC) learning of a binary classifier from noisy labeled examples acquired from multiple annotators (each characterized by a respective classification noise rate). First, we consider the complete information scenario, where the learner knows the noise rates of all the annotators. For this scenario, we derive sample complexity bound for the Minimum Disagreement Algorithm (MDA) on the number of labeled examples to be obtained from each annotator. Next, we consider the incomplete information scenario, where each annotator is strategic and holds the respective noise rate as a private information. For this scenario, we design a cost optimal procurement auction mechanism along the lines of Myerson's optimal auction design framework in a non-trivial manner. This mechanism satisfies incentive compatibility property, thereby facilitating the learner to elicit true noise rates of all the annotators.