 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-based Reconstruction with Learning: From Unsupervised to Supervised and Beyond
Mar 26, 2021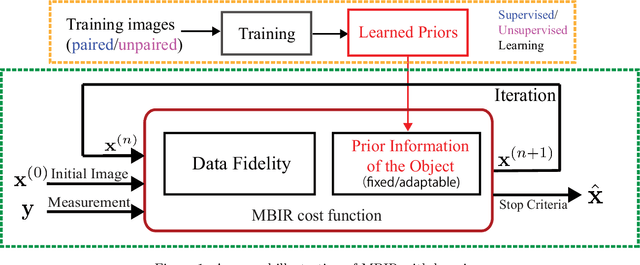
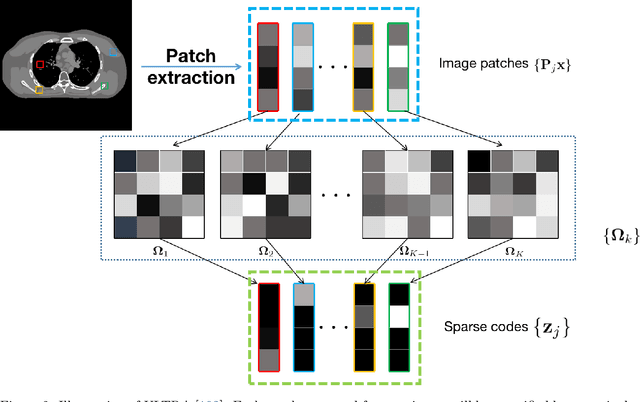
Many techniques have been proposed for image reconstruction in medical imaging that aim to recover high-quality images especially from limited or corrupted measurements. Model-based reconstruction methods have been particularly popular (e.g., in magnetic resonance imaging and tomographic modalities) and exploit models of the imaging system's physics together with statistical models of measurements, noise and often relatively simple object priors or regularizers. For example, sparsity or low-rankness based regularizers have been widely used for image reconstruction from limited data such as in compressed sensing. Learning-based approaches for image reconstruction have garnered much attention in recent years and have shown promise across biomedical imaging applications. These methods include synthesis dictionary learning, sparsifying transform learning, and different forms of deep learning involving complex neural networks. We briefly discuss classical model-based reconstruction methods and then review reconstruction methods at the intersection of model-based and learning-based paradigms in detail. This review includes many recent methods based on unsupervised learning, and supervised learning, as well as a framework to combine multiple types of learned models together.
Momentum-Net for Low-Dose CT Image Reconstruction
Mar 06, 2020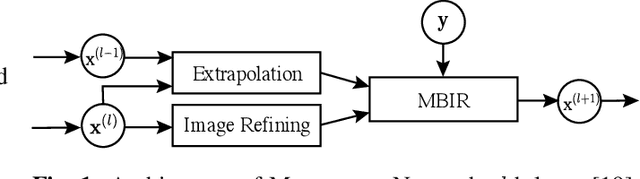

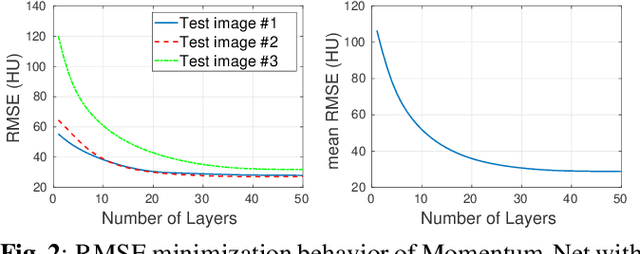
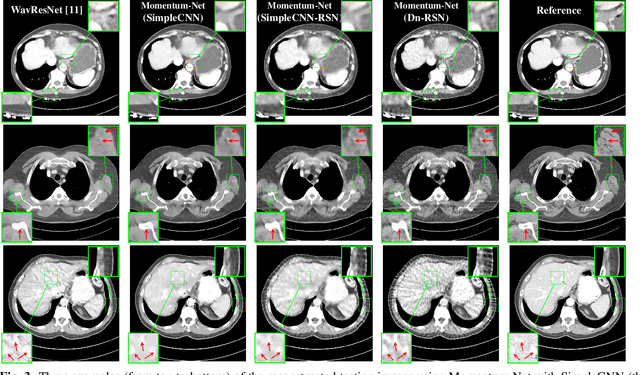
This paper applies the recent fast iterative neural network framework, Momentum-Net, using appropriate models to low-dose X-ray computed tomography (LDCT) image reconstruction. At each layer of the proposed Momentum-Net, the model-based image reconstruction module solves the majorized penalized weighted least-square problem, and the image refining module uses a four-layer convolutional autoencoder. Experimental results with the NIH AAPM-Mayo Clinic Low Dose CT Grand Challenge dataset show that the proposed Momentum-Net architecture significantly improves image reconstruction accuracy, compared to a state-of-the-art noniterative image denoising deep neural network (NN), WavResNet (in LDCT). We also investigated the spectral normalization technique that applies to image refining NN learning to satisfy the nonexpansive NN property; however, experimental results show that this does not improve the image reconstruction performance of Momentum-Net.
