 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadTimeline: Timeline Summarization for Longitudinal Radiological Lung Findings
Mar 24, 2026Tracking findings in longitudinal radiology reports is crucial for accurately identifying disease progression, and the time-consuming process would benefit from automatic summarization. This work introduces a structured summarization task, where we frame longitudinal report summarization as a timeline generation task, with dated findings organized in columns and temporally related findings grouped in rows. This structured summarization format enables straightforward comparison of findings across time and facilitates fact-checking against the associated reports. The timeline is generated using a 3-step LLM process of extracting findings, generating group names, and using the names to group the findings. To evaluate such systems, we create RadTimeline, a timeline dataset focused on tracking lung-related radiologic findings in chest-related imaging reports. Experiments on RadTimeline show tradeoffs of different-sized LLMs and prompting strategies. Our results highlight that group name generation as an intermediate step is critical for effective finding grouping. The best configuration has some irrelevant findings but very good recall, and grouping performance is comparable to human annotators.
We-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning
Aug 14, 2025Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various tasks, but still struggle with complex mathematical reasoning. Existing research primarily focuses on dataset construction and method optimization, often overlooking two critical aspects: comprehensive knowledge-driven design and model-centric data space modeling. In this paper, we introduce We-Math 2.0, a unified system that integrates a structured mathematical knowledge system, model-centric data space modeling, and a reinforcement learning (RL)-based training paradigm to comprehensively enhance the mathematical reasoning abilities of MLLMs. The key contributions of We-Math 2.0 are fourfold: (1) MathBook Knowledge System: We construct a five-level hierarchical system encompassing 491 knowledge points and 1,819 fundamental principles. (2) MathBook-Standard & Pro: We develop MathBook-Standard, a dataset that ensures broad conceptual coverage and flexibility through dual expansion. Additionally, we define a three-dimensional difficulty space and generate 7 progressive variants per problem to build MathBook-Pro, a challenging dataset for robust training. (3) MathBook-RL: We propose a two-stage RL framework comprising: (i) Cold-Start Fine-tuning, which aligns the model with knowledge-oriented chain-of-thought reasoning; and (ii) Progressive Alignment RL, leveraging average-reward learning and dynamic data scheduling to achieve progressive alignment across difficulty levels. (4) MathBookEval: We introduce a comprehensive benchmark covering all 491 knowledge points with diverse reasoning step distributions. Experimental results show that MathBook-RL performs competitively with existing baselines on four widely-used benchmarks and achieves strong results on MathBookEval, suggesting promising generalization in mathematical reasoning.
Building blocks for complex tasks: Robust generative event extraction for radiology reports under domain shifts
Jun 15, 2023This paper explores methods for extracting information from radiology reports that generalize across exam modalities to reduce requirements for annotated data. We demonstrate that multi-pass T5-based text-to-text generative models exhibit better generalization across exam modalities compared to approaches that employ BERT-based task-specific classification layers. We then develop methods that reduce the inference cost of the model, making large-scale corpus processing more feasible for clinical applications. Specifically, we introduce a generative technique that decomposes complex tasks into smaller subtask blocks, which improves a single-pass model when combined with multitask training. In addition, we leverage target-domain contexts during inference to enhance domain adaptation, enabling use of smaller models. Analyses offer insights into the benefits of different cost reduction strategies.
Generalizing through Forgetting -- Domain Generalization for Symptom Event Extraction in Clinical Notes
Sep 20, 2022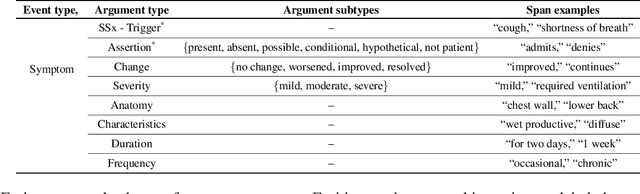
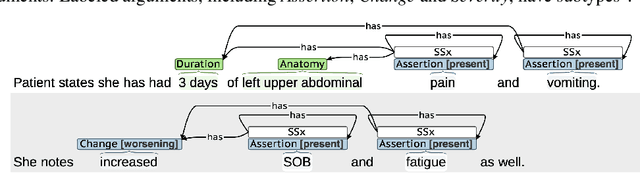

Symptom information is primarily documented in free-text clinical notes and is not directly accessible for downstream applications. To address this challenge, information extraction approaches that can handle clinical language variation across different institutions and specialties are needed. In this paper, we present domain generalization for symptom extraction using pretraining and fine-tuning data that differs from the target domain in terms of institution and/or specialty and patient population. We extract symptom events using a transformer-based joint entity and relation extraction method. To reduce reliance on domain-specific features, we propose a domain generalization method that dynamically masks frequent symptoms words in the source domain. Additionally, we pretrain the transformer language model (LM) on task-related unlabeled texts for better representation. Our experiments indicate that masking and adaptive pretraining methods can significantly improve performance when the source domain is more distant from the target domain.
A Transfer Learning Method for Speech Emotion Recognition from Automatic Speech Recognition
Aug 15, 2020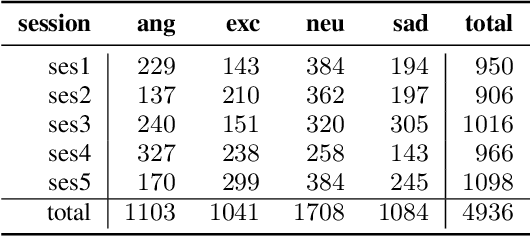
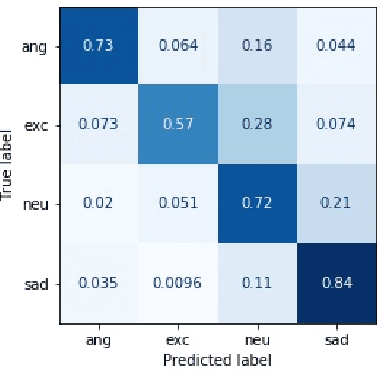

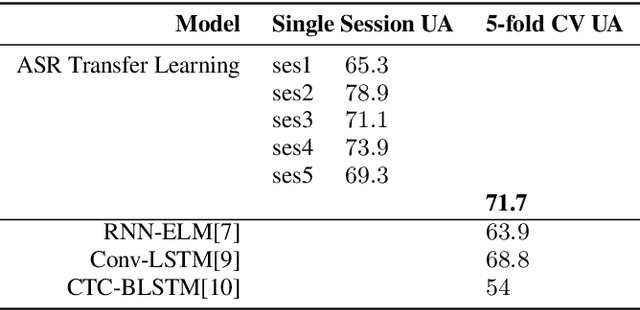
This paper presents a transfer learning method in speech emotion recognition based on a Time-Delay Neural Network (TDNN) architecture. A major challenge in the current speech-based emotion detection research is data scarcity. The proposed method resolves this problem by applying transfer learning techniques in order to leverage data from the automatic speech recognition (ASR) task for which ample data is available. Our experiments also show the advantage of speaker-class adaptation modeling techniques by adopting identity-vector (i-vector) based features in addition to standard Mel-Frequency Cepstral Coefficient (MFCC) features.[1] We show the transfer learning models significantly outperform the other methods without pretraining on ASR. The experiments performed on the publicly available IEMOCAP dataset which provides 12 hours of motional speech data. The transfer learning was initialized by using the Ted-Lium v.2 speech dataset providing 207 hours of audio with the corresponding transcripts. We achieve the highest significantly higher accuracy when compared to state-of-the-art, using five-fold cross validation. Using only speech, we obtain an accuracy 71.7% for anger, excitement, sadness, and neutrality emotion content.