 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Optimization of Rank-One Functions with Indicator Variables
Mar 31, 2023



Optimization problems involving minimization of a rank-one convex function over constraints modeling restrictions on the support of the decision variables emerge in various machine learning applications. These problems are often modeled with indicator variables for identifying the support of the continuous variables. In this paper we investigate compact extended formulations for such problems through perspective reformulation techniques. In contrast to the majority of previous work that relies on support function arguments and disjunctive programming techniques to provide convex hull results, we propose a constructive approach that exploits a hidden conic structure induced by perspective functions. To this end, we first establish a convex hull result for a general conic mixed-binary set in which each conic constraint involves a linear function of independent continuous variables and a set of binary variables. We then demonstrate that extended representations of sets associated with epigraphs of rank-one convex functions over constraints modeling indicator relations naturally admit such a conic representation. This enables us to systematically give perspective formulations for the convex hull descriptions of these sets with nonlinear separable or non-separable objective functions, sign constraints on continuous variables, and combinatorial constraints on indicator variables. We illustrate the efficacy of our results on sparse nonnegative logistic regression problems.
New Perspectives on Regularization and Computation in Optimal Transport-Based Distributionally Robust Optimization
Mar 07, 2023We study optimal transport-based distributionally robust optimization problems where a fictitious adversary, often envisioned as nature, can choose the distribution of the uncertain problem parameters by reshaping a prescribed reference distribution at a finite transportation cost. In this framework, we show that robustification is intimately related to various forms of variation and Lipschitz regularization even if the transportation cost function fails to be (some power of) a metric. We also derive conditions for the existence and the computability of a Nash equilibrium between the decision-maker and nature, and we demonstrate numerically that nature's Nash strategy can be viewed as a distribution that is supported on remarkably deceptive adversarial samples. Finally, we identify practically relevant classes of optimal transport-based distributionally robust optimization problems that can be addressed with efficient gradient descent algorithms even if the loss function or the transportation cost function are nonconvex (but not both at the same time).
The Performance of Wasserstein Distributionally Robust M-Estimators in High Dimensions
Jun 27, 2022Wasserstein distributionally robust optimization has recently emerged as a powerful framework for robust estimation, enjoying good out-of-sample performance guarantees, well-understood regularization effects, and computationally tractable dual reformulations. In such framework, the estimator is obtained by minimizing the worst-case expected loss over all probability distributions which are close, in a Wasserstein sense, to the empirical distribution. In this paper, we propose a Wasserstein distributionally robust M-estimation framework to estimate an unknown parameter from noisy linear measurements, and we focus on the important and challenging task of analyzing the squared error performance of such estimators. Our study is carried out in the modern high-dimensional proportional regime, where both the ambient dimension and the number of samples go to infinity, at a proportional rate which encodes the under/over-parametrization of the problem. Under an isotropic Gaussian features assumption, we show that the squared error can be recover as the solution of a convex-concave optimization problem which, surprinsingly, involves at most four scalar variables. To the best of our knowledge, this is the first work to study this problem in the context of Wasserstein distributionally robust M-estimation.
Discrete Optimal Transport with Independent Marginals is #P-Hard
Mar 02, 2022We study the computational complexity of the optimal transport problem that evaluates the Wasserstein distance between the distributions of two K-dimensional discrete random vectors. The best known algorithms for this problem run in polynomial time in the maximum of the number of atoms of the two distributions. However, if the components of either random vector are independent, then this number can be exponential in K even though the size of the problem description scales linearly with K. We prove that the described optimal transport problem is #P-hard even if all components of the first random vector are independent uniform Bernoulli random variables, while the second random vector has merely two atoms, and even if only approximate solutions are sought. We also develop a dynamic programming-type algorithm that approximates the Wasserstein distance in pseudo-polynomial time when the components of the first random vector follow arbitrary independent discrete distributions, and we identify special problem instances that can be solved exactly in strongly polynomial time.
