 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple and Effective Curriculum Pointer-Generator Networks for Reading Comprehension over Long Narratives
May 26, 2019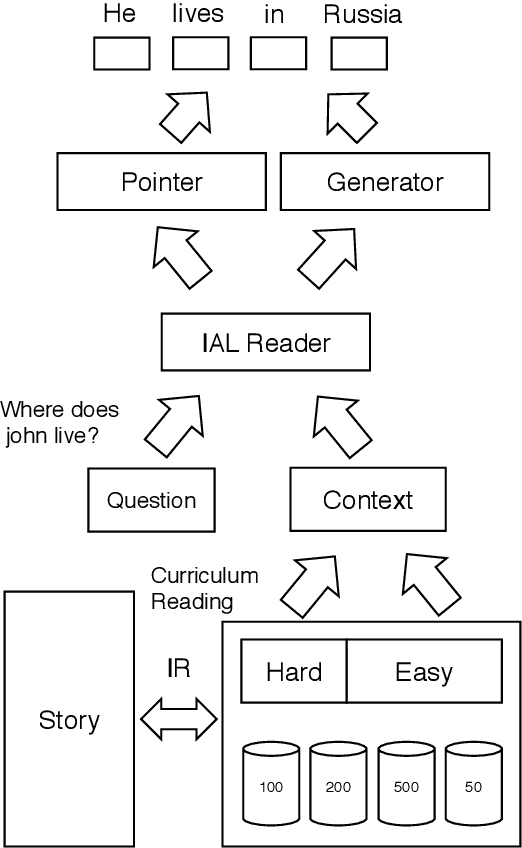
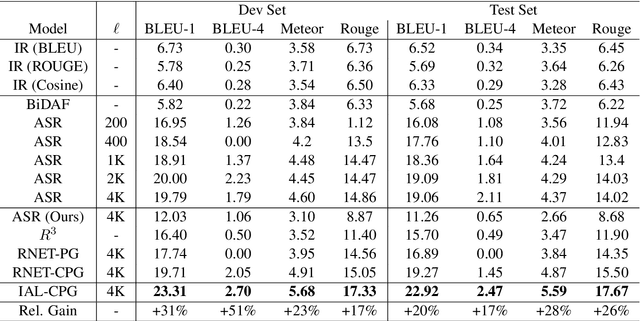
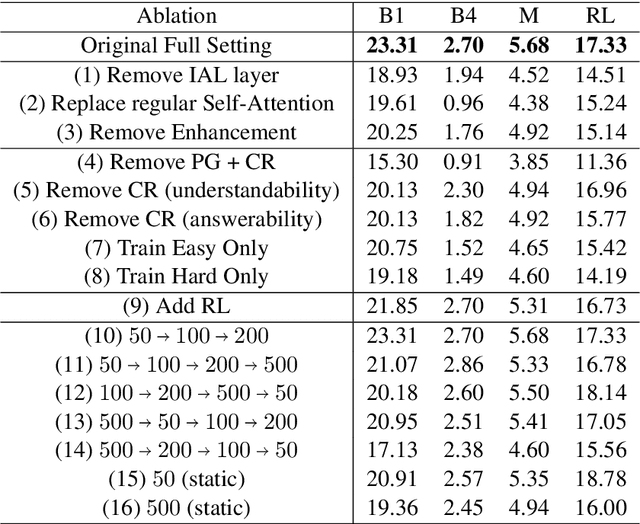

This paper tackles the problem of reading comprehension over long narratives where documents easily span over thousands of tokens. We propose a curriculum learning (CL) based Pointer-Generator framework for reading/sampling over large documents, enabling diverse training of the neural model based on the notion of alternating contextual difficulty. This can be interpreted as a form of domain randomization and/or generative pretraining during training. To this end, the usage of the Pointer-Generator softens the requirement of having the answer within the context, enabling us to construct diverse training samples for learning. Additionally, we propose a new Introspective Alignment Layer (IAL), which reasons over decomposed alignments using block-based self-attention. We evaluate our proposed method on the NarrativeQA reading comprehension benchmark, achieving state-of-the-art performance, improving existing baselines by $51\%$ relative improvement on BLEU-4 and $17\%$ relative improvement on Rouge-L. Extensive ablations confirm the effectiveness of our proposed IAL and CL components.
