 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of LLMs Against Prompt Injection and Jailbreak Attacks
Feb 24, 2026Large Language Models (LLMs) are widely deployed in real-world systems. Given their broader applicability, prompt engineering has become an efficient tool for resource-scarce organizations to adopt LLMs for their own purposes. At the same time, LLMs are vulnerable to prompt-based attacks. Thus, analyzing this risk has become a critical security requirement. This work evaluates prompt-injection and jailbreak vulnerability using a large, manually curated dataset across multiple open-source LLMs, including Phi, Mistral, DeepSeek-R1, Llama 3.2, Qwen, and Gemma variants. We observe significant behavioural variation across models, including refusal responses and complete silent non-responsiveness triggered by internal safety mechanisms. Furthermore, we evaluated several lightweight, inference-time defence mechanisms that operate as filters without any retraining or GPU-intensive fine-tuning. Although these defences mitigate straightforward attacks, they are consistently bypassed by long, reasoning-heavy prompts.
Building an Effective Intrusion Detection System using Unsupervised Feature Selection in Multi-objective Optimization Framework
May 16, 2019
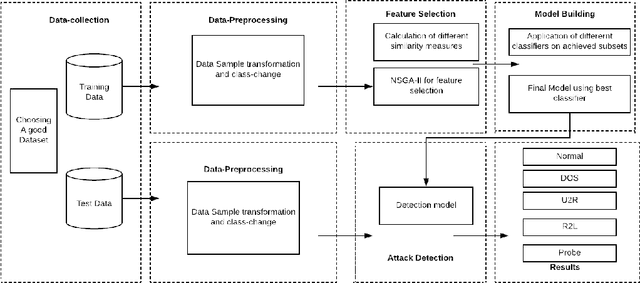
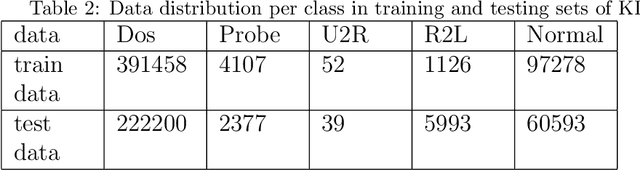
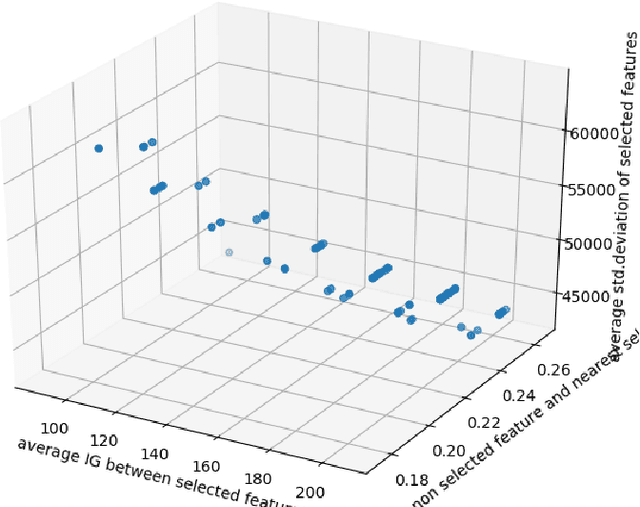
Intrusion Detection Systems (IDS) are developed to protect the network by detecting the attack. The current paper proposes an unsupervised feature selection technique for analyzing the network data. The search capability of the non-dominated sorting genetic algorithm (NSGA-II) has been employed for optimizing three different objective functions utilizing different information theoretic measures including mutual information, standard deviation, and information gain to identify mutually exclusive and a high variant subset of features. Finally, the Pareto optimal front of the different optimal feature subsets are obtained and these feature subsets are utilized for developing classification systems using different popular machine learning models like support vector machines, decision trees and k-nearest neighbour (k=5) classifier etc. We have evaluated the results of the algorithm on KDD-99, NSL-KDD and Kyoto 2006+ datasets. The experimental results on KDD-99 dataset show that decision tree provides better results than other available classifiers. The proposed system obtains the best results of 99.78% accuracy, 99.27% detection rate and false alarm rate of 0.2%, which are better than all the previous results for KDD dataset. We achieved an accuracy of 99.83% for 20% testing data of NSL-KDD dataset and 99.65% accuracy for 10-fold cross-validation on Kyoto dataset. The most attractive characteristic of the proposed scheme is that during the selection of appropriate feature subset, no labeled information is utilized and different feature quality measures are optimized simultaneously using the multi-objective optimization framework.