Semi-Discrete Optimal Transport: Hardness, Regularization and Numerical Solution
Mar 10, 2021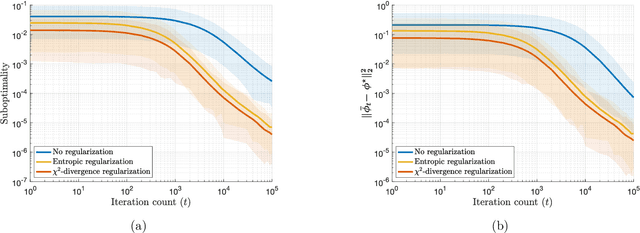
Semi-discrete optimal transport problems, which evaluate the Wasserstein distance between a discrete and a generic (possibly non-discrete) probability measure, are believed to be computationally hard. Even though such problems are ubiquitous in statistics, machine learning and computer vision, however, this perception has not yet received a theoretical justification. To fill this gap, we prove that computing the Wasserstein distance between a discrete probability measure supported on two points and the Lebesgue measure on the standard hypercube is already #P-hard. This insight prompts us to seek approximate solutions for semi-discrete optimal transport problems. We thus perturb the underlying transportation cost with an additive disturbance governed by an ambiguous probability distribution, and we introduce a distributionally robust dual optimal transport problem whose objective function is smoothed with the most adverse disturbance distributions from within a given ambiguity set. We further show that smoothing the dual objective function is equivalent to regularizing the primal objective function, and we identify several ambiguity sets that give rise to several known and new regularization schemes. As a byproduct, we discover an intimate relation between semi-discrete optimal transport problems and discrete choice models traditionally studied in psychology and economics. To solve the regularized optimal transport problems efficiently, we use a stochastic gradient descent algorithm with imprecise stochastic gradient oracles. A new convergence analysis reveals that this algorithm improves the best known convergence guarantee for semi-discrete optimal transport problems with entropic regularizers.
Bridging Bayesian and Minimax Mean Square Error Estimation via Wasserstein Distributionally Robust Optimization
Nov 08, 2019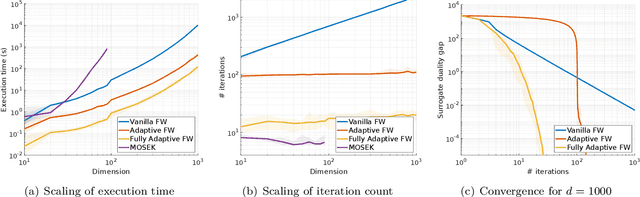
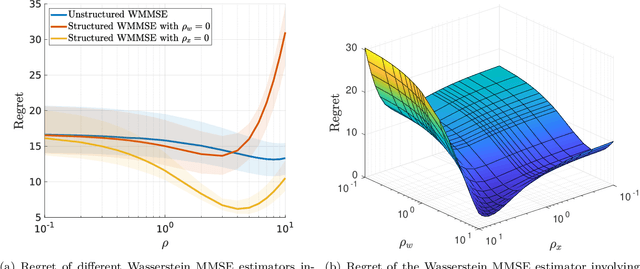
We introduce a distributionally robust minimium mean square error estimation model with a Wasserstein ambiguity set to recover an unknown signal from a noisy observation. The proposed model can be viewed as a zero-sum game between a statistician choosing an estimator---that is, a measurable function of the observation---and a fictitious adversary choosing a prior---that is, a pair of signal and noise distributions ranging over independent Wasserstein balls---with the goal to minimize and maximize the expected squared estimation error, respectively. We show that if the Wasserstein balls are centered at normal distributions, then the zero-sum game admits a Nash equilibrium, where the players' optimal strategies are given by an {\em affine} estimator