Recurrently Controlled Recurrent Networks
Nov 24, 2018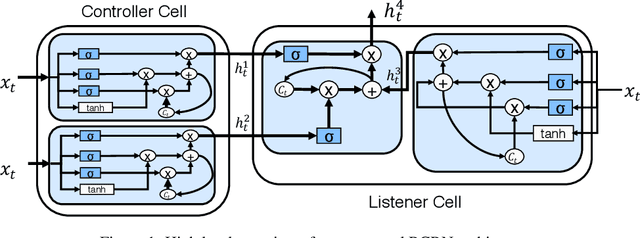
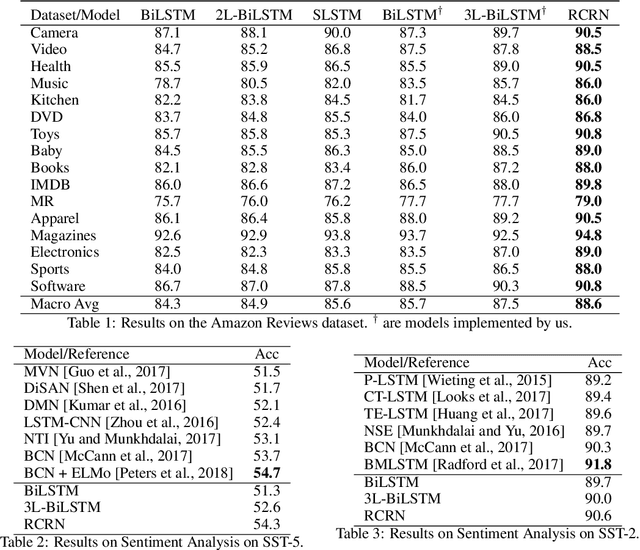
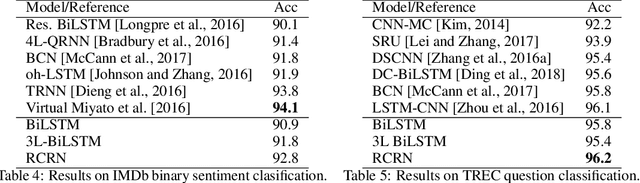
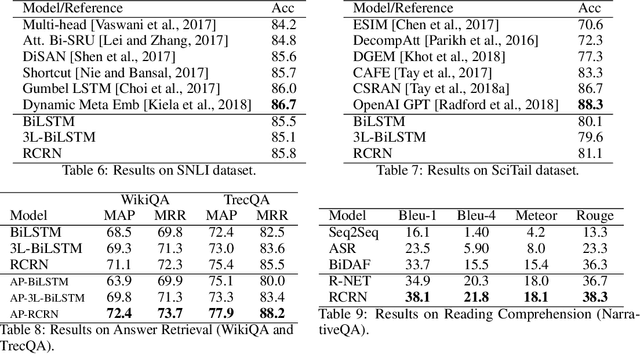
Recurrent neural networks (RNNs) such as long short-term memory and gated recurrent units are pivotal building blocks across a broad spectrum of sequence modeling problems. This paper proposes a recurrently controlled recurrent network (RCRN) for expressive and powerful sequence encoding. More concretely, the key idea behind our approach is to learn the recurrent gating functions using recurrent networks. Our architecture is split into two components - a controller cell and a listener cell whereby the recurrent controller actively influences the compositionality of the listener cell. We conduct extensive experiments on a myriad of tasks in the NLP domain such as sentiment analysis (SST, IMDb, Amazon reviews, etc.), question classification (TREC), entailment classification (SNLI, SciTail), answer selection (WikiQA, TrecQA) and reading comprehension (NarrativeQA). Across all 26 datasets, our results demonstrate that RCRN not only consistently outperforms BiLSTMs but also stacked BiLSTMs, suggesting that our controller architecture might be a suitable replacement for the widely adopted stacked architecture.
Densely Connected Attention Propagation for Reading Comprehension
Nov 10, 2018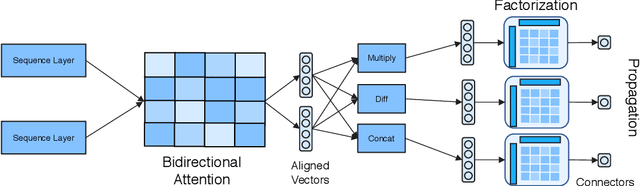
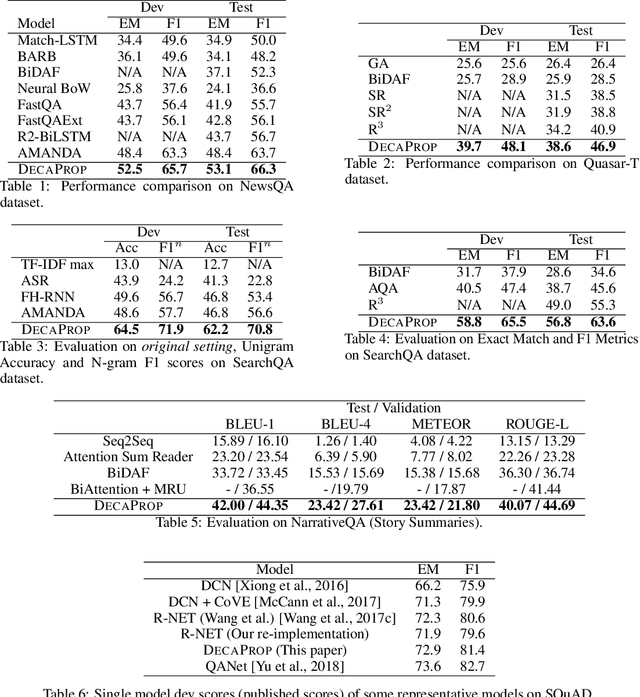
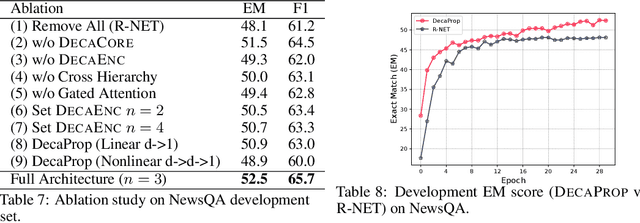
We propose DecaProp (Densely Connected Attention Propagation), a new densely connected neural architecture for reading comprehension (RC). There are two distinct characteristics of our model. Firstly, our model densely connects all pairwise layers of the network, modeling relationships between passage and query across all hierarchical levels. Secondly, the dense connectors in our network are learned via attention instead of standard residual skip-connectors. To this end, we propose novel Bidirectional Attention Connectors (BAC) for efficiently forging connections throughout the network. We conduct extensive experiments on four challenging RC benchmarks. Our proposed approach achieves state-of-the-art results on all four, outperforming existing baselines by up to $2.6\%-14.2\%$ in absolute F1 score.
