 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass2Simi: A New Perspective on Learning with Label Noise
Jun 14, 2020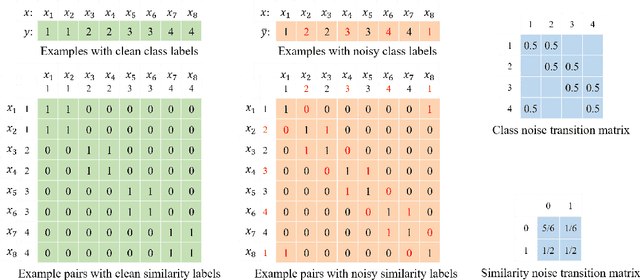


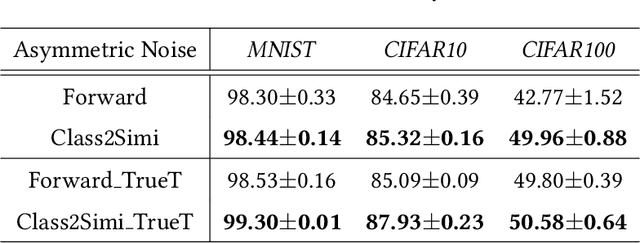
Label noise is ubiquitous in the era of big data. Deep learning algorithms can easily fit the noise and thus cannot generalize well without properly modeling the noise. In this paper, we propose a new perspective on dealing with label noise called Class2Simi. Specifically, we transform the training examples with noisy class labels into pairs of examples with noisy similarity labels and propose a deep learning framework to learn robust classifiers directly with the noisy similarity labels. Note that a class label shows the class that an instance belongs to; while a similarity label indicates whether or not two instances belong to the same class. It is worthwhile to perform the transformation: We prove that the noise rate for the noisy similarity labels is lower than that of the noisy class labels, because similarity labels themselves are robust to noise. For example, given two instances, even if both of their class labels are incorrect, their similarity label could be correct. Due to the lower noise rate, Class2Simi achieves remarkably better classification accuracy than its baselines that directly deals with the noisy class labels.
Multi-Class Classification from Noisy-Similarity-Labeled Data
Feb 16, 2020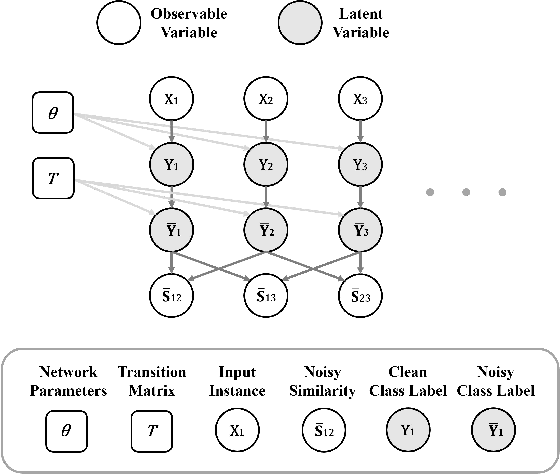
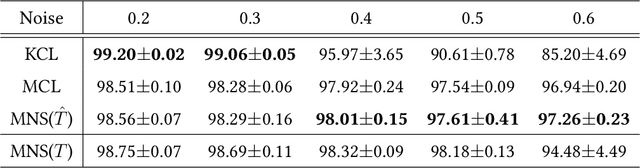

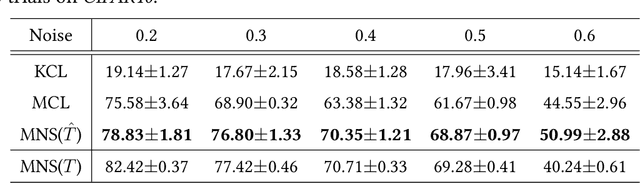
A similarity label indicates whether two instances belong to the same class while a class label shows the class of the instance. Without class labels, a multi-class classifier could be learned from similarity-labeled pairwise data by meta classification learning. However, since the similarity label is less informative than the class label, it is more likely to be noisy. Deep neural networks can easily remember noisy data, leading to overfitting in classification. In this paper, we propose a method for learning from only noisy-similarity-labeled data. Specifically, to model the noise, we employ a noise transition matrix to bridge the class-posterior probability between clean and noisy data. We further estimate the transition matrix from only noisy data and build a novel learning system to learn a classifier which can assign noise-free class labels for instances. Moreover, we theoretically justify how our proposed method generalizes for learning classifiers. Experimental results demonstrate the superiority of the proposed method over the state-of-the-art method on benchmark-simulated and real-world noisy-label datasets.