 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentrum: Model-based Database Auto-tuning with Minimal Distributional Assumptions
Oct 26, 2025Gaussian-Process-based Bayesian optimization (GP-BO), is a prevailing model-based framework for DBMS auto-tuning. However, recent work shows GP-BO-based DBMS auto-tuners significantly outperformed auto-tuners based on SMAC, which features random forest surrogate models; such results motivate us to rethink and investigate the limitations of GP-BO in auto-tuner design. We find the fundamental assumptions of GP-BO are widely violated when modeling and optimizing DBMS performance, while tree-ensemble-BOs (e.g., SMAC) can avoid the assumption pitfalls and deliver improved tuning efficiency and effectiveness. Moreover, we argue that existing tree-ensemble-BOs restrict further advancement in DBMS auto-tuning. First, existing tree-ensemble-BOs can only achieve distribution-free point estimates, but still impose unrealistic distributional assumptions on uncertainty estimates, compromising surrogate modeling and distort the acquisition function. Second, recent advances in gradient boosting, which can further enhance surrogate modeling against vanilla GP and random forest counterparts, have rarely been applied in optimizing DBMS auto-tuners. To address these issues, we propose a novel model-based DBMS auto-tuner, Centrum. Centrum improves distribution-free point and interval estimation in surrogate modeling with a two-phase learning procedure of stochastic gradient boosting ensembles. Moreover, Centrum adopts a generalized SGBE-estimated locally-adaptive conformal prediction to facilitate a distribution-free uncertainty estimation and acquisition function. To our knowledge, Centrum is the first auto-tuner to realize distribution-freeness, enhancing BO's practicality in DBMS auto-tuning, and the first to seamlessly fuse gradient boosting ensembles and conformal inference in BO. Extensive physical and simulation experiments on two DBMSs and three workloads show Centrum outperforms 21 SOTA methods.
CLEANet: Robust and Efficient Anomaly Detection in Contaminated Multivariate Time Series
Oct 26, 2025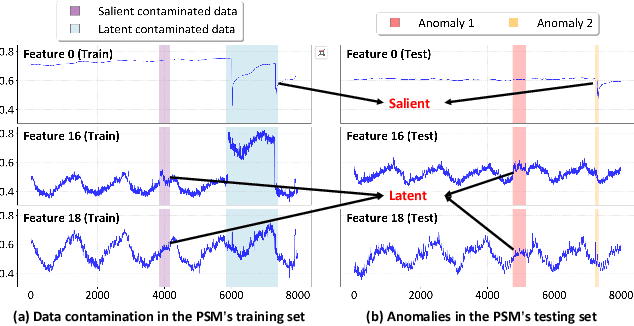
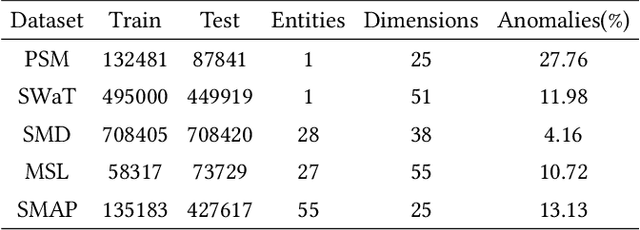
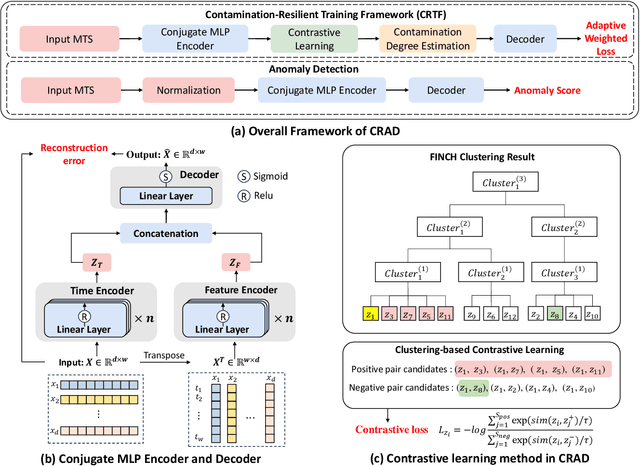
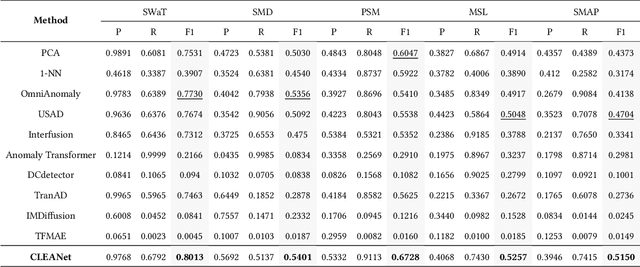
Multivariate time series (MTS) anomaly detection is essential for maintaining the reliability of industrial systems, yet real-world deployment is hindered by two critical challenges: training data contamination (noises and hidden anomalies) and inefficient model inference. Existing unsupervised methods assume clean training data, but contamination distorts learned patterns and degrades detection accuracy. Meanwhile, complex deep models often overfit to contamination and suffer from high latency, limiting practical use. To address these challenges, we propose CLEANet, a robust and efficient anomaly detection framework in contaminated multivariate time series. CLEANet introduces a Contamination-Resilient Training Framework (CRTF) that mitigates the impact of corrupted samples through an adaptive reconstruction weighting strategy combined with clustering-guided contrastive learning, thereby enhancing robustness. To further avoid overfitting on contaminated data and improve computational efficiency, we design a lightweight conjugate MLP that disentangles temporal and cross-feature dependencies. Across five public datasets, CLEANet achieves up to 73.04% higher F1 and 81.28% lower runtime compared with ten state-of-the-art baselines. Furthermore, integrating CRTF into three advanced models yields an average 5.35% F1 gain, confirming its strong generalizability.