Compare, Compress and Propagate: Enhancing Neural Architectures with Alignment Factorization for Natural Language Inference
Sep 10, 2018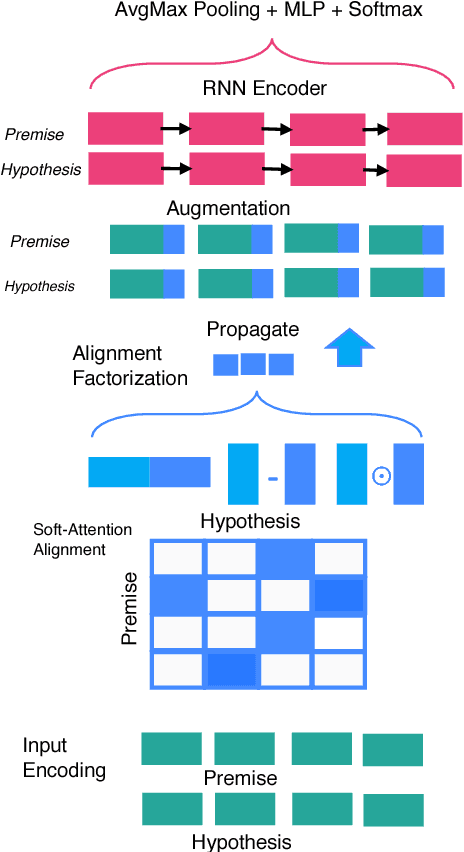
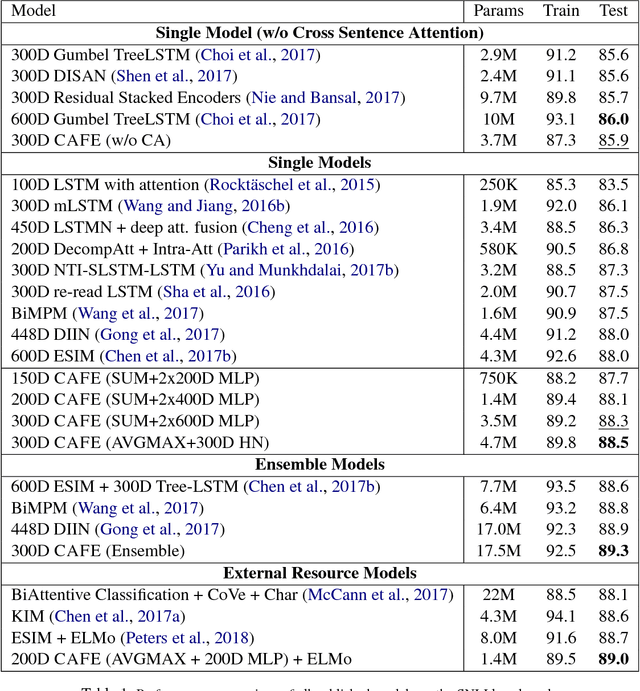
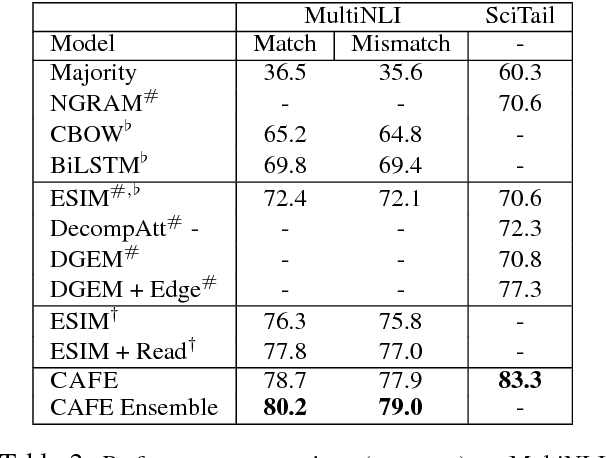
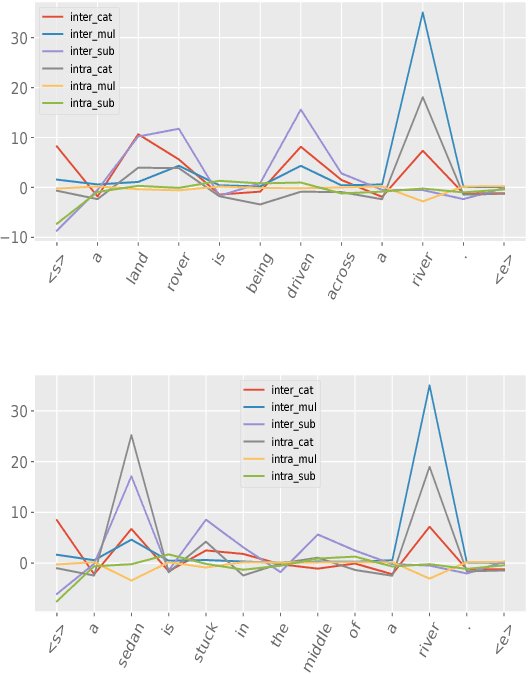
This paper presents a new deep learning architecture for Natural Language Inference (NLI). Firstly, we introduce a new architecture where alignment pairs are compared, compressed and then propagated to upper layers for enhanced representation learning. Secondly, we adopt factorization layers for efficient and expressive compression of alignment vectors into scalar features, which are then used to augment the base word representations. The design of our approach is aimed to be conceptually simple, compact and yet powerful. We conduct experiments on three popular benchmarks, SNLI, MultiNLI and SciTail, achieving competitive performance on all. A lightweight parameterization of our model also enjoys a $\approx 