SUPER Learning: A Supervised-Unsupervised Framework for Low-Dose CT Image Reconstruction
Oct 26, 2019
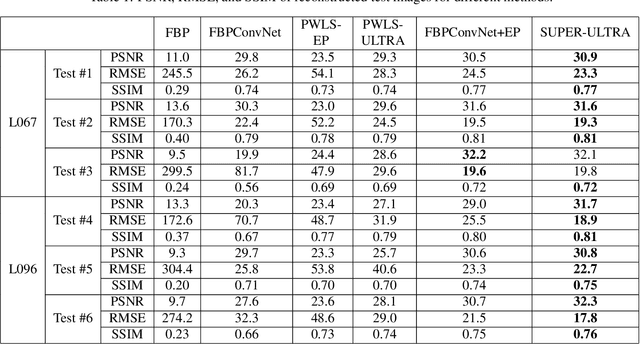
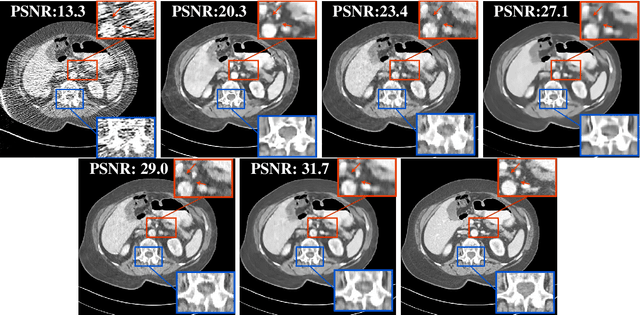
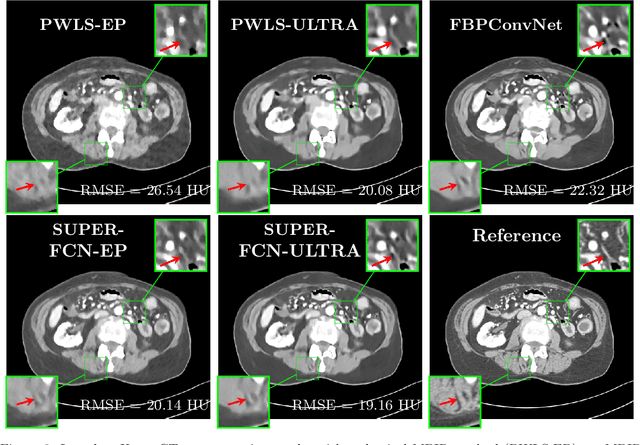
Recent years have witnessed growing interest in machine learning-based models and techniques for low-dose X-ray CT (LDCT) imaging tasks. The methods can typically be categorized into supervised learning methods and unsupervised or model-based learning methods. Supervised learning methods have recently shown success in image restoration tasks. However, they often rely on large training sets. Model-based learning methods such as dictionary or transform learning do not require large or paired training sets and often have good generalization properties, since they learn general properties of CT image sets. Recent works have shown the promising reconstruction performance of methods such as PWLS-ULTRA that rely on clustering the underlying (reconstructed) image patches into a learned union of transforms. In this paper, we propose a new Supervised-UnsuPERvised (SUPER) reconstruction framework for LDCT image reconstruction that combines the benefits of supervised learning methods and (unsupervised) transform learning-based methods such as PWLS-ULTRA that involve highly image-adaptive clustering. The SUPER model consists of several layers, each of which includes a deep network learned in a supervised manner and an unsupervised iterative method that involves image-adaptive components. The SUPER reconstruction algorithms are learned in a greedy manner from training data. The proposed SUPER learning methods dramatically outperform both the constituent supervised learning-based networks and iterative algorithms for LDCT, and use much fewer iterations in the iterative reconstruction modules.