and a {\em normal} prior, respectively. We further prove that this Nash equilibrium can be computed by solving a tractable convex program. Finally, we develop a Frank-Wolfe algorithm that can solve this convex program orders of magnitude faster than state-of-the-art general purpose solvers. We show that this algorithm enjoys a linear convergence rate and that its direction-finding subproblems can be solved in quasi-closed form.
Optimistic Distributionally Robust Optimization for Nonparametric Likelihood Approximation
Oct 23, 2019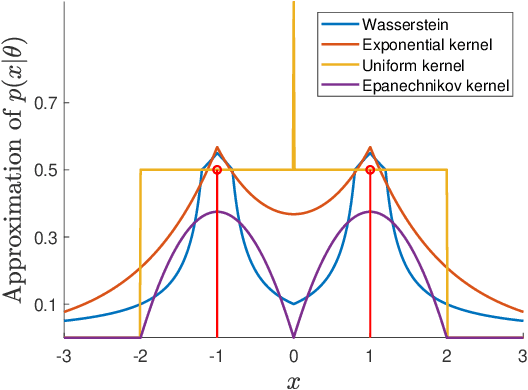
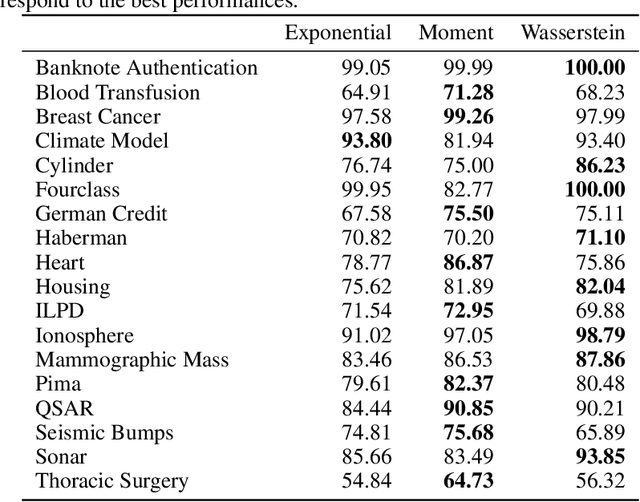
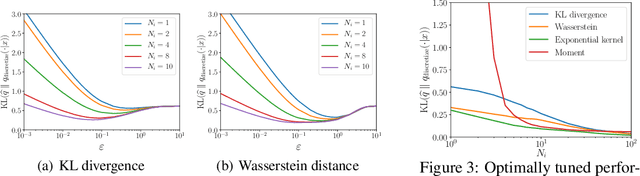
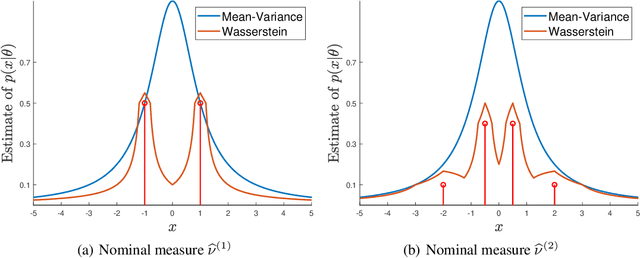
The likelihood function is a fundamental component in Bayesian statistics. However, evaluating the likelihood of an observation is computationally intractable in many applications. In this paper, we propose a non-parametric approximation of the likelihood that identifies a probability measure which lies in the neighborhood of the nominal measure and that maximizes the probability of observing the given sample point. We show that when the neighborhood is constructed by the Kullback-Leibler divergence, by moment conditions or by the Wasserstein distance, then our \textit{optimistic likelihood} can be determined through the solution of a convex optimization problem, and it admits an analytical expression in particular cases. We also show that the posterior inference problem with our optimistic likelihood approximation enjoys strong theoretical performance guarantees, and it performs competitively in a probabilistic classification task.
Calculating Optimistic Likelihoods Using (Geodesically) Convex Optimization
Oct 17, 2019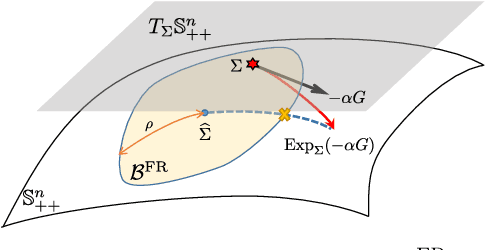
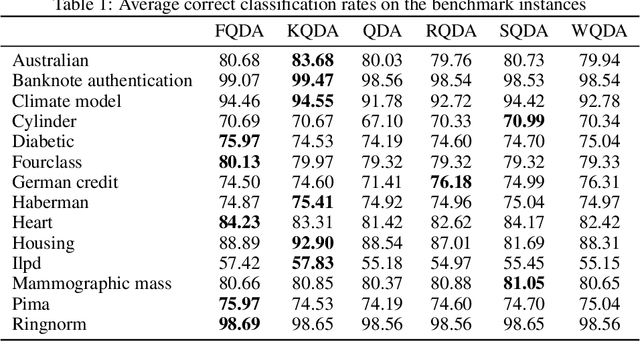
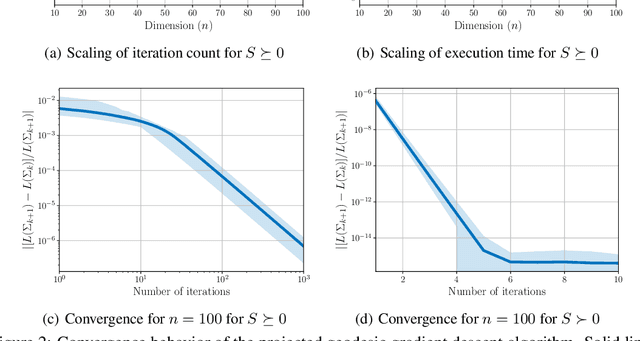
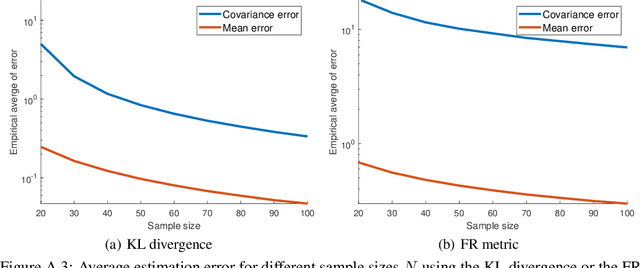
A fundamental problem arising in many areas of machine learning is the evaluation of the likelihood of a given observation under different nominal distributions. Frequently, these nominal distributions are themselves estimated from data, which makes them susceptible to estimation errors. We thus propose to replace each nominal distribution with an ambiguity set containing all distributions in its vicinity and to evaluate an \emph{optimistic likelihood}, that is, the maximum of the likelihood over all distributions in the ambiguity set. When the proximity of distributions is quantified by the Fisher-Rao distance or the Kullback-Leibler divergence, the emerging optimistic likelihoods can be computed efficiently using either geodesic or standard convex optimization techniques. We showcase the advantages of working with optimistic likelihoods on a classification problem using synthetic as well as empirical data.