3$ times reduction in parameter size compared to the existing state-of-the-art models, e.g., ESIM and DIIN, while maintaining competitive performance. Additionally, visual analysis shows that our propagated features are highly interpretable.
Self-Attentive Neural Collaborative Filtering
Jul 19, 2018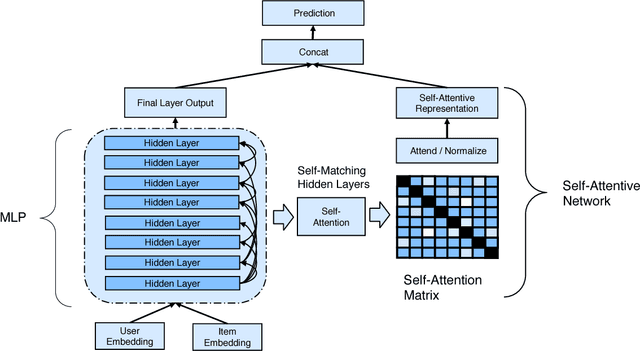
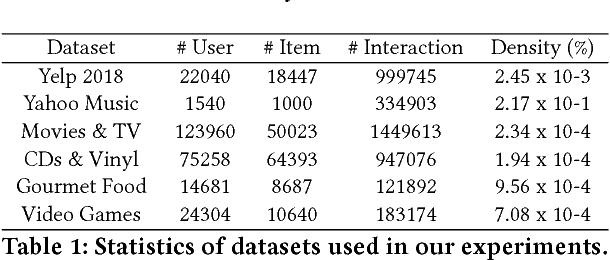
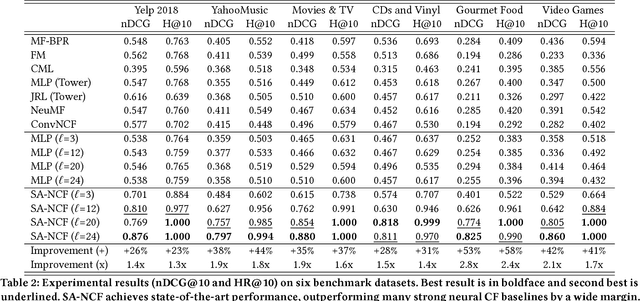
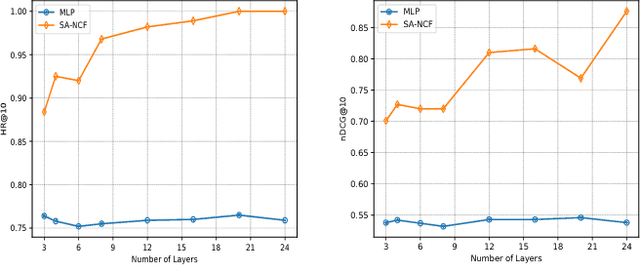
This paper has been withdrawn as we discovered a bug in our tensorflow implementation that involved accidental mixing of vectors across batches. This lead to different inference results given different batch sizes which is completely strange. The performance scores still remain the same but we concluded that it was not the self-attention that contributed to the performance. We are withdrawing the paper because this renders the main claim of the paper false. Thanks to Guan Xinyu from NUS for discovering this issue in our previously open source code.
Multi-Pointer Co-Attention Networks for Recommendation
Jun 21, 2018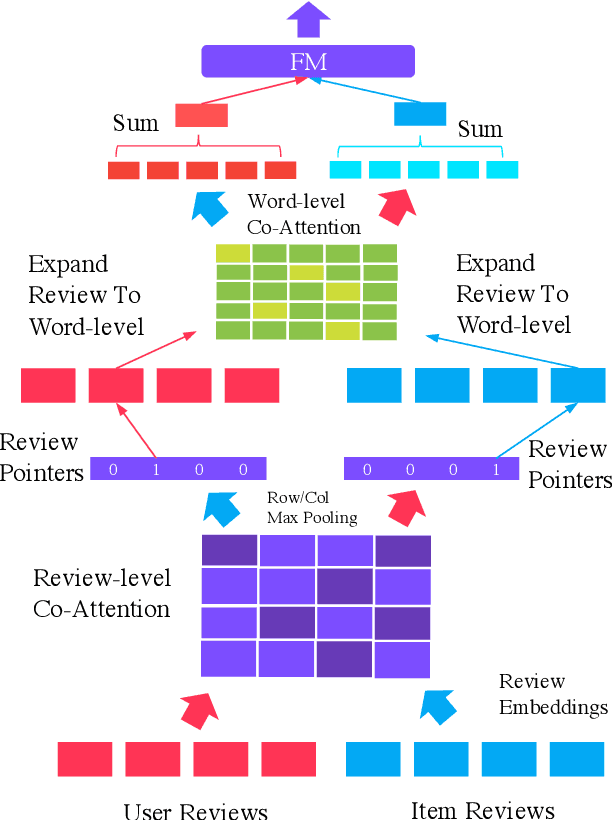
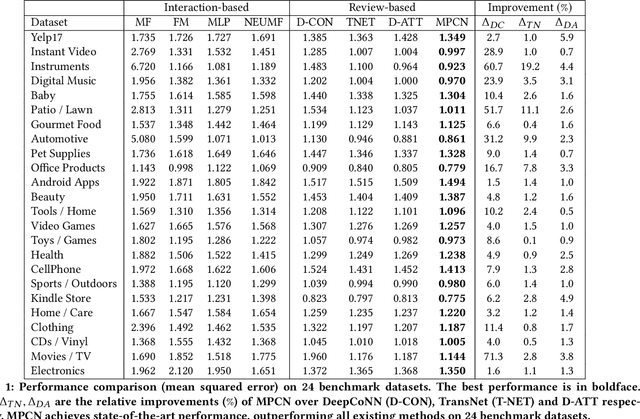
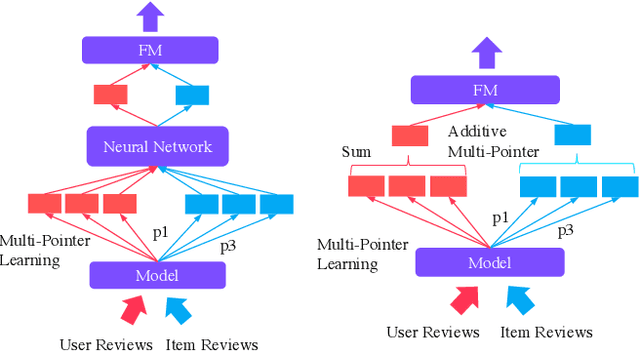
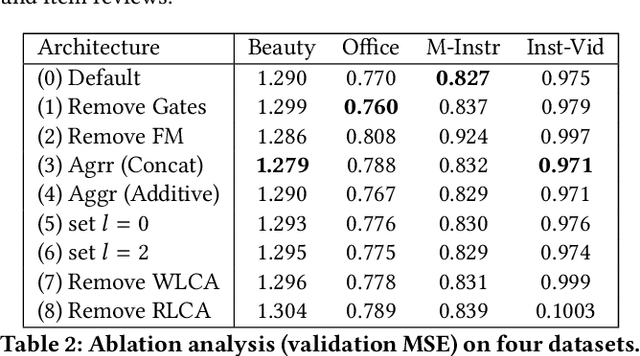
Many recent state-of-the-art recommender systems such as D-ATT, TransNet and DeepCoNN exploit reviews for representation learning. This paper proposes a new neural architecture for recommendation with reviews. Our model operates on a multi-hierarchical paradigm and is based on the intuition that not all reviews are created equal, i.e., only a select few are important. The importance, however, should be dynamically inferred depending on the current target. To this end, we propose a review-by-review pointer-based learning scheme that extracts important reviews, subsequently matching them in a word-by-word fashion. This enables not only the most informative reviews to be utilized for prediction but also a deeper word-level interaction. Our pointer-based method operates with a novel gumbel-softmax based pointer mechanism that enables the incorporation of discrete vectors within differentiable neural architectures. Our pointer mechanism is co-attentive in nature, learning pointers which are co-dependent on user-item relationships. Finally, we propose a multi-pointer learning scheme that learns to combine multiple views of interactions between user and item. Overall, we demonstrate the effectiveness of our proposed model via extensive experiments on \textbf{24} benchmark datasets from Amazon and Yelp. Empirical results show that our approach significantly outperforms existing state-of-the-art, with up to 19% and 71% relative improvement when compared to TransNet and DeepCoNN respectively. We study the behavior of our multi-pointer learning mechanism, shedding light on evidence aggregation patterns in review-based recommender systems.