Wasserstein Distributionally Robust Optimization: Theory and Applications in Machine Learning
Aug 23, 2019



Many decision problems in science, engineering and economics are affected by uncertain parameters whose distribution is only indirectly observable through samples. The goal of data-driven decision-making is to learn a decision from finitely many training samples that will perform well on unseen test samples. This learning task is difficult even if all training and test samples are drawn from the same distribution---especially if the dimension of the uncertainty is large relative to the training sample size. Wasserstein distributionally robust optimization seeks data-driven decisions that perform well under the most adverse distribution within a certain Wasserstein distance from a nominal distribution constructed from the training samples. In this tutorial we will argue that this approach has many conceptual and computational benefits. Most prominently, the optimal decisions can often be computed by solving tractable convex optimization problems, and they enjoy rigorous out-of-sample and asymptotic consistency guarantees. We will also show that Wasserstein distributionally robust optimization has interesting ramifications for statistical learning and motivates new approaches for fundamental learning tasks such as classification, regression, maximum likelihood estimation or minimum mean square error estimation, among others.
Wasserstein Distributionally Robust Kalman Filtering
Oct 01, 2018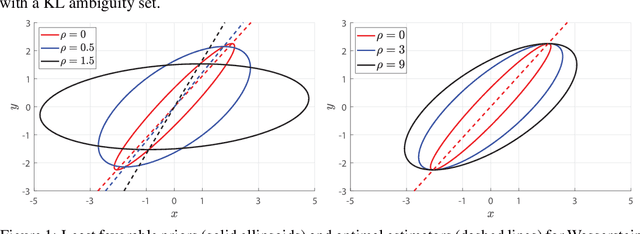
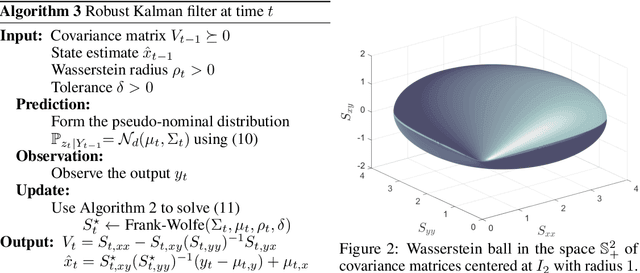
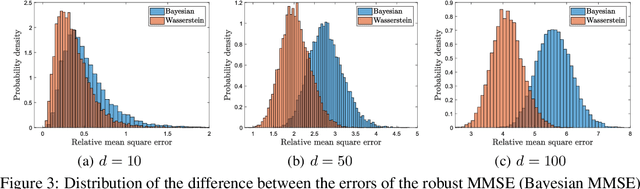
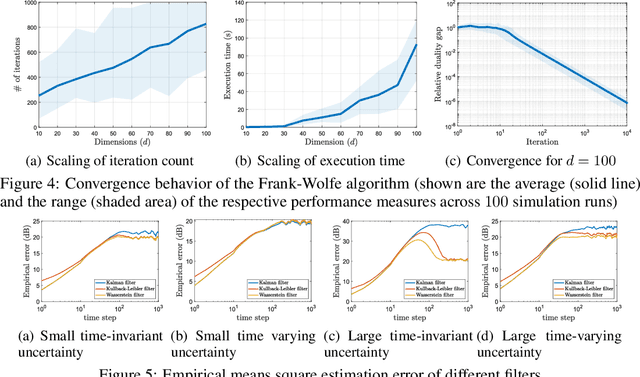
We study a distributionally robust mean square error estimation problem over a nonconvex Wasserstein ambiguity set containing only normal distributions. We show that the optimal estimator and the least favorable distribution form a Nash equilibrium. Despite the non-convex nature of the ambiguity set, we prove that the estimation problem is equivalent to a tractable convex program. We further devise a Frank-Wolfe algorithm for this convex program whose direction-searching subproblem can be solved in a quasi-closed form. Using these ingredients, we introduce a distributionally robust Kalman filter that hedges against model risk.