Multi-Cast Attention Networks for Retrieval-based Question Answering and Response Prediction
Jun 03, 2018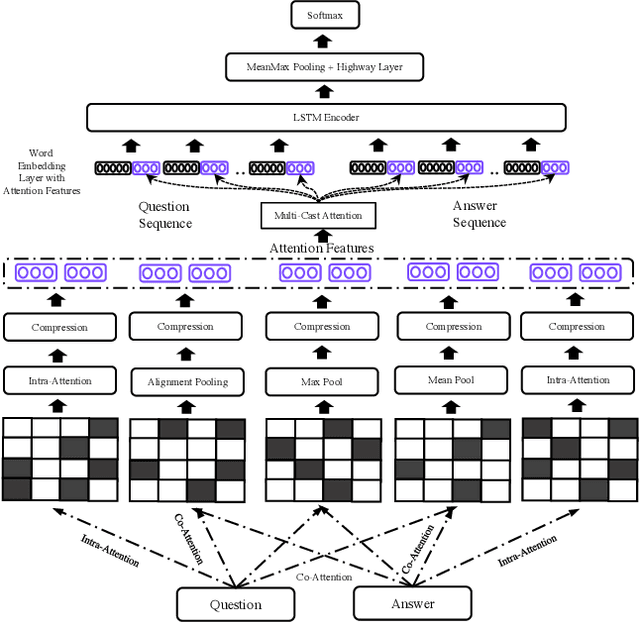
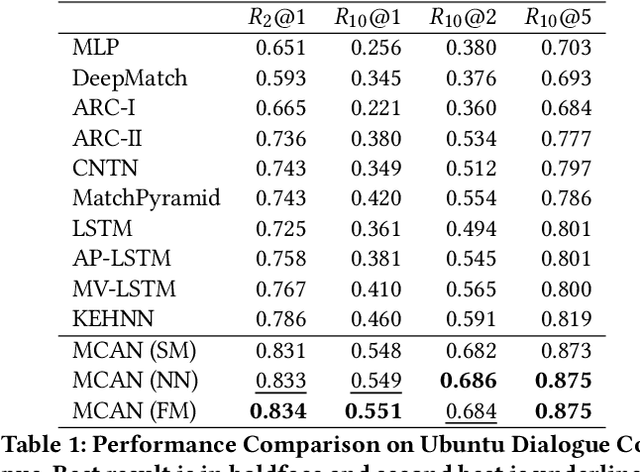
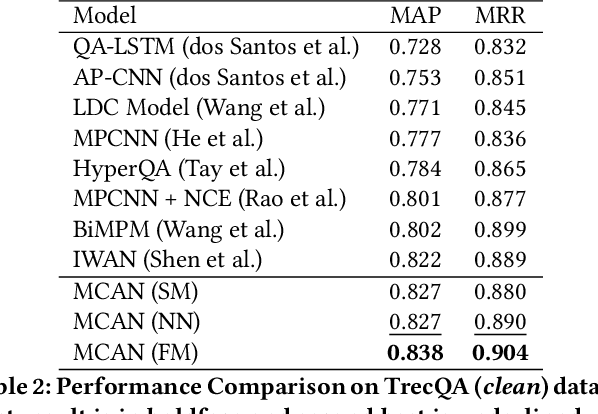
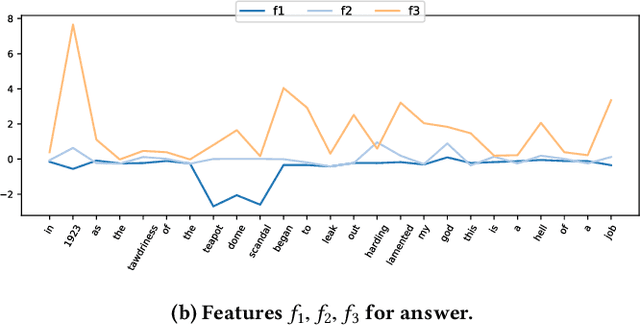
Attention is typically used to select informative sub-phrases that are used for prediction. This paper investigates the novel use of attention as a form of feature augmentation, i.e, casted attention. We propose Multi-Cast Attention Networks (MCAN), a new attention mechanism and general model architecture for a potpourri of ranking tasks in the conversational modeling and question answering domains. Our approach performs a series of soft attention operations, each time casting a scalar feature upon the inner word embeddings. The key idea is to provide a real-valued hint (feature) to a subsequent encoder layer and is targeted at improving the representation learning process. There are several advantages to this design, e.g., it allows an arbitrary number of attention mechanisms to be casted, allowing for multiple attention types (e.g., co-attention, intra-attention) and attention variants (e.g., alignment-pooling, max-pooling, mean-pooling) to be executed simultaneously. This not only eliminates the costly need to tune the nature of the co-attention layer, but also provides greater extents of explainability to practitioners. Via extensive experiments on four well-known benchmark datasets, we show that MCAN achieves state-of-the-art performance. On the Ubuntu Dialogue Corpus, MCAN outperforms existing state-of-the-art models by $9\%$. MCAN also achieves the best performing score to date on the well-studied TrecQA dataset.
CoupleNet: Paying Attention to Couples with Coupled Attention for Relationship Recommendation
May 29, 2018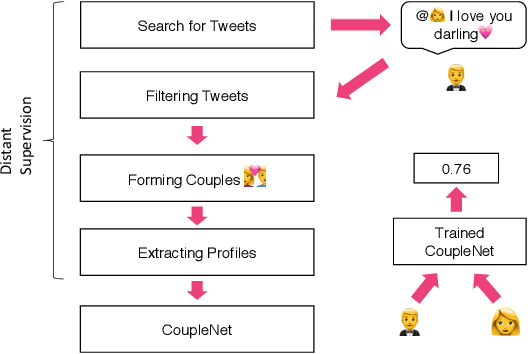
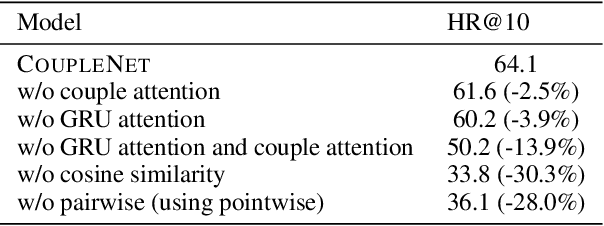
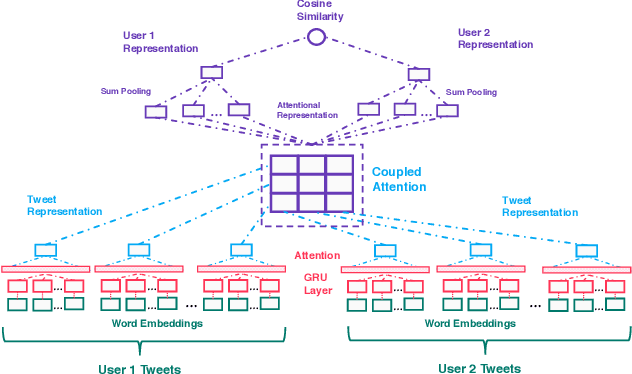

Dating and romantic relationships not only play a huge role in our personal lives but also collectively influence and shape society. Today, many romantic partnerships originate from the Internet, signifying the importance of technology and the web in modern dating. In this paper, we present a text-based computational approach for estimating the relationship compatibility of two users on social media. Unlike many previous works that propose reciprocal recommender systems for online dating websites, we devise a distant supervision heuristic to obtain real world couples from social platforms such as Twitter. Our approach, the CoupleNet is an end-to-end deep learning based estimator that analyzes the social profiles of two users and subsequently performs a similarity match between the users. Intuitively, our approach performs both user profiling and match-making within a unified end-to-end framework. CoupleNet utilizes hierarchical recurrent neural models for learning representations of user profiles and subsequently coupled attention mechanisms to fuse information aggregated from two users. To the best of our knowledge, our approach is the first data-driven deep learning approach for our novel relationship recommendation problem. We benchmark our CoupleNet against several machine learning and deep learning baselines. Experimental results show that our approach outperforms all approaches significantly in terms of precision. Qualitative analysis shows that our model is capable of also producing explainable results to users.
Reasoning with Sarcasm by Reading In-between
May 08, 2018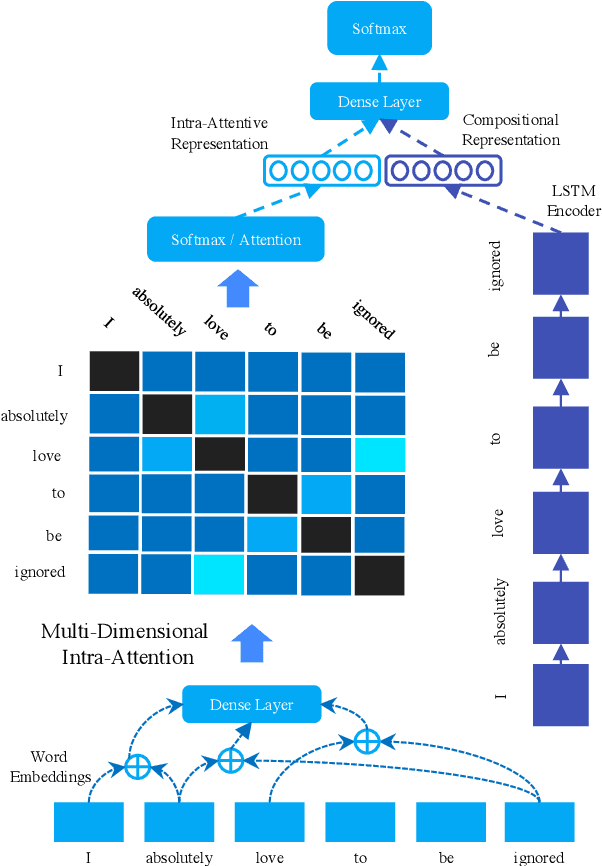
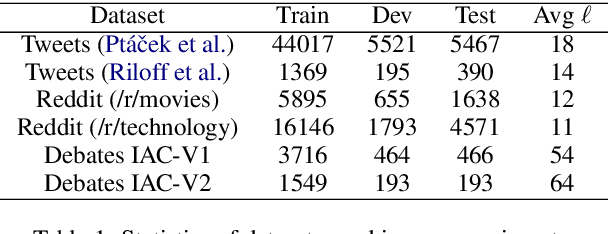
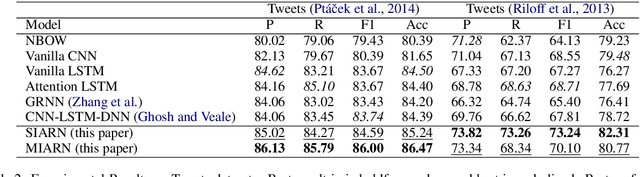
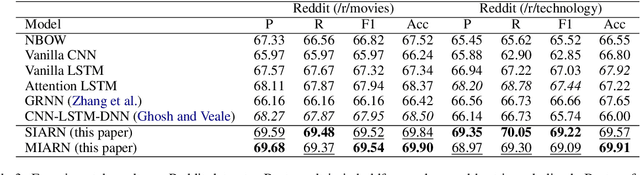
Sarcasm is a sophisticated speech act which commonly manifests on social communities such as Twitter and Reddit. The prevalence of sarcasm on the social web is highly disruptive to opinion mining systems due to not only its tendency of polarity flipping but also usage of figurative language. Sarcasm commonly manifests with a contrastive theme either between positive-negative sentiments or between literal-figurative scenarios. In this paper, we revisit the notion of modeling contrast in order to reason with sarcasm. More specifically, we propose an attention-based neural model that looks in-between instead of across, enabling it to explicitly model contrast and incongruity. We conduct extensive experiments on six benchmark datasets from Twitter, Reddit and the Internet Argument Corpus. Our proposed model not only achieves state-of-the-art performance on all datasets but also enjoys improved interpretability.
Multi-range Reasoning for Machine Comprehension
Mar 24, 2018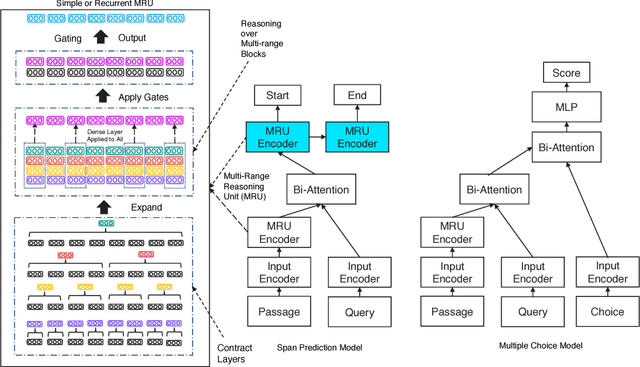
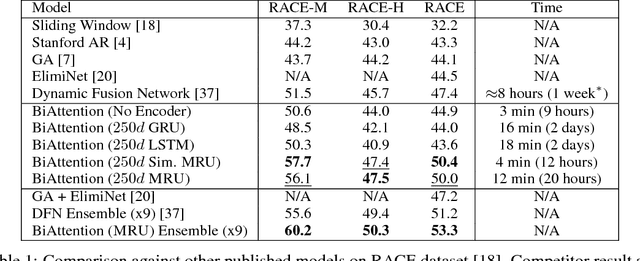
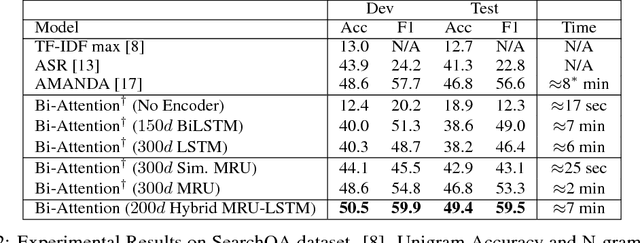
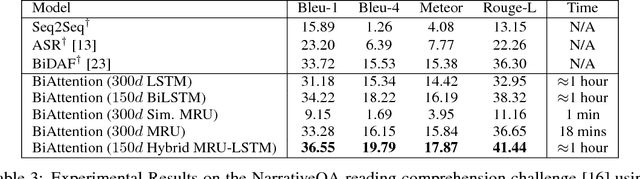
We propose MRU (Multi-Range Reasoning Units), a new fast compositional encoder for machine comprehension (MC). Our proposed MRU encoders are characterized by multi-ranged gating, executing a series of parameterized contract-and-expand layers for learning gating vectors that benefit from long and short-term dependencies. The aims of our approach are as follows: (1) learning representations that are concurrently aware of long and short-term context, (2) modeling relationships between intra-document blocks and (3) fast and efficient sequence encoding. We show that our proposed encoder demonstrates promising results both as a standalone encoder and as well as a complementary building block. We conduct extensive experiments on three challenging MC datasets, namely RACE, SearchQA and NarrativeQA, achieving highly competitive performance on all. On the RACE benchmark, our model outperforms DFN (Dynamic Fusion Networks) by 1.5%-6% without using any recurrent or convolution layers. Similarly, we achieve competitive performance relative to AMANDA on the SearchQA benchmark and BiDAF on the NarrativeQA benchmark without using any LSTM/GRU layers. Finally, incorporating MRU encoders with standard BiLSTM architectures further improves performance, achieving state-of-the-art results.